
Configure Regolo
Regolo is a local model service that integrates API interfaces from major global large language model providers. It provides unified access, flexible billing models, and high availability guarantees, simplifying multi-model setup and switching.
1. Get Regolo API Key
1.1 Access Regolo Platform
Visit the Regolo AI platform and register/login: https://api.regolo.ai/

1.2 Enter Virtual Keys Management Page
After logging in, click Virtual Keys in the left menu to enter the API key management page.
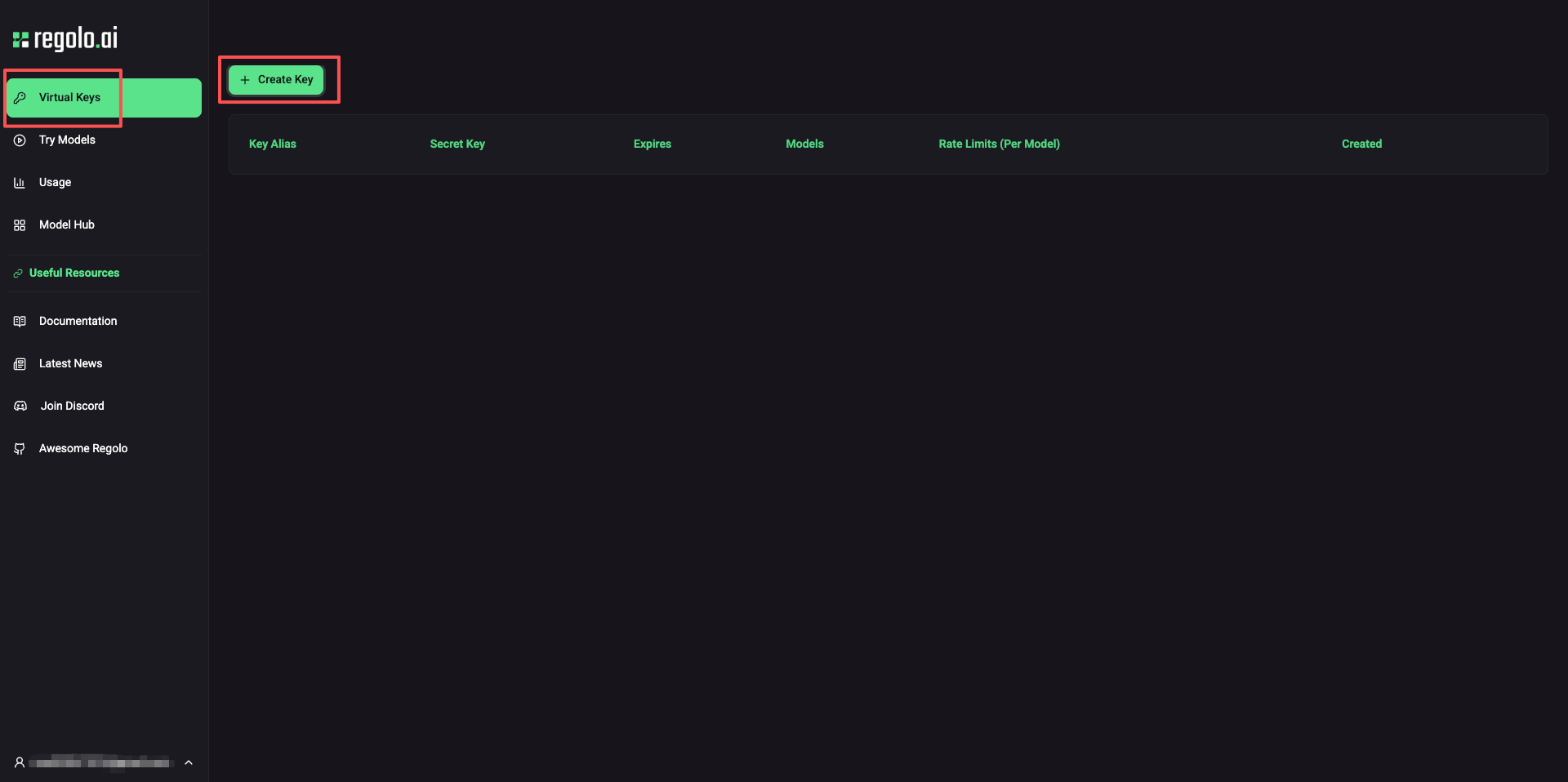
1.3 Create New API Key
Click the Create Key button in the upper right corner to open the creation dialog.
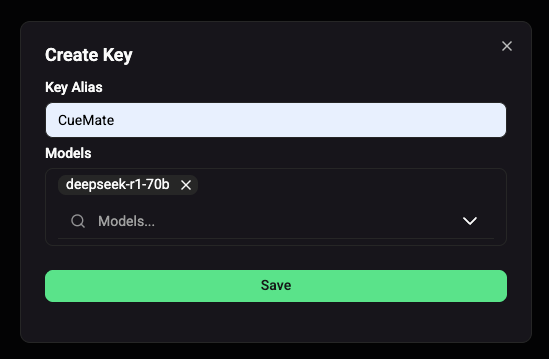
1.4 Configure API Key Information
Configure the following information in the Create Key dialog:
1.4.1 Set Key Alias
Enter an easily identifiable name, such as CueMate.
Naming Recommendations:
- Use project name or purpose as prefix
- Distinguish dev/test/production environments (e.g.,
CueMate-Dev,CueMate-Prod) - Avoid including sensitive information
1.4.2 Select Authorized Models
Click the Models dropdown to select which models this API Key can access:
Available Modes:
- All models: Authorize access to all models (recommended for production)
- Specific models: Only authorize access to specific models (recommended for development/testing)
Model Selection Recommendations:
- Production environment: Select "All models" for flexible switching
- Development environment: Only select models needed for testing to reduce misuse risk
- On-demand authorization: Select corresponding models based on actual business scenarios
Currently Available LLM Models:
deepseek-r1-70b: DeepSeek R1 reasoning model (max 64K tokens)llama-guard3-8b: Llama Guard 3 safety audit modelqwen3-30b: Qwen3 30B general model (max 32K tokens)qwen3-coder-30b: Qwen3 code-specific model (max 256K tokens)mistral-small3.2: Mistral Small 3.2 lightweight model (max 32K tokens)gpt-oss-120b: Open-source GPT 120B large modelLlama-3.3-70B-Instruct: Llama 3.3 latest versionLlama-3.1-8B-Instruct: Llama 3.1 8B cost-effectivemaestrale-chat-v0.4-beta: Regolo original conversational modelQwen3-8B: Qwen3 8B lightweight model (max 32K tokens)gemma-3-27b-it: Google Gemma 3 27B (max 128K tokens)
1.4.3 Set Rate Limits
Click the Edit Limits button to configure rate limits for this API Key:
- RPM (Requests Per Minute): Requests per minute
- TPM (Tokens Per Minute): Tokens per minute
- RPD (Requests Per Day): Requests per day
Rate Limit Recommendations:
- Development/testing: RPM=60, TPM=100000, RPD=10000
- Production environment: Set according to actual business volume to avoid unexpected overages
1.4.4 Complete Creation
After configuration, click the Save button.
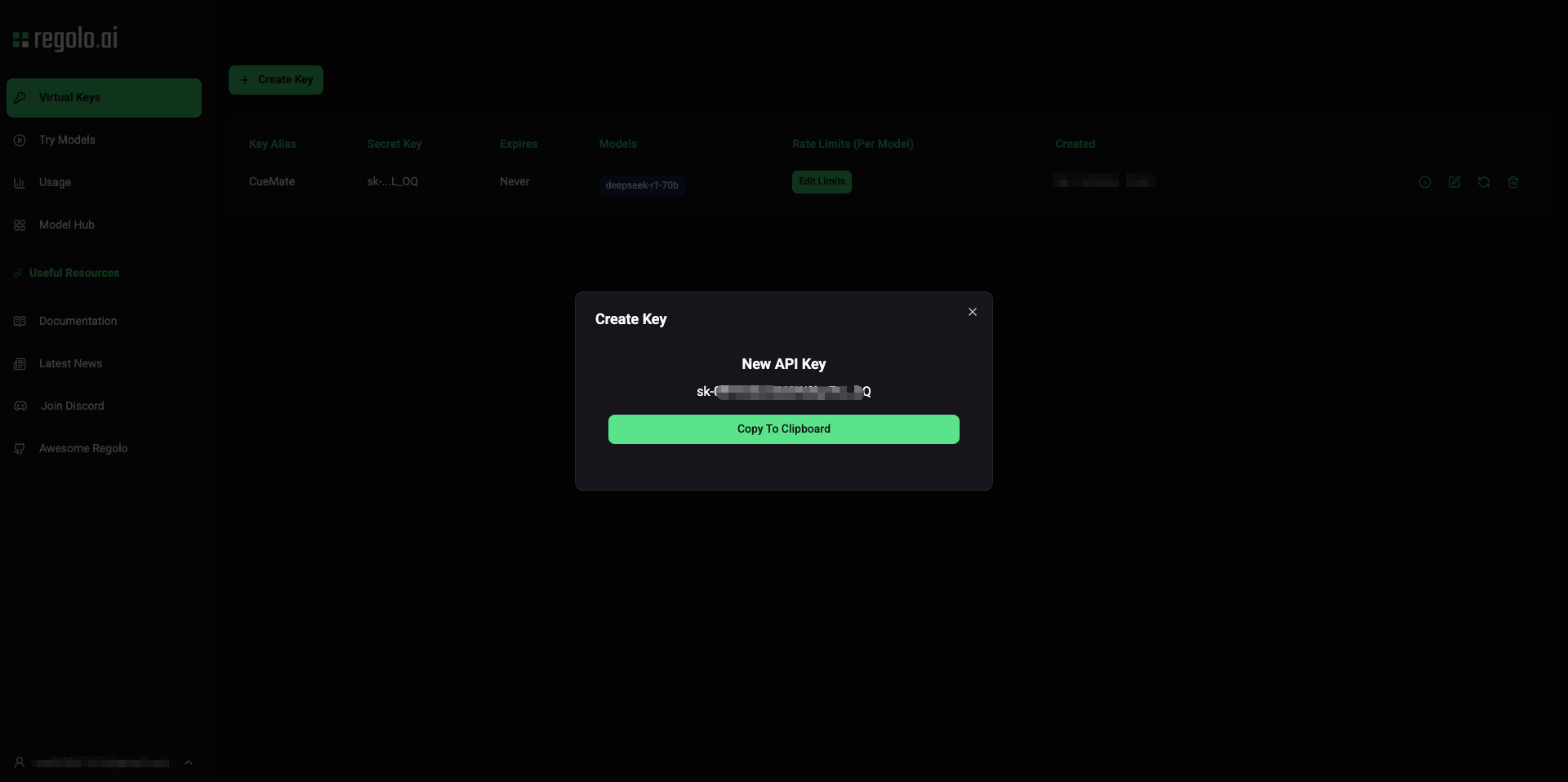
1.5 Save API Key
After successful creation, the system will display the API Key.
Important Reminder:
- The API Key is displayed only once and cannot be viewed again after closing the dialog
- Please copy immediately and save to a secure location (such as a password manager)
- If lost, you need to delete the old Key and create a new one
Recommended Save Methods:
- Click the copy button, API Key is copied to clipboard
- Paste into password manager (such as 1Password, Bitwarden)
- Or save to a secure text file and keep it safe (do not share with others)
1.6 Verify API Key
In the Virtual Keys list, you can see the newly created Key:
- Status: Shows whether the Key is enabled
- Authorized Models: Shows the list of accessible models
- Creation Time: Records the creation date
- Actions: Can edit limits or delete the Key
2. Configure Regolo Model in CueMate
2.1 Enter Model Settings Page
After logging into CueMate, click Model Settings in the dropdown menu in the upper right corner.
2.2 Add New Model
Click the Add Model button in the upper right corner.

2.3 Select Regolo Provider
In the pop-up dialog:
- Provider Type: Select Regolo
- Click to automatically proceed to the next step
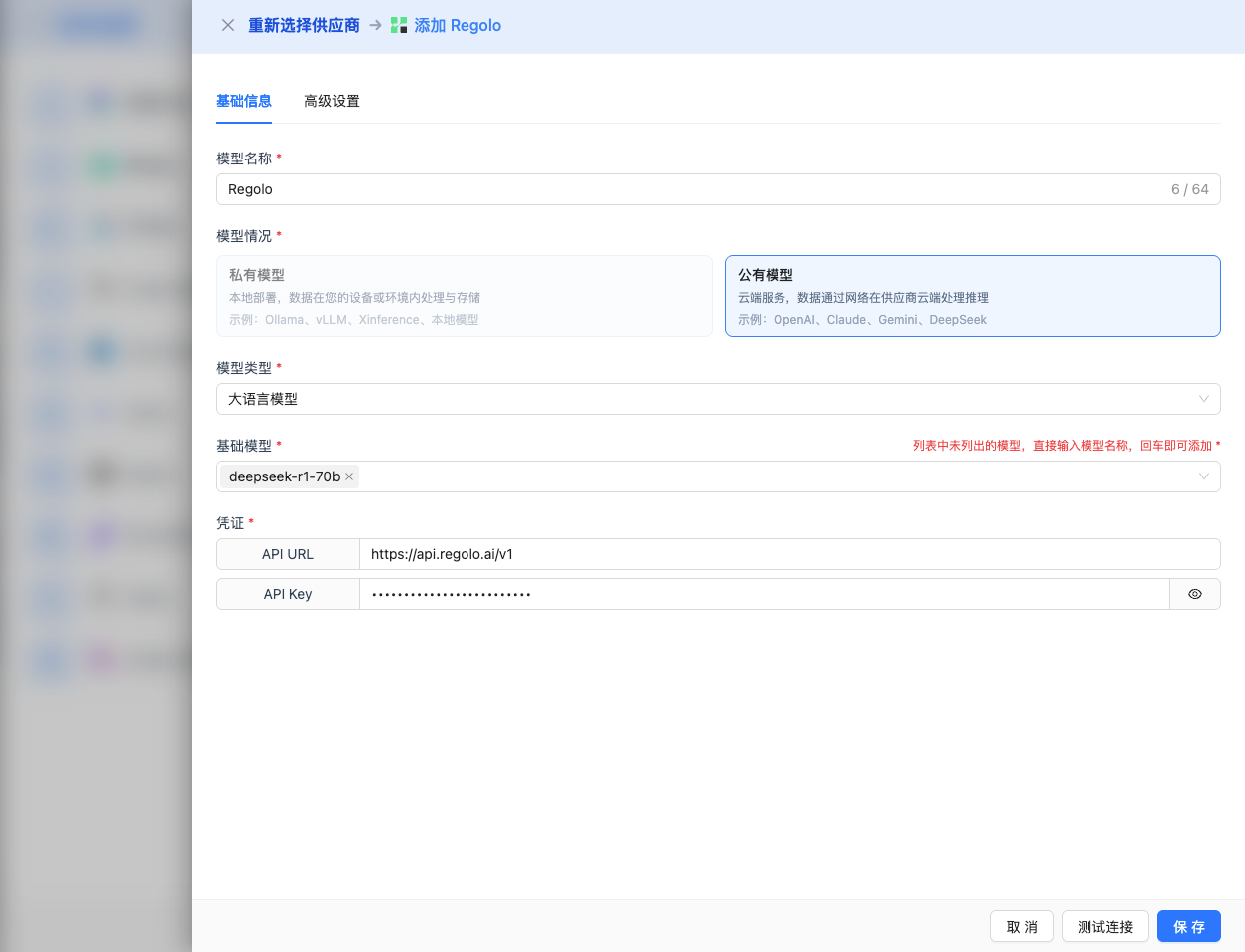
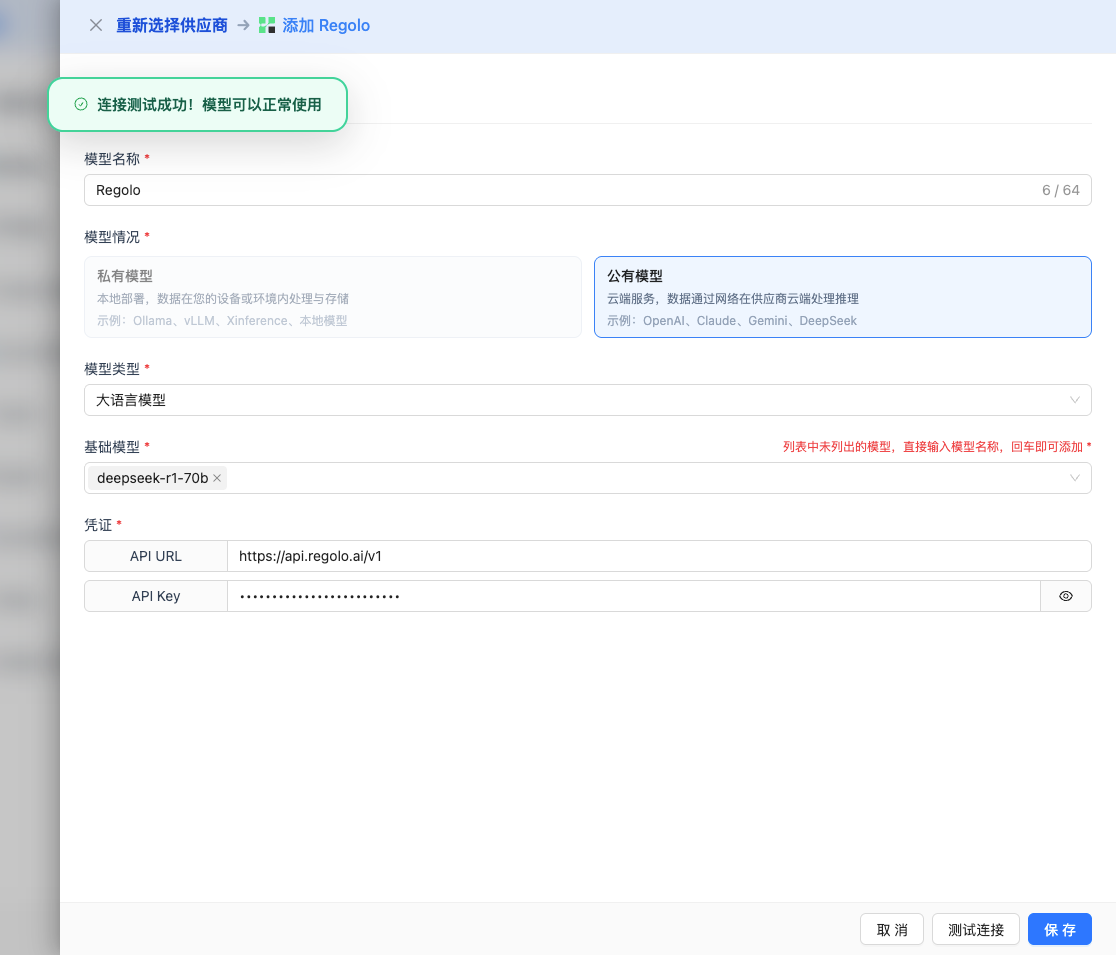
2.4 Fill in Configuration Information
Fill in the following information on the configuration page:
Basic Configuration
- Model Name: Give this model configuration a name (e.g., Regolo Phi-4)
- API URL: Keep the default
https://api.regolo.ai/v1 - API Key: Paste the Regolo API Key
- Model Version: Select or enter the model to use
- Microsoft Series:
Phi-4: Microsoft Phi-4, lightweight and efficient
- DeepSeek R1 Series:
DeepSeek-R1-Distill-Qwen-32B: DeepSeek R1 Distilled 32BDeepSeek-R1-Distill-Qwen-14B: DeepSeek R1 Distilled 14BDeepSeek-R1-Distill-Qwen-7B: DeepSeek R1 Distilled 7BDeepSeek-R1-Distill-Llama-8B: DeepSeek R1 Llama 8B
- Regolo Original:
maestrale-chat-v0.4-beta: Maestrale conversational model
- Llama Series:
Llama-3.3-70B-Instruct: Llama 3.3 70B InstructLlama-3.1-70B-Instruct: Llama 3.1 70B InstructLlama-3.1-8B-Instruct: Llama 3.1 8B Instruct
- DeepSeek Coder:
DeepSeek-Coder-6.7B-Instruct: DeepSeek Coder 6.7B
- Qwen Series:
Qwen2.5-72B-Instruct: Qwen 2.5 72B Instruct
- Microsoft Series:
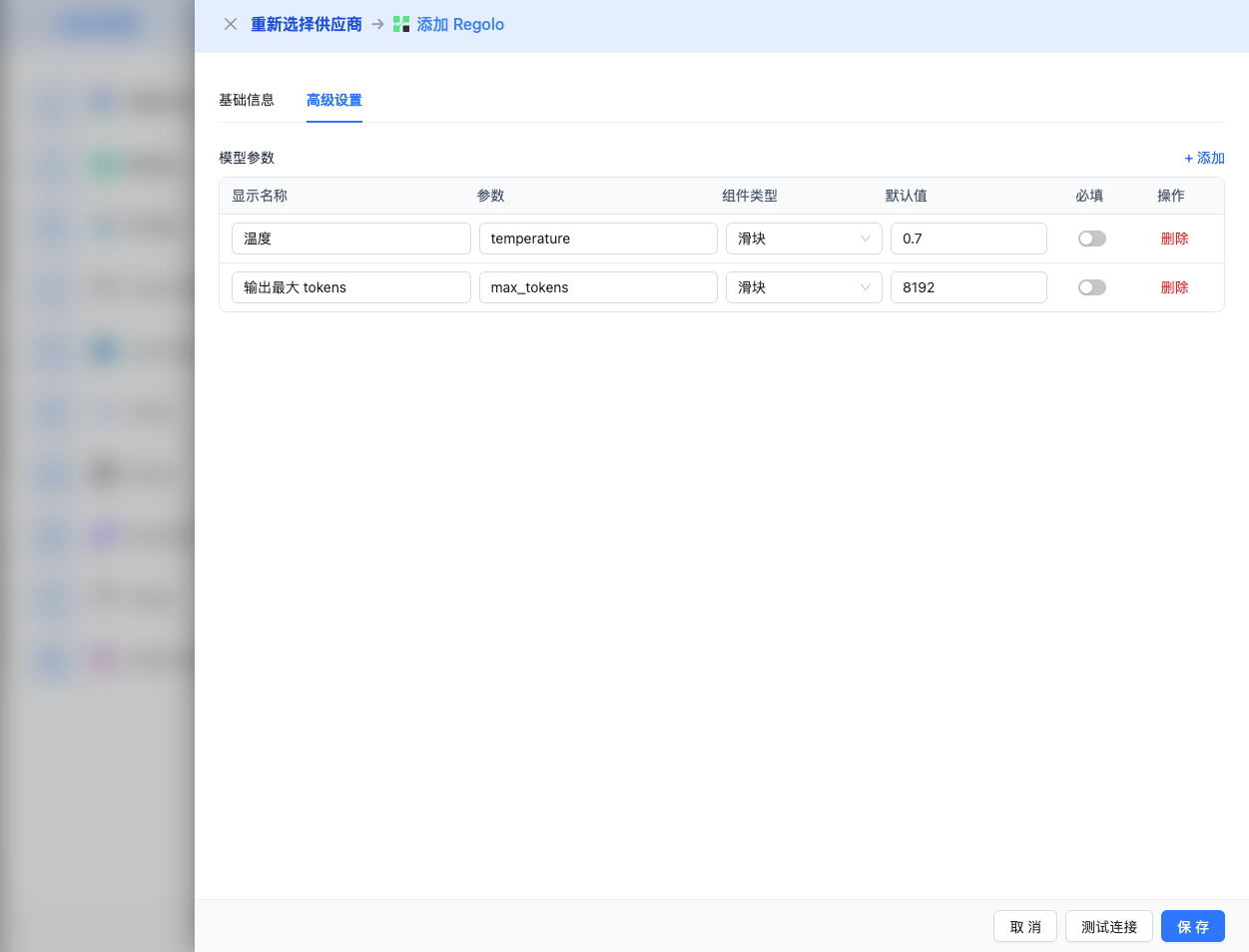
Advanced Configuration (Optional)
Expand the Advanced Configuration panel to adjust the following parameters:
CueMate Interface Adjustable Parameters:
Temperature: Controls output randomness
- Range: 0-2 (different models have different upper limits)
- Recommended Value: 0.7
- Effect: Higher values produce more random and creative output, lower values produce more stable and conservative output
- Usage Recommendations:
- Creative writing/brainstorming: 1.0-1.5
- General conversation/Q&A: 0.7-0.9
- Code generation/precise tasks: 0.3-0.5
Max Tokens: Limits the maximum output length
- Range: 256 - 262144 (depending on the model)
- Recommended Value: 8192
- Effect: Controls the maximum number of tokens in a single model response
- Model Limits:
- deepseek-r1-70b: max 64K tokens
- gemma-3-27b-it: max 128K tokens
- qwen3-coder-30b: max 256K tokens
- Other models: 8K-32K tokens
- Usage Recommendations:
- Short Q&A: 1024-2048
- General conversation: 4096-8192
- Long text generation: 16384-32768
- Ultra-long documents: 65536+ (supported models only)
Other Advanced Parameters Supported by Regolo API:
While the CueMate interface only provides temperature and max_tokens adjustments, if you call Regolo directly via API, you can also use the following advanced parameters (Regolo uses OpenAI-compatible API format):
top_p (nucleus sampling)
- Range: 0-1
- Default Value: 0.9
- Effect: Samples from the smallest candidate set with cumulative probability of p
- Relationship with temperature: Usually only adjust one of them
- Usage Recommendations:
- Maintain diversity while avoiding nonsense: 0.9-0.95
- More conservative output: 0.7-0.8
top_k
- Range: 1-100
- Default Value: 50
- Effect: Samples from the top k candidates with highest probability
- Usage Recommendations:
- More diversity: 50-100
- More conservative: 10-30
frequency_penalty
- Range: -2.0 to 2.0
- Default Value: 0
- Effect: Reduces the probability of repeating the same words (based on frequency)
- Usage Recommendations:
- Reduce repetition: 0.3-0.8
- Allow repetition: 0 (default)
- Force diversity: 1.0-2.0
presence_penalty
- Range: -2.0 to 2.0
- Default Value: 0
- Effect: Reduces the probability of words that have already appeared appearing again (based on presence)
- Usage Recommendations:
- Encourage new topics: 0.3-0.8
- Allow topic repetition: 0 (default)
stop
- Type: String array
- Default Value: null
- Effect: Stops generation when the specified string appears in the content
- Example:
["###", "User:", "\n\n"] - Use Cases:
- Structured output: Use delimiters to control format
- Dialogue systems: Prevent the model from speaking for the user
stream
- Type: Boolean
- Default Value: false
- Effect: Enable SSE streaming return, generating and returning incrementally
- In CueMate: Automatically handled, no manual setting required
seed
- Type: Integer
- Default Value: null
- Effect: Fix random seed, same input produces same output
- Use Cases:
- Reproducible testing
- Comparative experiments
- Note: Not all models support this
| No. | Scenario | temperature | max_tokens | top_p | frequency_penalty | presence_penalty |
|---|---|---|---|---|---|---|
| 1 | Creative Writing | 1.0-1.2 | 4096-8192 | 0.95 | 0.5 | 0.5 |
| 2 | Code Generation | 0.2-0.5 | 2048-4096 | 0.9 | 0.0 | 0.0 |
| 3 | Q&A System | 0.7 | 1024-2048 | 0.9 | 0.0 | 0.0 |
| 4 | Summarization | 0.3-0.5 | 512-1024 | 0.9 | 0.0 | 0.0 |
| 5 | Brainstorming | 1.2-1.5 | 2048-4096 | 0.95 | 0.8 | 0.8 |
2.5 Test Connection
After filling in the configuration, click the Test Connection button to verify if the configuration is correct.
If the configuration is correct, a success message will be displayed with a sample model response.
If the configuration is incorrect, an error log will be displayed, and you can view detailed error information through log management.
2.6 Save Configuration
After successful testing, click the Save button to complete the model configuration.
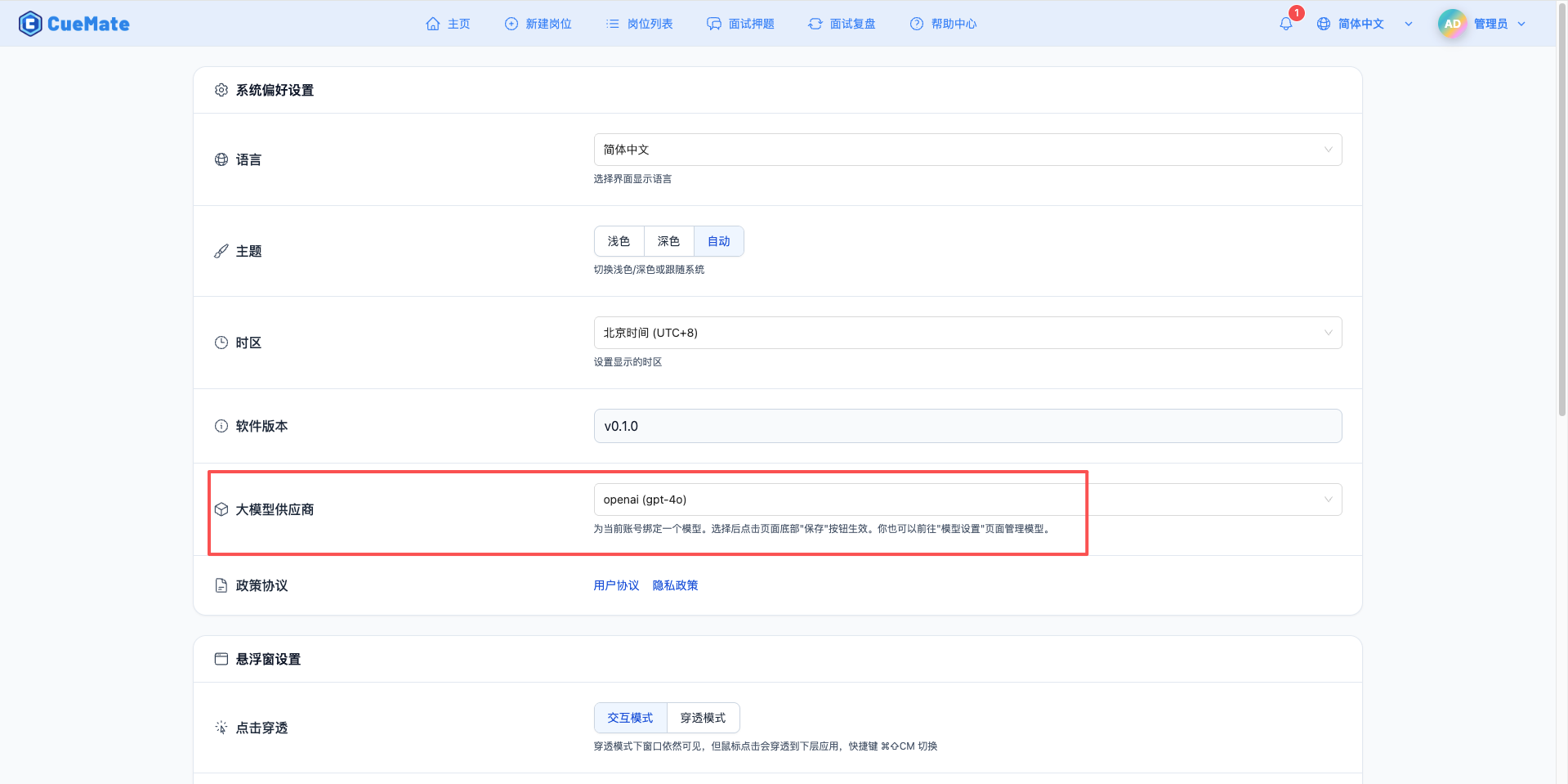
3. Use the Model
Through the dropdown menu in the upper right corner, enter the system settings interface and select the model configuration you want to use in the large model provider section.
After configuration, you can select to use this model in interview training, question generation, and other functions, or of course, you can individually select the model configuration for each interview in the interview options.
4. Supported Model List
4.1 DeepSeek Series
| No. | Model Name | Model ID | Parameters | Max Output | Use Cases |
|---|---|---|---|---|---|
| 1 | DeepSeek R1 70B | deepseek-r1-70b | 70B | 64K tokens | Enhanced reasoning, complex tasks, ultra-long context |
4.2 Llama Series
| No. | Model Name | Model ID | Parameters | Max Output | Use Cases |
|---|---|---|---|---|---|
| 1 | Llama Guard 3 8B | llama-guard3-8b | 8B | 8K tokens | Content safety audit, risk detection |
| 2 | Llama 3.3 70B | Llama-3.3-70B-Instruct | 70B | 8K tokens | Latest version, high-performance general tasks |
| 3 | Llama 3.1 8B | Llama-3.1-8B-Instruct | 8B | 8K tokens | Standard tasks, cost-effective |
4.3 Qwen Series
| No. | Model Name | Model ID | Parameters | Max Output | Use Cases |
|---|---|---|---|---|---|
| 1 | Qwen3 30B | qwen3-30b | 30B | 32K tokens | General conversation, long text processing |
| 2 | Qwen3 8B | Qwen3-8B | 8B | 32K tokens | Lightweight and efficient, fast response |
| 3 | Qwen3 Coder 30B | qwen3-coder-30b | 30B | 256K tokens | Code generation, ultra-long code context |
4.4 Mistral Series
| No. | Model Name | Model ID | Parameters | Max Output | Use Cases |
|---|---|---|---|---|---|
| 1 | Mistral Small 3.2 | mistral-small3.2 | - | 32K tokens | Lightweight model, multilingual support |
4.5 Google Gemma Series
| No. | Model Name | Model ID | Parameters | Max Output | Use Cases |
|---|---|---|---|---|---|
| 1 | Gemma 3 27B | gemma-3-27b-it | 27B | 128K tokens | Ultra-long context, document analysis |
4.6 Open Source Community Models
| No. | Model Name | Model ID | Parameters | Max Output | Use Cases |
|---|---|---|---|---|---|
| 1 | GPT OSS 120B | gpt-oss-120b | 120B | 8K tokens | Open-source super-large model, experimental tasks |
4.7 Regolo Original
| No. | Model Name | Model ID | Parameters | Max Output | Use Cases |
|---|---|---|---|---|---|
| 1 | Maestrale Chat v0.4 | maestrale-chat-v0.4-beta | - | 8K tokens | Conversation optimization, multilingual (Italian enhanced) |
5. Common Issues
5.1 Invalid API Key
Symptom: API Key error message when testing connection
Solution:
- Check if the API Key is completely copied
- Confirm the API Key has not expired or been disabled
- Verify the API Key permissions are set correctly
5.2 Model Not Available
Symptom: Error message indicating model does not exist or is not authorized
Solution:
- Confirm the model ID spelling is correct
- Check if the account has access permissions for this model
- Verify the account balance is sufficient
5.3 Request Timeout
Symptom: No response for a long time when testing connection or using
Solution:
- Check if the network connection is normal
- Confirm the API URL is configured correctly
- Check firewall settings
5.4 Quota Limit
Symptom: Request quota exceeded error
Solution:
- Log in to the Regolo platform to check quota usage
- Recharge or apply for more quota
- Optimize usage frequency
5.5 Enterprise Services
- High availability guarantee
- Professional technical support
- Flexible pricing plans
5.6 Rich Models
- Support for multiple mainstream open-source models
- Regolo original optimized models
- Continuously updated with latest models
5.7 Performance Optimization
- Distributed inference cluster
- Low latency response
- High concurrency support
5.8 Data Security
- Encrypted data transmission
- Privacy protection mechanism
- Compliance certification
Regolo uses a pay-as-you-go billing model:
| Model Level | Input Price | Output Price | Unit |
|---|---|---|---|
| Lightweight (<10B) | ¥0.001 | ¥0.003 | /1K tokens |
| Standard (10B-30B) | ¥0.003 | ¥0.009 | /1K tokens |
| High-performance (>30B) | ¥0.006 | ¥0.018 | /1K tokens |
Note: Specific prices are subject to the Regolo official website.
5.9 Model Selection
- Development/Testing: Use 7B-14B parameter models, low cost
- Production Environment: Choose 32B-70B models based on performance requirements
- Code Generation: Prefer DeepSeek Coder series
- General Conversation: Recommended Llama 3.3 or Qwen 2.5 series
5.10 Cost Optimization
- Set
max_tokensparameter reasonably - Use caching to reduce duplicate requests
- Choose models with appropriate parameter sizes
- Monitor API usage
Related Links
5.1 Enterprise Applications
- Internal knowledge base Q&A
- Customer service automation
- Document generation and processing
5.2 Developers
- Application prototype development
- AI feature integration
- Algorithm validation testing
5.3 Private Deployment Needs
- Support for private deployment solutions
- Customized model training
- Dedicated technical support