
Configure OpenAI
OpenAI is a globally leading artificial intelligence research company, providing advanced large language model services including GPT-5, GPT-4.1, GPT-4o and more. Through the OpenAI API, developers can access cutting-edge AI capabilities supporting complex reasoning, multimodal understanding, code generation, and various other application scenarios.
1. Get OpenAI API Key
1.1 Access the AI Platform
Visit the AI official website and log in: https://platform.openai.com/
1.2 Go to API Keys Page
Click API keys in the left menu to enter the key management page.
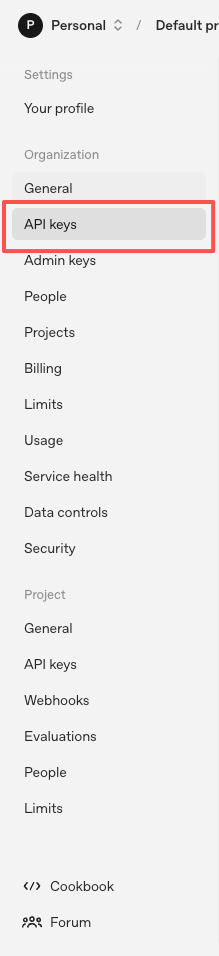
1.3 Create a New API Key
Click the Create new secret key button in the upper right corner.
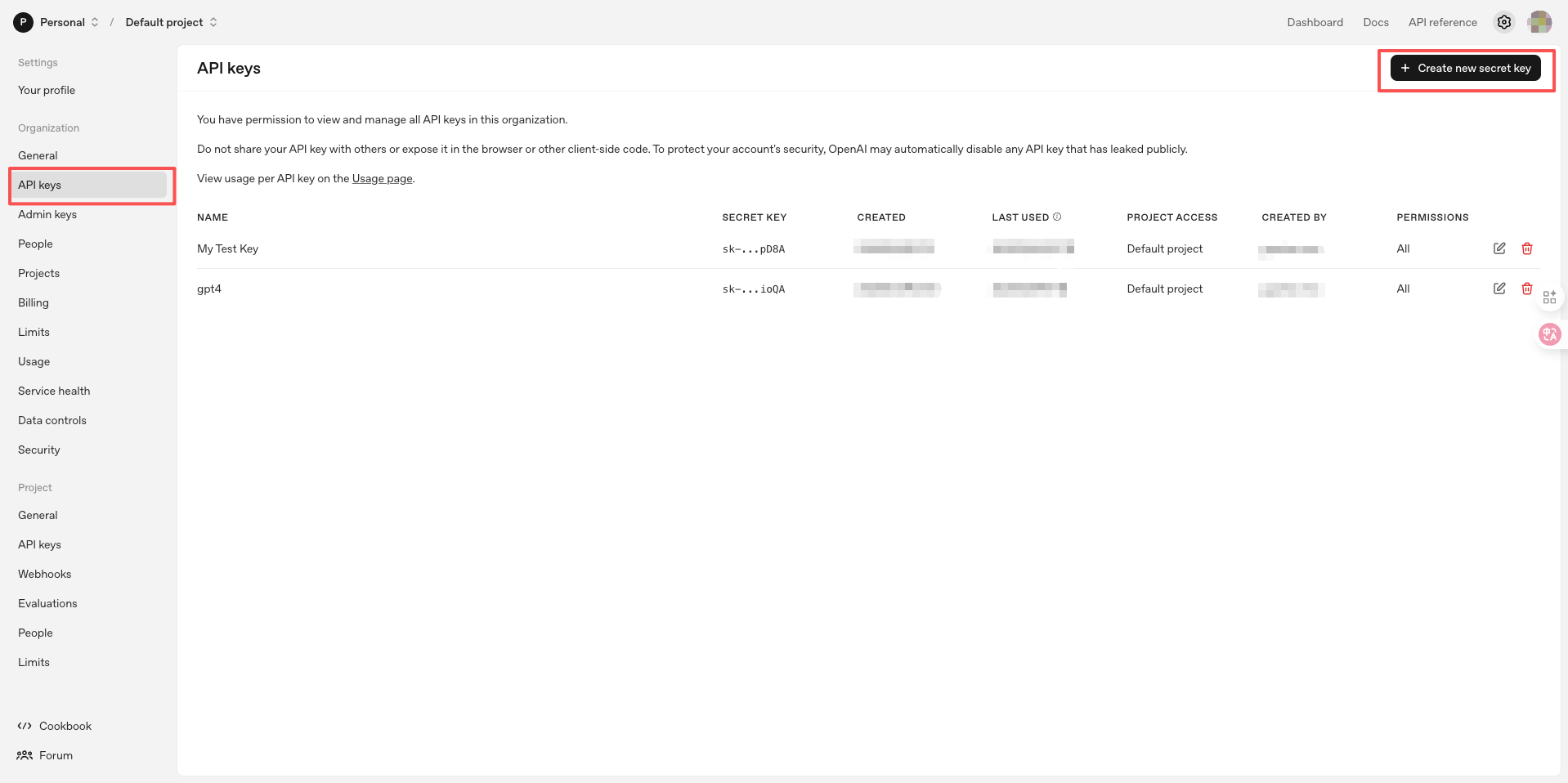
1.4 Set API Key Name
In the popup dialog:
- Enter a name for the API Key (e.g., CueMate)
- Click the Create secret key button
1.5 Copy API Key
After successful creation, the system will display the API Key.
WARNING
Important Notice:
- This is the only time you can see the complete API Key
- Please copy and save it securely immediately
- Do not share the API Key with others or commit it to code repositories
- If leaked, immediately revoke the Key on the OpenAI platform
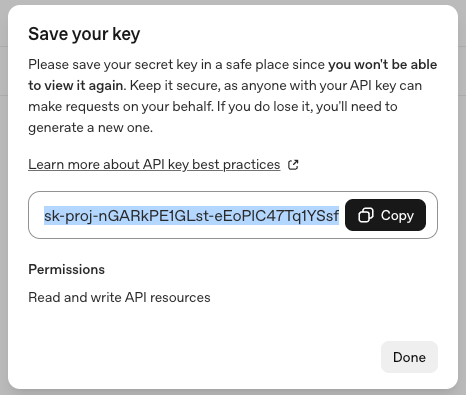
Click the copy button, and the API Key will be copied to your clipboard.
2. Configure OpenAI Model in CueMate
2.1 Go to Model Settings Page
After logging into the CueMate system, click Model Settings in the dropdown menu in the upper right corner.
2.2 Add New Model
Click the Add Model button in the upper right corner.

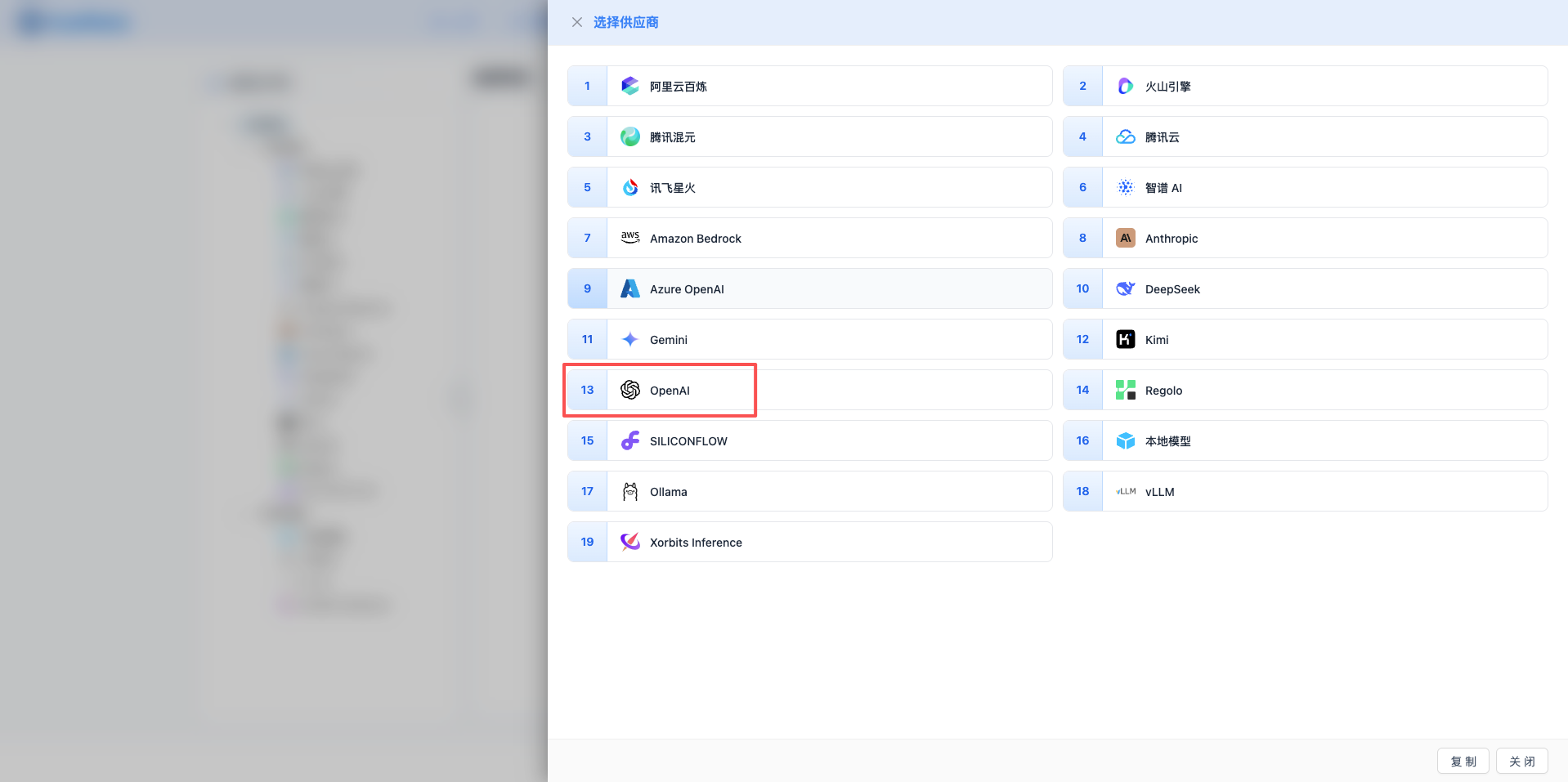
2.3 Select OpenAI Provider
In the popup dialog:
- Provider Type: Select OpenAI
- Click to automatically proceed to the next step
2.4 Fill in Configuration Information
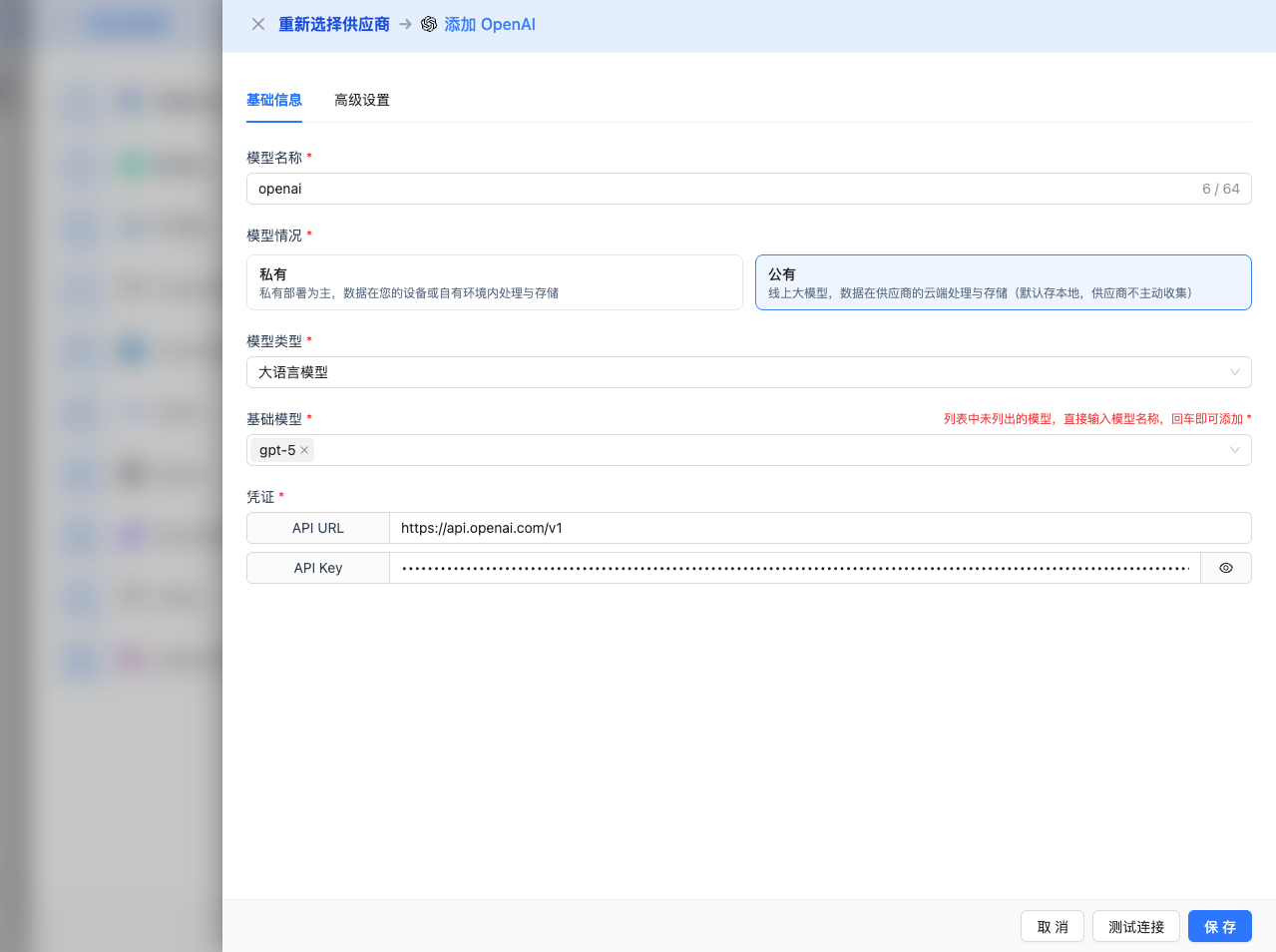
Fill in the following information on the configuration page:
Basic Configuration
- Model Name: Give this model configuration a name (e.g., GPT-4 Production)
- API Key: Paste the OpenAI API Key you just copied
- Base URL: Keep the default
https://api.openai.com/v1(if using a proxy, enter the proxy address) - Model Version: Select the model to use
gpt-5: Latest flagship model, strongest reasoning capabilitygpt-5-mini: Lightweight GPT-5, fast speedgpt-4.1: GPT-4 upgrade, improved performancegpt-4o: Multimodal model, supports image understandinggpt-4o-mini: Lightweight multimodal, high valuegpt-4-turbo: High-performance versiongpt-3.5-turbo: Affordable, fast response
Advanced Configuration (Optional)
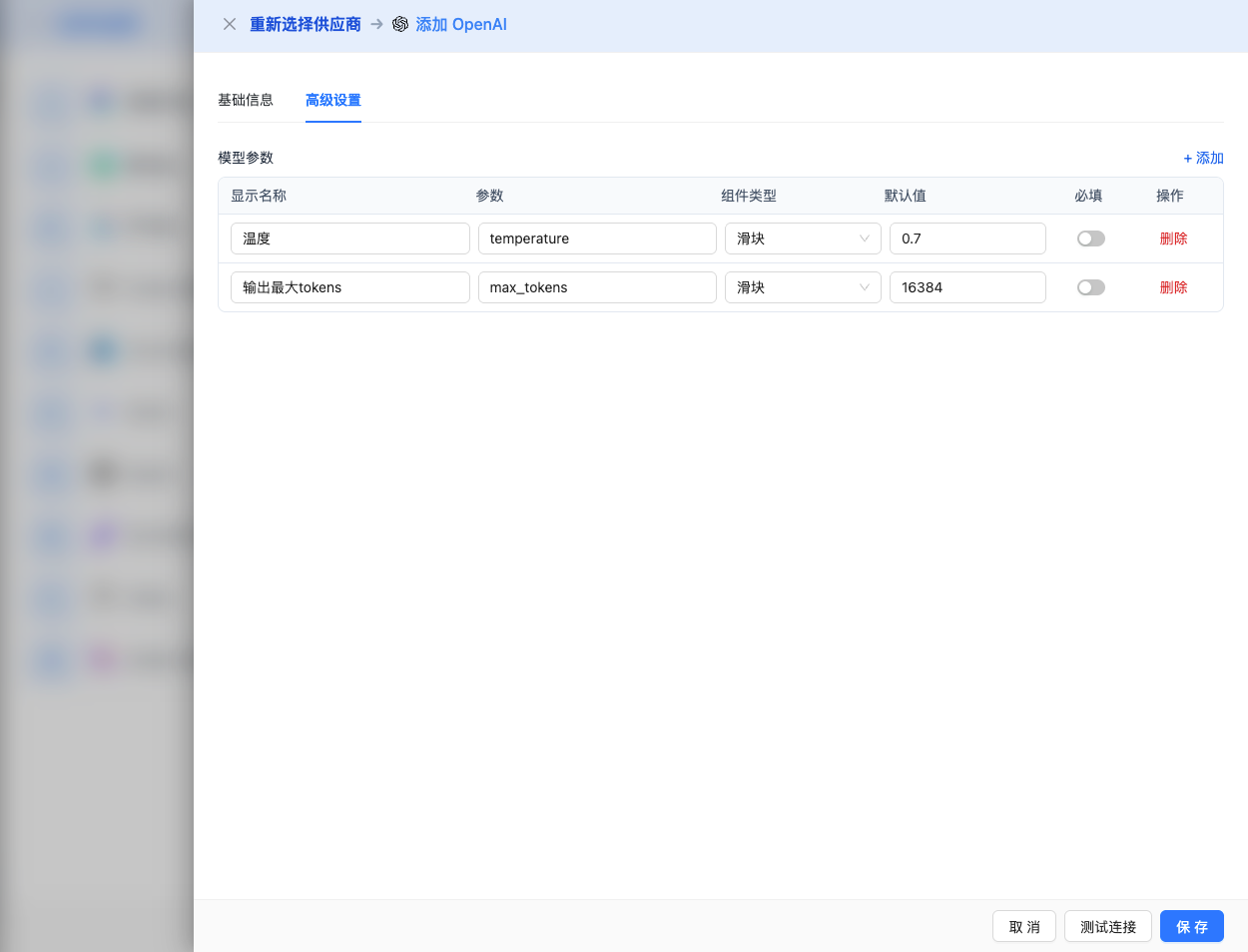
Expand the Advanced Configuration panel to adjust the following parameters:
Parameters adjustable in CueMate interface:
Temperature: Controls output randomness
- Range: 0-2
- Recommended Value: 0.7
- Function: Higher values produce more random and creative output, lower values produce more stable and conservative output
- Usage Suggestions:
- Creative writing/brainstorming: 1.0-1.5
- Regular conversation/Q&A: 0.7-0.9
- Code generation/precise tasks: 0.3-0.5
Max Tokens: Limits single output length
- Range: 256 - 16384 (depending on model)
- Recommended Value: 8192
- Function: Controls the maximum word count per model response
- Model Limits:
- GPT-5 series, GPT-4.1, GPT-4o series: Max 16K tokens
- GPT-4: Max 8K tokens
- GPT-4 Turbo, GPT-3.5 Turbo: Max 4K tokens
- Usage Suggestions:
- Brief Q&A: 1024-2048
- Regular conversation: 4096-8192
- Long text generation: 16384 (supported models only)
Other advanced parameters supported by OpenAI API:
While the CueMate interface only provides temperature and max_tokens adjustments, if you call OpenAI directly via API, you can also use the following advanced parameters:
top_p (nucleus sampling)
- Range: 0-1
- Default: 1
- Function: Samples from the smallest candidate set whose cumulative probability reaches p
- Relationship with temperature: Usually adjust only one of them
- Usage Suggestions:
- Maintain diversity but avoid extremes: 0.9-0.95
- More conservative output: 0.7-0.8
frequency_penalty
- Range: -2.0 to 2.0
- Default: 0
- Function: Reduces probability of repeating the same words (based on word frequency)
- Usage Suggestions:
- Reduce repetition: 0.3-0.8
- Allow repetition: 0 (default)
- Force diversity: 1.0-2.0
presence_penalty
- Range: -2.0 to 2.0
- Default: 0
- Function: Reduces probability of words that have already appeared (based on whether they appeared)
- Usage Suggestions:
- Encourage new topics: 0.3-0.8
- Allow repeating topics: 0 (default)
stop (stop sequences)
- Type: String or array (max 4 strings)
- Default: null
- Function: Stops when generated content contains specified strings
- Example:
["###", "User:", "\n\n"] - Use Cases:
- Structured output: Use delimiters to control format
- Dialogue systems: Prevent model from speaking for user
logit_bias (token bias)
- Type: Dictionary mapping token ID to bias value
- Range: -100 to 100
- Function: Adjusts probability of specific tokens appearing
- Use Cases:
- Prohibit specific words: Set to -100
- Encourage specific words: Set to positive value
stream (streaming output)
- Type: Boolean
- Default: false
- Function: Enables SSE streaming return, returns as it generates
- In CueMate: Automatically handled, no manual setting needed
seed (random seed)
- Type: Integer
- Default: null
- Function: Fixes random seed, same input produces same output
- Use Cases:
- Reproducible testing
- Comparative experiments
- Note: Best effort, not guaranteed to be completely consistent
n (generation count)
- Type: Integer
- Default: 1
- Range: 1-10
- Function: Generates multiple candidate responses in one request
- Note: Billing is based on generation count
user (user identifier)
- Type: String
- Function: Identifies end user, helps OpenAI monitor abuse
- Suggestion: Recommended to set in production environments
| Scenario | temperature | max_tokens | top_p | frequency_penalty | presence_penalty |
|---|---|---|---|---|---|
| Creative Writing | 1.0-1.2 | 4096-8192 | 0.95 | 0.5 | 0.5 |
| Code Generation | 0.2-0.5 | 2048-4096 | 0.9 | 0.0 | 0.0 |
| Q&A System | 0.7 | 1024-2048 | 0.9 | 0.0 | 0.0 |
| Summarization | 0.3-0.5 | 512-1024 | 0.9 | 0.0 | 0.0 |
| Brainstorming | 1.2-1.5 | 2048-4096 | 0.95 | 0.8 | 0.8 |
2.5 Test Connection
After filling in the configuration, click the Test Connection button to verify if the configuration is correct.
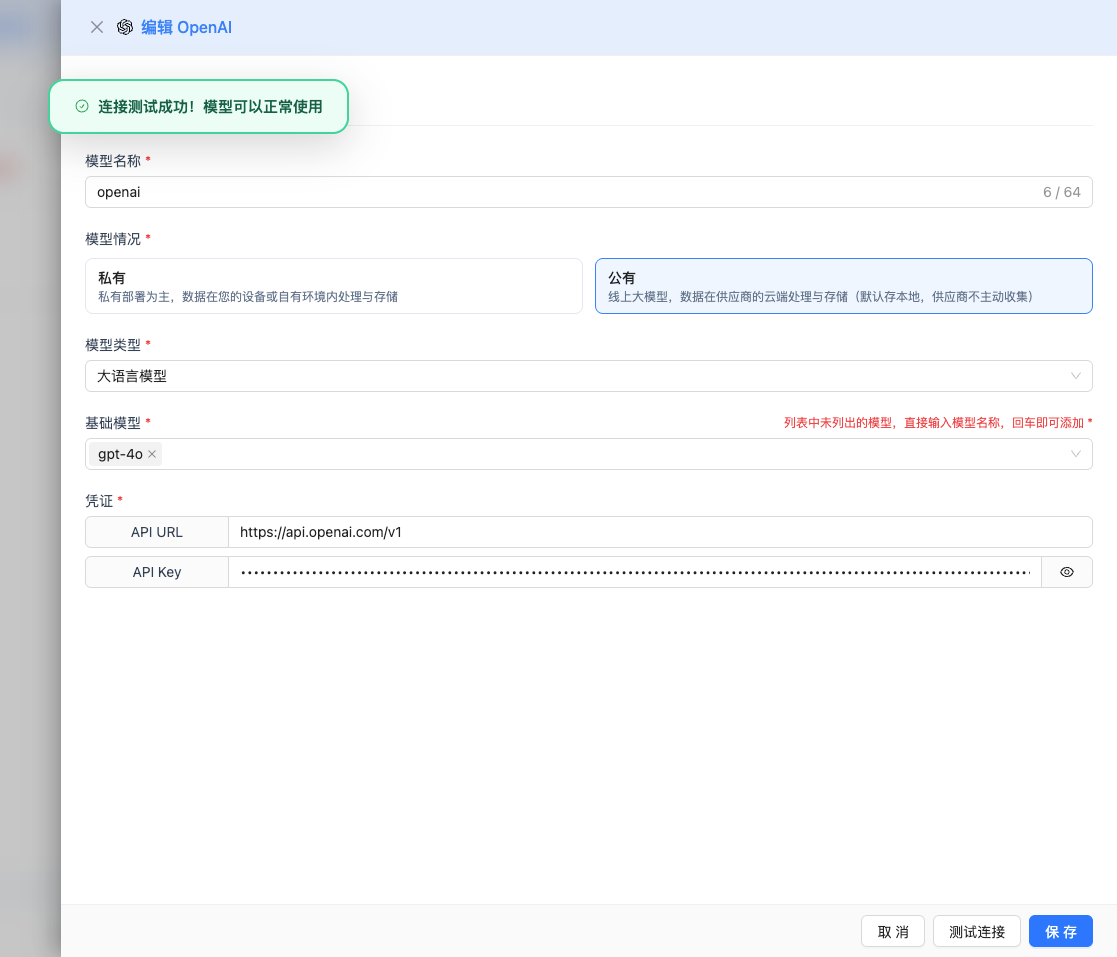
If the configuration is correct, a success message will be displayed along with a sample response from the model.
If the configuration is incorrect, an error log will be displayed, and you can view specific error information through log management.
2.6 Save Configuration
After successful testing, click the Save button to complete the model configuration.
3. Use the Model
Go to the system settings page through the dropdown menu in the upper right corner, and select the model configuration you want to use in the LLM provider section.
After configuration, you can select this model in features like interview training and question generation. You can also select this model configuration for a specific interview in the interview options.
4. Supported Model List
| No. | Model Name | Model ID | Max Output | Use Case |
|---|---|---|---|---|
| 1 | GPT-5 | gpt-5 | 16K tokens | Latest flagship model, strongest reasoning |
| 2 | GPT-5 Mini | gpt-5-mini | 16K tokens | Lightweight GPT-5, fast |
| 3 | GPT-5 Nano | gpt-5-nano | 16K tokens | Ultra-lightweight, low cost |
| 4 | GPT-4.1 | gpt-4.1 | 16K tokens | GPT-4 upgrade, improved performance |
| 5 | GPT-4o | gpt-4o | 16K tokens | Multimodal, supports image understanding |
| 6 | GPT-4o Mini | gpt-4o-mini | 16K tokens | Lightweight multimodal |
| 7 | GPT-4 Turbo | gpt-4-turbo | 4K tokens | High-performance version |
| 8 | GPT-4 | gpt-4 | 8K tokens | Classic flagship model |
| 9 | GPT-3.5 Turbo | gpt-3.5-turbo | 4K tokens | Affordable, fast response |
5. FAQ
5.1 Invalid API Key
Symptom: "Invalid API Key" or "Incorrect API key provided" error when testing connection
Solutions:
- Check if the API Key was copied completely (no extra spaces)
- Confirm the API Key has not been revoked
- Check if the OpenAI account has available credits
5.2 Request Timeout
Symptom: Long wait time with no response when testing connection or using the model
Solutions:
- Check if network connection is normal
- If in China, try using a proxy or third-party API forwarding service
- Check firewall settings
5.3 Insufficient Quota
Symptom: "You exceeded your current quota" or "Rate limit exceeded" error
Solutions:
- Log in to OpenAI platform to check account balance
- Top up or upgrade account plan
- Check API Key usage limits