
Configure Tencent Cloud Knowledge Engine Atomic Capability
Tencent Cloud Knowledge Engine (LKE) is an enterprise-level AI service platform launched by Tencent Cloud, providing API access services for the DeepSeek-V3 series models. It supports advanced technologies such as ultra-large-scale parameters (685B), hybrid inference, and sparse attention, suitable for complex reasoning, code generation, long text processing, and other scenarios.
1. Enable Knowledge Engine Service and Get API Key
1.1 Access Knowledge Engine Console
Visit the Tencent Cloud Knowledge Engine Atomic Capability console and log in: https://console.cloud.tencent.com/lke
1.2 Enable Agent Development Platform
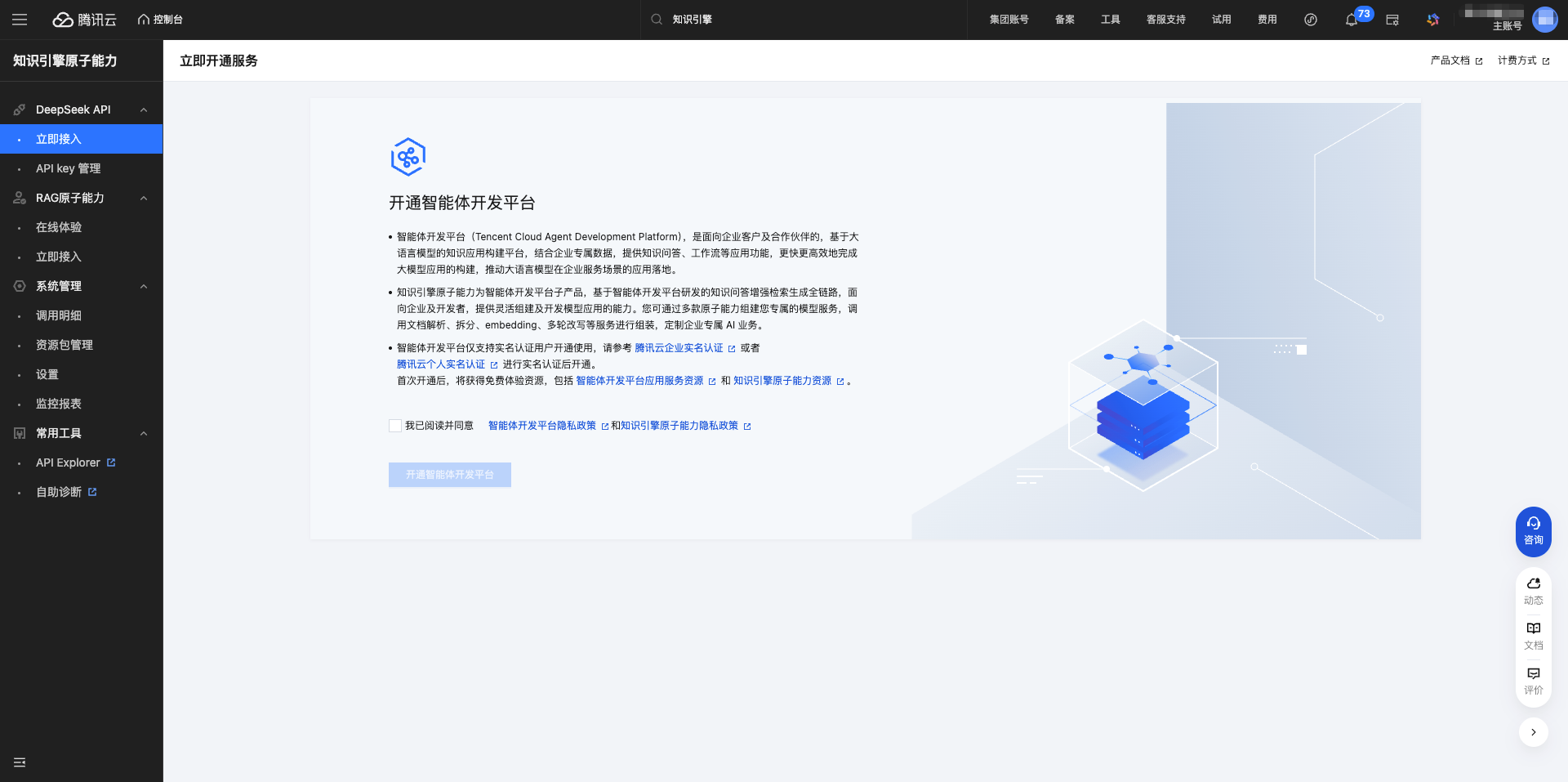
After logging in, click DeepSeek API → Access Now in the left menu to enter the service activation page.
Click the Enable Agent Development Platform button.
1.3 Enter API KEY Management
After the service is enabled, click API KEY Management in the left menu.
1.4 Create API Key
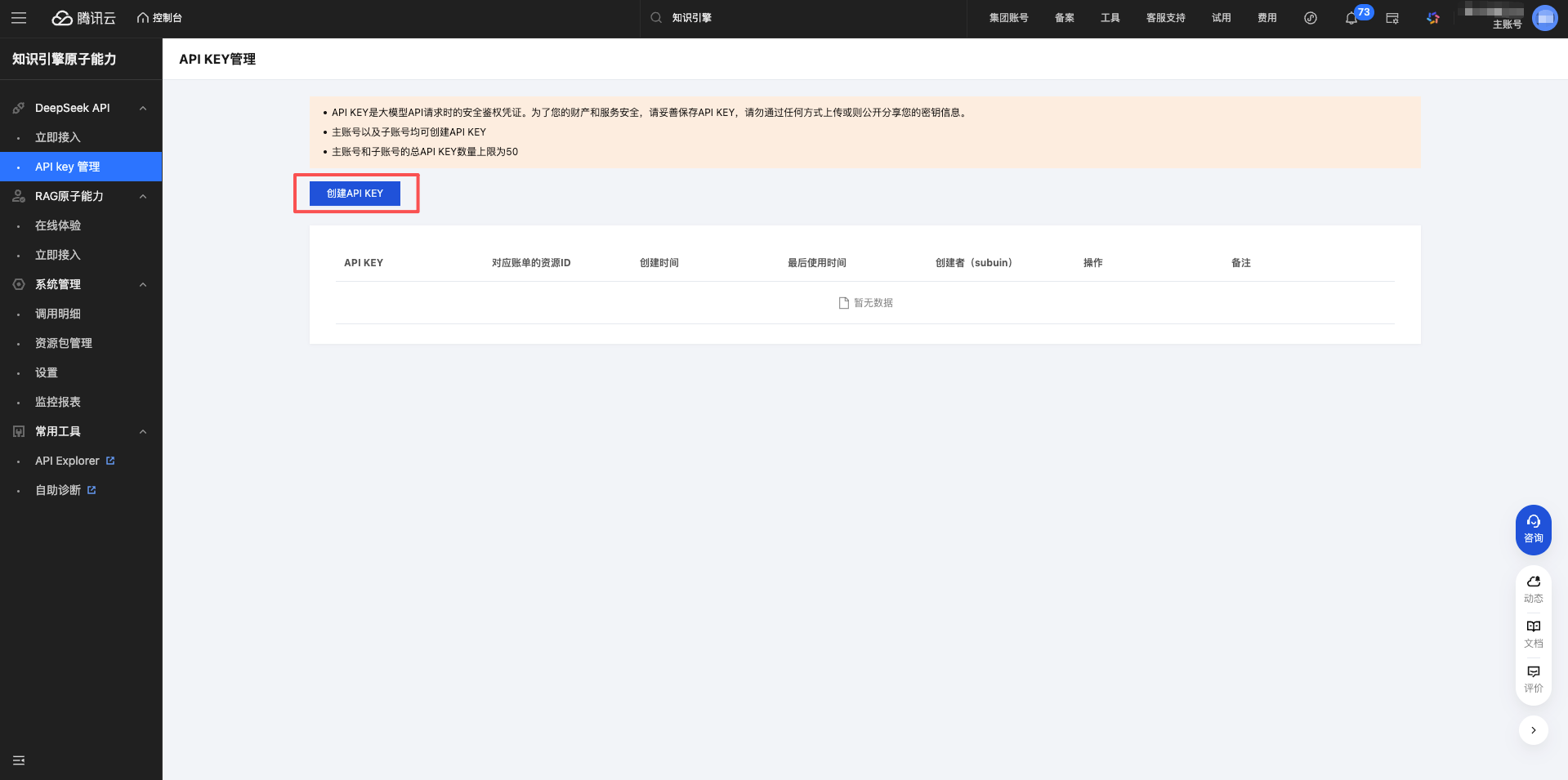
Click the Create API KEY button.
1.5 Copy API Key
After successful creation, the system will display the API Key.
Important: Please copy and save it immediately. The API Key starts with sk-.
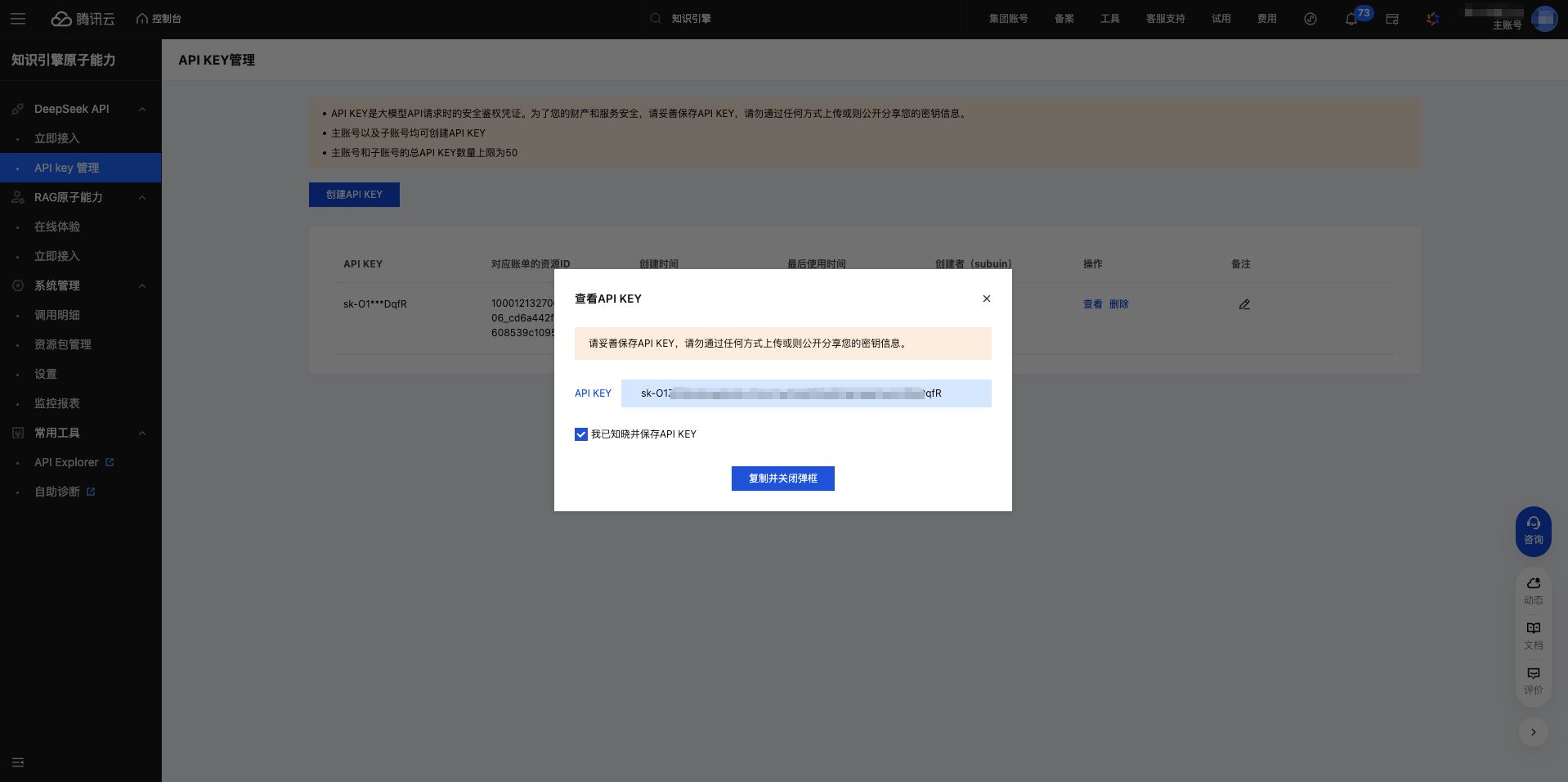
Click the copy button and the API Key is copied to the clipboard.
2. Configure Tencent Cloud Knowledge Engine Model in CueMate
2.1 Enter Model Settings Page
After logging into CueMate, click Model Settings in the dropdown menu in the upper right corner.
2.2 Add New Model
Click the Add Model button in the upper right corner.

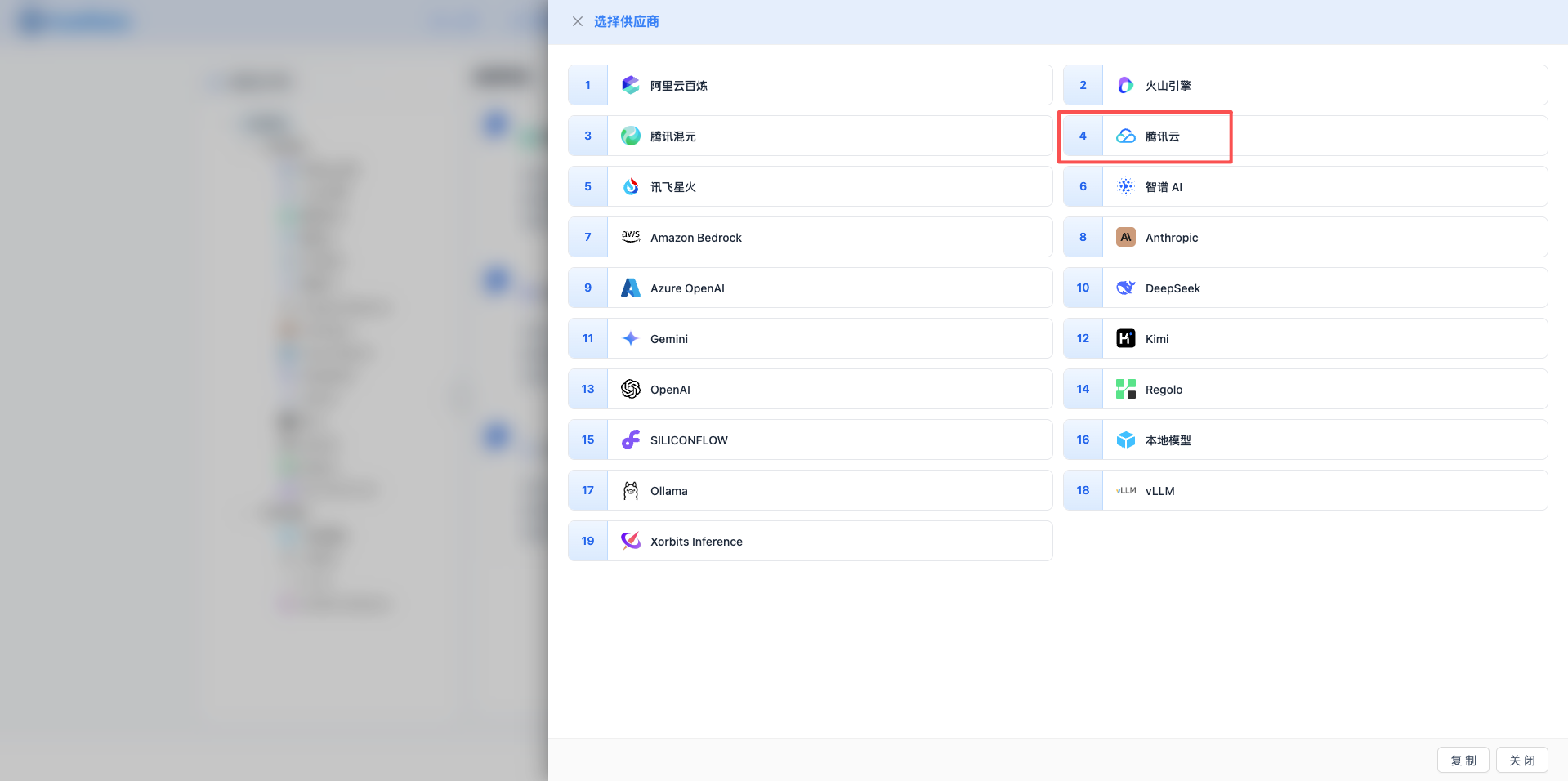
2.3 Select Tencent Cloud Knowledge Engine Provider
In the pop-up dialog:
- Provider Type: Select Tencent Cloud Knowledge Engine
- Click to automatically proceed to the next step
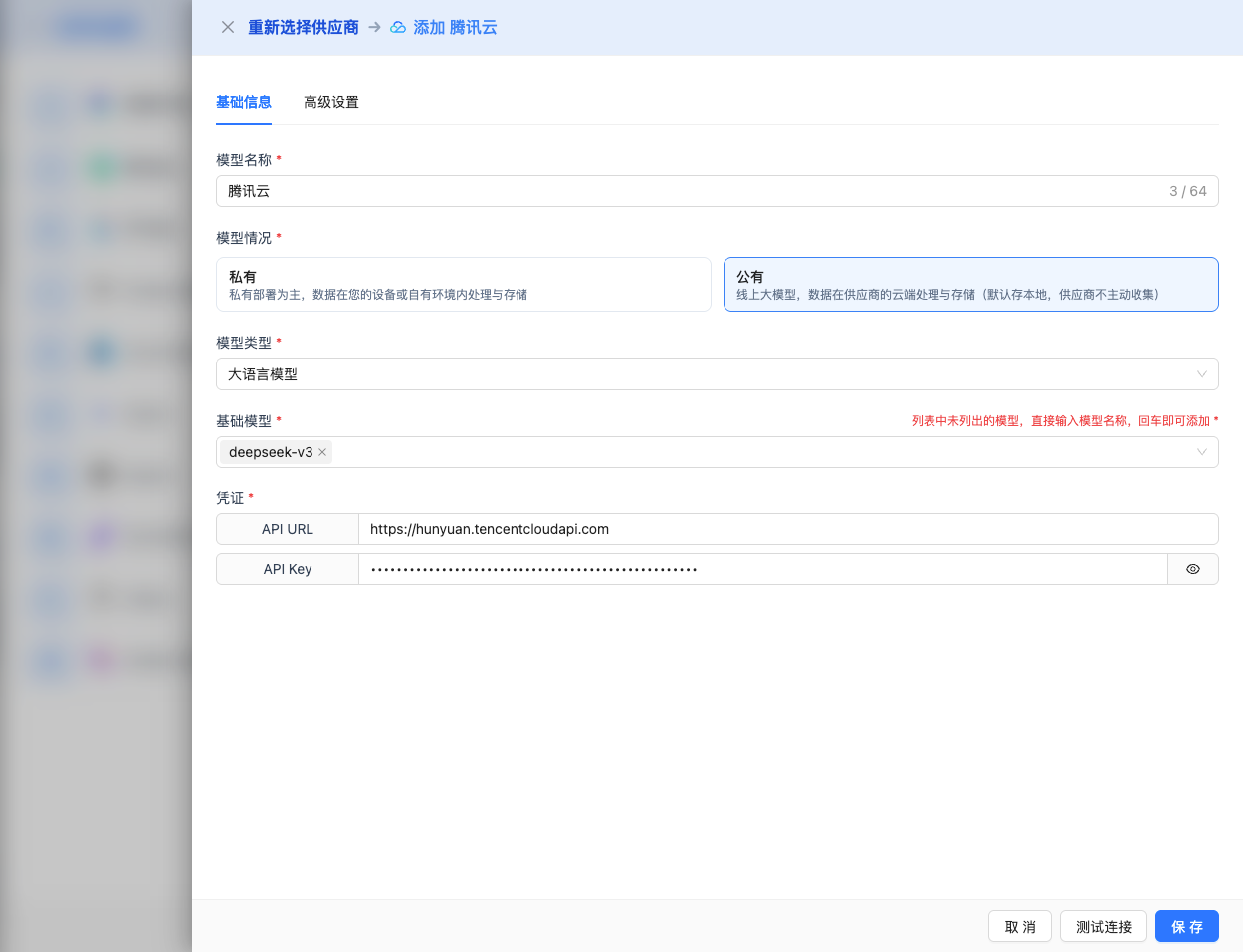
2.4 Fill in Configuration Information
Fill in the following information on the configuration page:
Basic Configuration
- Model Name: Give this model configuration a name (e.g., DeepSeek-V3.1)
- API URL: Keep the default
https://api.lkeap.cloud.tencent.com/v1(OpenAI compatible format) - API Key: Paste the API Key you just copied
- Model Version: Select the model ID to use, commonly used models include:
deepseek-v3.1: 685B parameters, max output 32K, hybrid inference, suitable for complex tasksdeepseek-v3.1-terminus: 685B parameters, max output 32K, optimized language consistencydeepseek-v3.2-exp: 685B parameters, max output 64K reasoning, sparse attention mechanismdeepseek-r1-0528: 671B parameters, max output 16K, enhanced code generation and long text processingdeepseek-r1: 671B parameters, max output 16K, reasoning model, suitable for mathematics and complex logicdeepseek-v3-0324: 671B parameters, max output 16K, 128K context, strong programming capabilitiesdeepseek-v3: 671B parameters, max output 16K, 64K context, general knowledge and mathematical reasoning
Advanced Configuration (Optional)
Expand the Advanced Configuration panel to adjust the following parameters:
CueMate Interface Adjustable Parameters:
Temperature: Controls output randomness
- Range: 0-2
- Recommended Value: 0.7
- Effect: Higher values produce more random and creative output, lower values produce more stable and conservative output
- Usage Recommendations:
- Creative writing/brainstorming: 1.0-1.5
- General conversation/Q&A: 0.7-0.9
- Code generation/precise tasks: 0.3-0.5
Max Tokens: Limits the maximum output length
- Range: 256 - 64000 (depending on the model)
- Recommended Value: 8192
- Effect: Controls the maximum number of tokens in a single model response
- Model Limits:
- deepseek-v3.1/v3.1-terminus: max 32K tokens
- deepseek-v3.2-exp: max 64K tokens (reasoning mode)
- deepseek-r1/r1-0528: max 16K tokens
- deepseek-v3/v3-0324: max 16K tokens
- Usage Recommendations:
- Short Q&A: 1024-2048
- General conversation: 4096-8192
- Long text generation: 16384-32768
- Ultra-long reasoning: 65536 (v3.2-exp only)
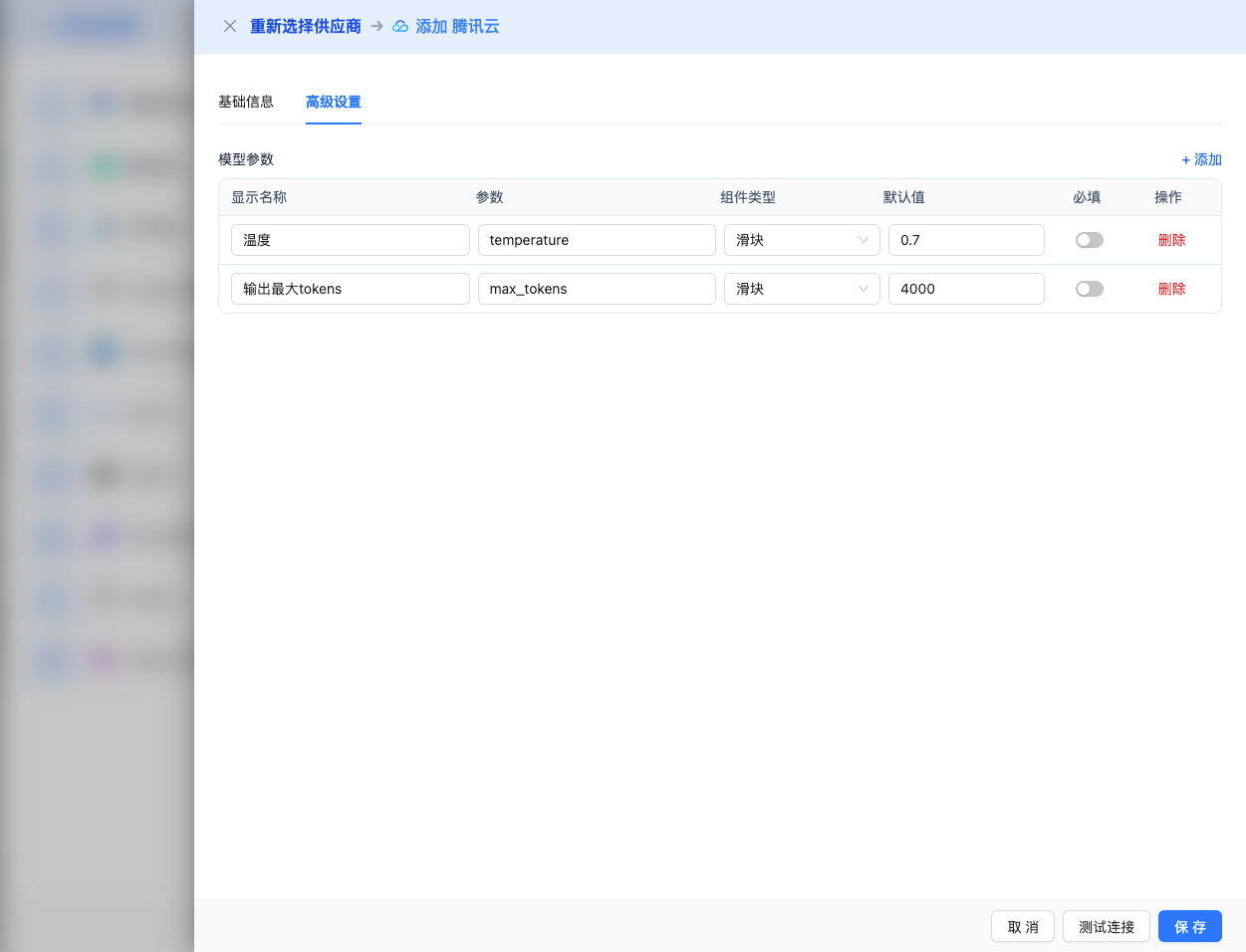
Other Advanced Parameters Supported by Tencent Cloud Knowledge Engine API:
While the CueMate interface only provides temperature and max_tokens adjustments, if you call Tencent Cloud Knowledge Engine directly via API, you can also use the following advanced parameters (uses OpenAI-compatible API format):
top_p (nucleus sampling)
- Range: 0-1
- Default Value: 1
- Effect: Samples from the smallest candidate set with cumulative probability of p
- Relationship with temperature: Usually only adjust one of them
- Usage Recommendations:
- Maintain diversity while avoiding nonsense: 0.9-0.95
- More conservative output: 0.7-0.8
frequency_penalty
- Range: -2.0 to 2.0
- Default Value: 0
- Effect: Reduces the probability of repeating the same words (based on frequency)
- Usage Recommendations:
- Reduce repetition: 0.3-0.8
- Allow repetition: 0 (default)
presence_penalty
- Range: -2.0 to 2.0
- Default Value: 0
- Effect: Reduces the probability of words that have already appeared appearing again (based on presence)
- Usage Recommendations:
- Encourage new topics: 0.3-0.8
- Allow topic repetition: 0 (default)
stop
- Type: String or array
- Default Value: null
- Effect: Stops generation when the specified string appears in the content
- Example:
["###", "User:", "\n\n"] - Use Cases:
- Structured output: Use delimiters to control format
- Dialogue systems: Prevent the model from speaking for the user
stream
- Type: Boolean
- Default Value: false
- Effect: Enable SSE streaming return, generating and returning incrementally
- In CueMate: Automatically handled, no manual setting required
| No. | Scenario | temperature | max_tokens | top_p | frequency_penalty | presence_penalty |
|---|---|---|---|---|---|---|
| 1 | Creative Writing | 1.0-1.2 | 4096-8192 | 0.95 | 0.5 | 0.5 |
| 2 | Code Generation | 0.2-0.5 | 2048-4096 | 0.9 | 0.0 | 0.0 |
| 3 | Q&A System | 0.7 | 1024-2048 | 0.9 | 0.0 | 0.0 |
| 4 | Summarization | 0.3-0.5 | 512-1024 | 0.9 | 0.0 | 0.0 |
| 5 | Complex Reasoning | 0.7 | 32768-65536 | 0.9 | 0.0 | 0.0 |
2.5 Test Connection
After filling in the configuration, click the Test Connection button to verify if the configuration is correct.
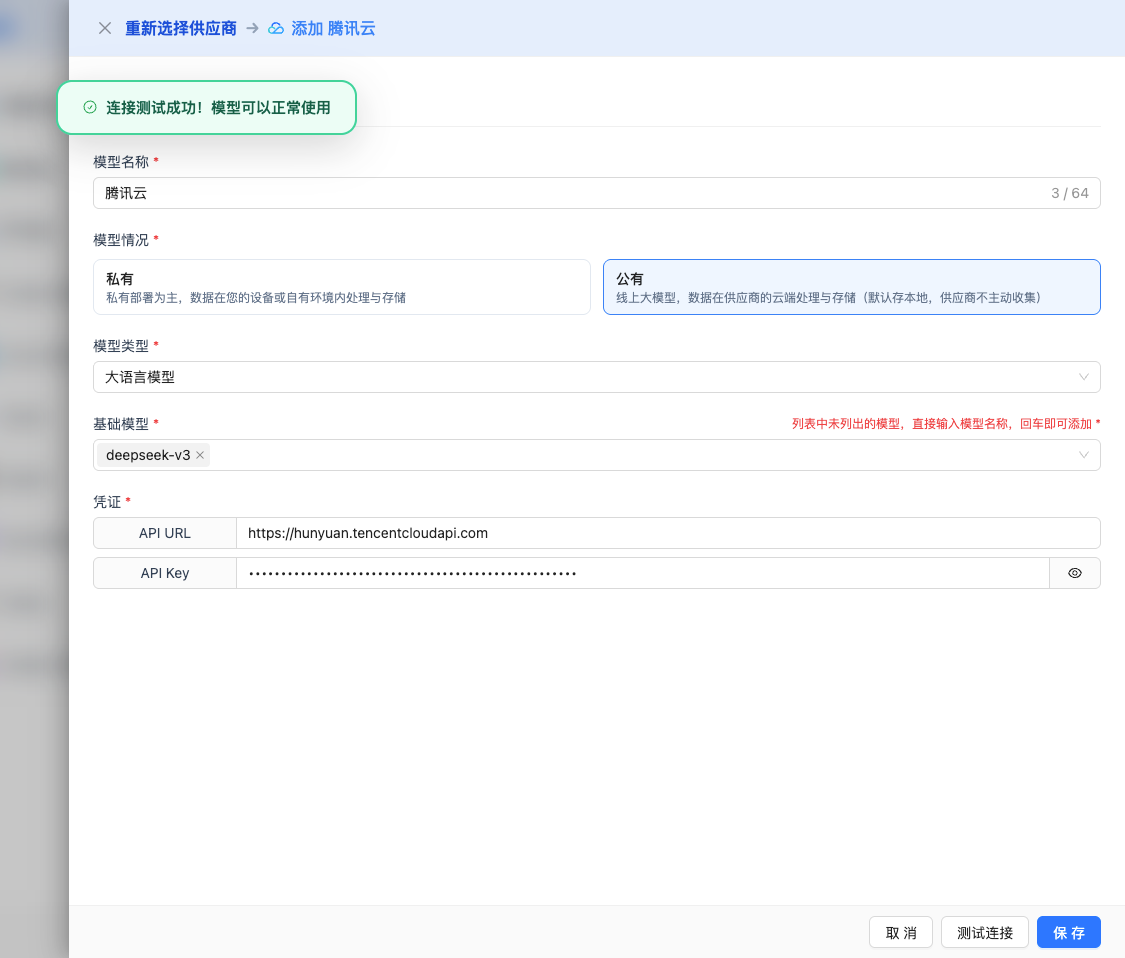
If the configuration is correct, a success message will be displayed with a sample model response.
If the configuration is incorrect, an error log will be displayed, and you can view detailed error information through log management.
2.6 Save Configuration
After successful testing, click the Save button to complete the model configuration.
3. Use the Model
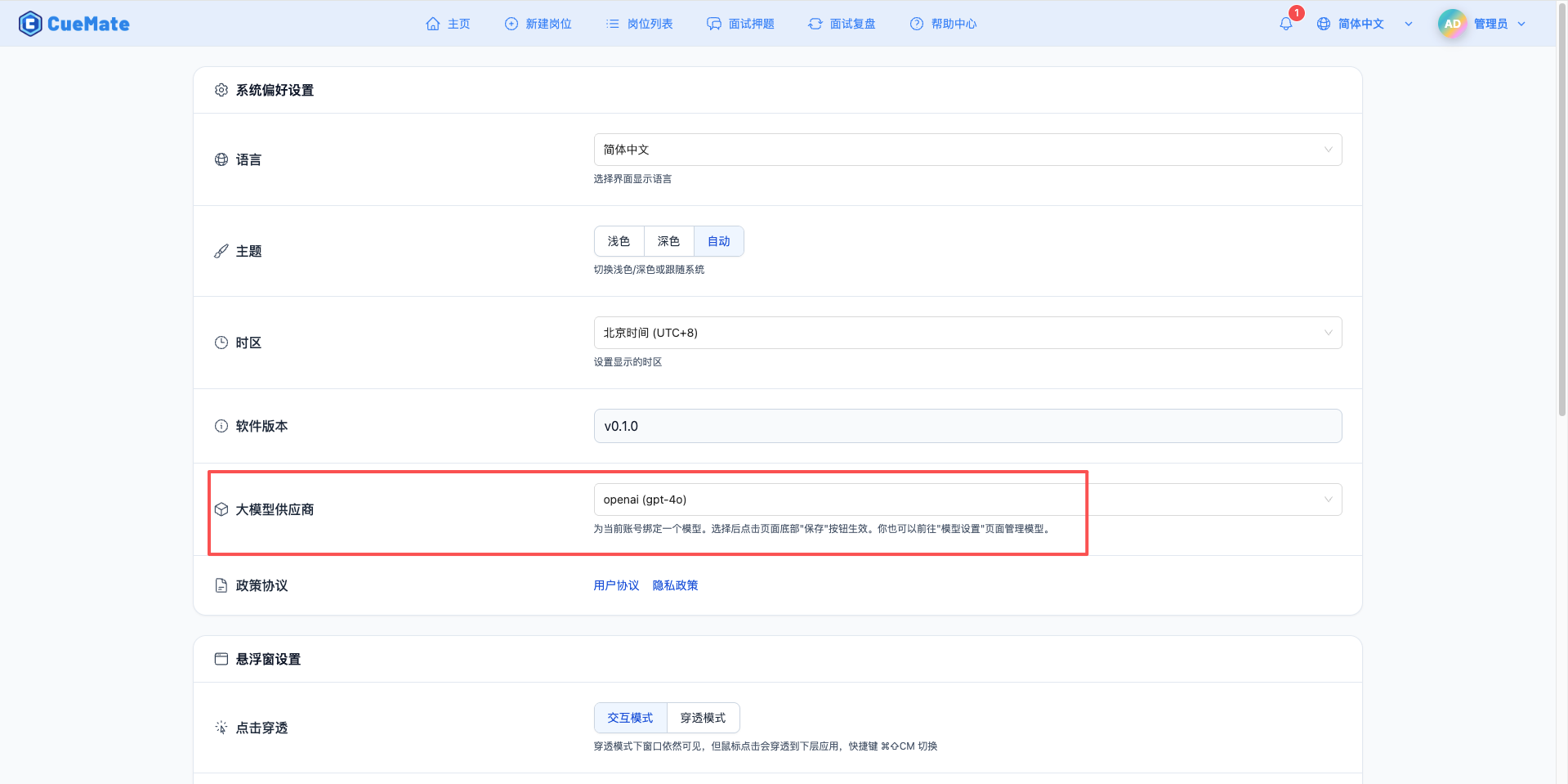
Through the dropdown menu in the upper right corner, enter the system settings interface and select the model configuration you want to use in the large model provider section.
After configuration, you can select to use this model in interview training, question generation, and other functions, or of course, you can individually select the model configuration for each interview in the interview options.
4. Supported Model List
4.1 685B Parameter Models (Latest)
| No. | Model Name | Model ID | Max Output | Use Cases |
|---|---|---|---|---|
| 1 | DeepSeek-V3.1 | deepseek-v3.1 | 32K tokens | Hybrid inference, Agent capabilities, complex tasks |
| 2 | DeepSeek-V3.1-Terminus | deepseek-v3.1-terminus | 32K tokens | Optimized language consistency, Agent stability |
| 3 | DeepSeek-V3.2-Exp | deepseek-v3.2-exp | 64K tokens (reasoning) | Sparse attention, long text optimization |
4.2 671B Parameter Models
| No. | Model Name | Model ID | Max Output | Use Cases |
|---|---|---|---|---|
| 1 | DeepSeek-R1-0528 | deepseek-r1-0528 | 16K tokens | Enhanced code generation, long text processing, complex reasoning |
| 2 | DeepSeek-R1 | deepseek-r1 | 16K tokens | Mathematics, code, complex logical reasoning tasks |
| 3 | DeepSeek-V3-0324 | deepseek-v3-0324 | 16K tokens | Programming and technical capabilities, 128K context |
| 4 | DeepSeek-V3 | deepseek-v3 | 16K tokens | General knowledge, mathematical reasoning, 64K context |
5. Common Issues
5.1 Invalid API Key
Symptom: API Key error message when testing connection
Solution:
- Check if the API Key starts with
sk- - Confirm the API Key is completely copied
- Check if the account has available quota
- Verify the API Key has not expired or been disabled
5.2 Request Timeout
Symptom: No response for a long time when testing connection or using
Solution:
- Check if the network connection is normal
- Confirm the API URL address is correct:
https://api.lkeap.cloud.tencent.com/v1 - Check firewall settings
5.3 Model Not Available
Symptom: Error message indicating model service is not available
Solution:
- Confirm the selected model ID is correct
- Check if the account has enabled the Knowledge Engine Atomic Capability service
- Contact Tencent Cloud customer service to confirm service status
5.4 Quota Limit
Symptom: Request quota exceeded error
Solution:
- Log in to the Tencent Cloud console to check quota usage
- Apply for increased quota limit (API frequency limit is 20 requests/second)
- Optimize usage frequency