
Configure Google Gemini
Google Gemini is a multimodal AI model series developed by Google, supporting various input forms such as text, images, and audio. It provides multi-tier model choices from lightweight to flagship, with powerful reasoning, analysis, and creative capabilities.
1. Obtain Google Gemini API Key
1.1 Visit AI Studio
Visit AI Studio and log in: https://aistudio.google.com/
1.2 Enter API Keys Page
After logging in, click Get API key in the left menu.
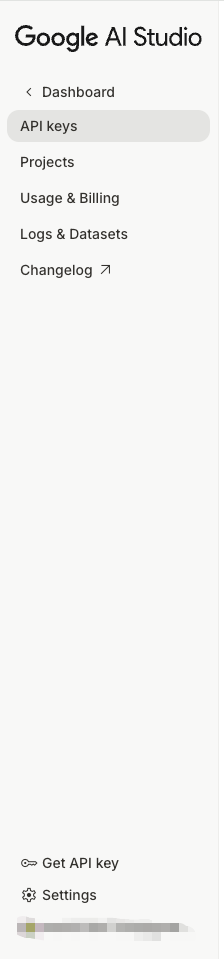
1.3 Create New API Key
Click the Create API key button.
1.4 Select Google Cloud Project
In the pop-up dialog:
- Select an existing project or create a new project
- Click Create API key in existing project or Create API key in new project
1.5 Copy API Key
After successful creation, the system will display the API Key.
Important: Please copy and save it immediately. The API Key starts with AIzaSy and is 39 characters long.
Click the copy button, and the API Key is copied to the clipboard.
2. Configure Gemini Model in CueMate
2.1 Enter Model Settings Page
After logging into CueMate, click Model Settings in the dropdown menu in the upper right corner.
2.2 Add New Model
Click the Add Model button in the upper right corner.

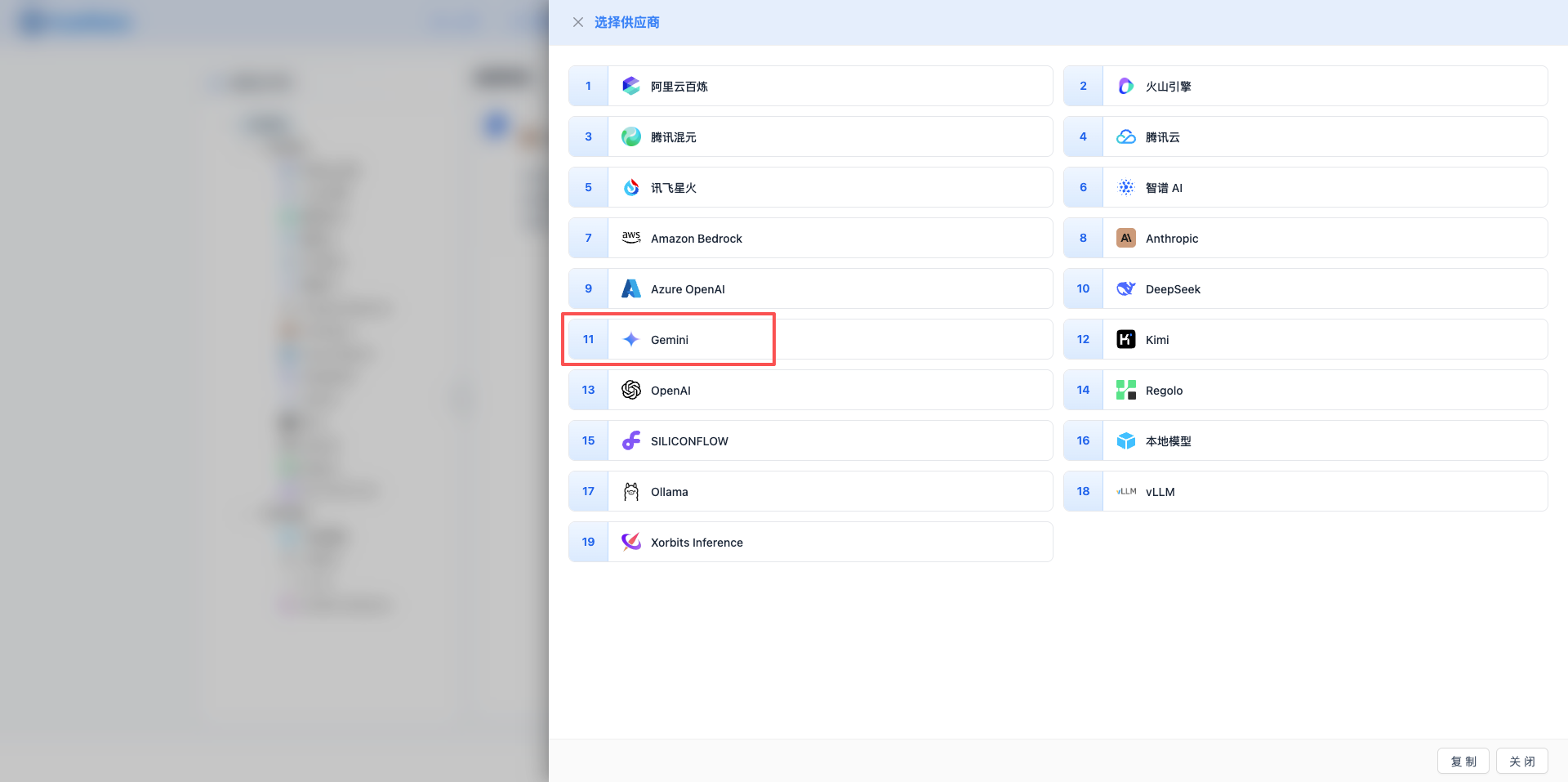
2.3 Select Gemini Provider
In the pop-up dialog:
- Provider Type: Select Gemini
- After clicking, automatically proceed to the next step
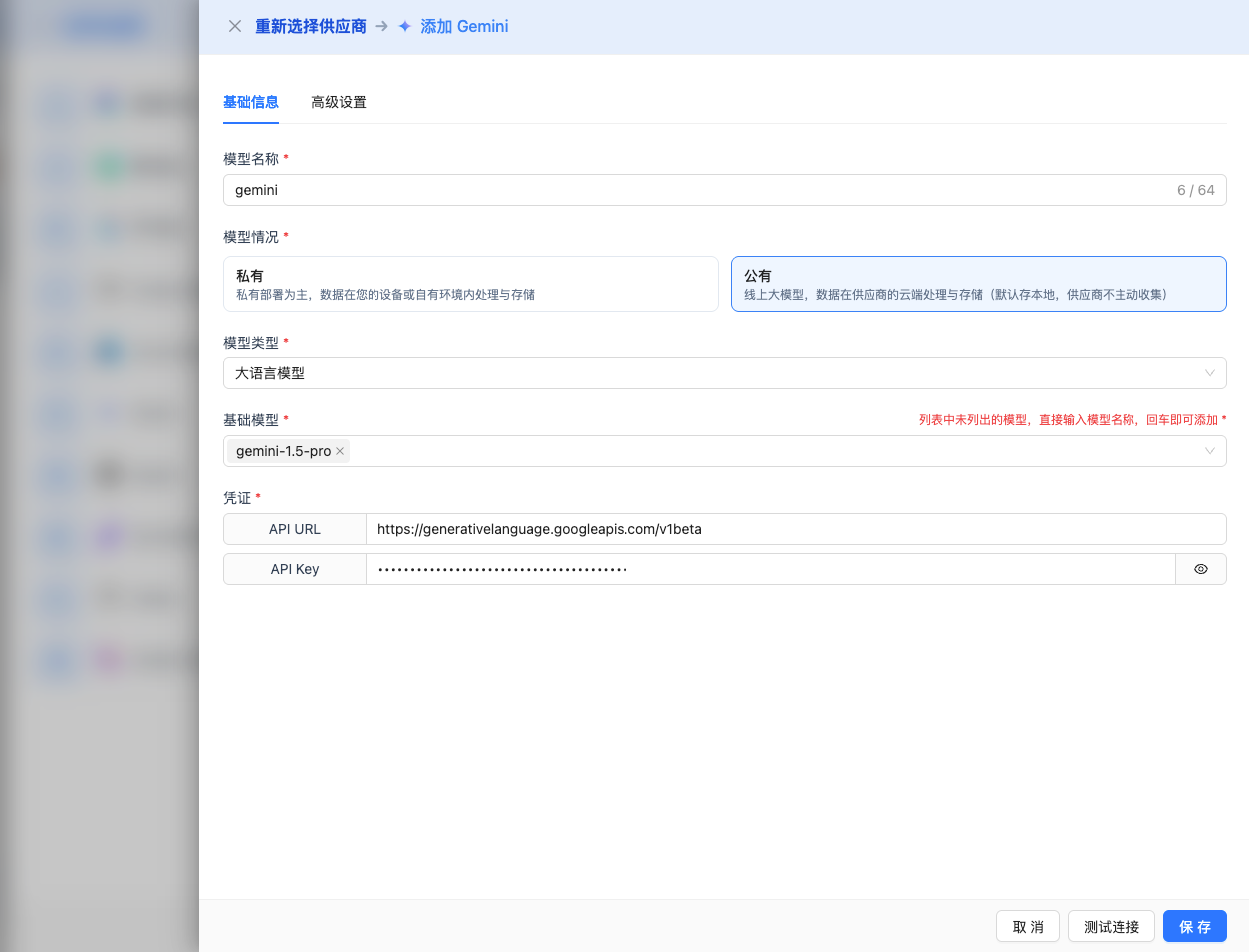
2.4 Fill in Configuration Information
Fill in the following information on the configuration page:
Basic Configuration
- Model Name: Give this model configuration a name (e.g., Gemini-2.0-Flash)
- API Key: Paste the Google Gemini API Key you just copied
- API URL: Keep the default
https://generativelanguage.googleapis.com/v1beta - Model Version: Select or enter the model you want to use (recommended to use full version number)
gemini-2.5-pro-exp-03-25: 2.5 Pro experimental version, best performancegemini-2.0-flash-001: 2.0 Flash stable version, recommendedgemini-2.0-flash-exp: 2.0 Flash experimental versiongemini-1.5-pro-latest: 1.5 Pro latest versiongemini-1.5-pro-002: 1.5 Pro stable versiongemini-1.5-flash-latest: 1.5 Flash latest versiongemini-1.5-flash-002: 1.5 Flash stable versiongemini-1.5-flash-8b: 8B parameter lightweight versiongemini-1.0-pro: 1.0 Pro standard version (legacy)gemini-1.0-pro-vision: 1.0 with vision understanding (legacy)
Advanced Configuration (Optional)
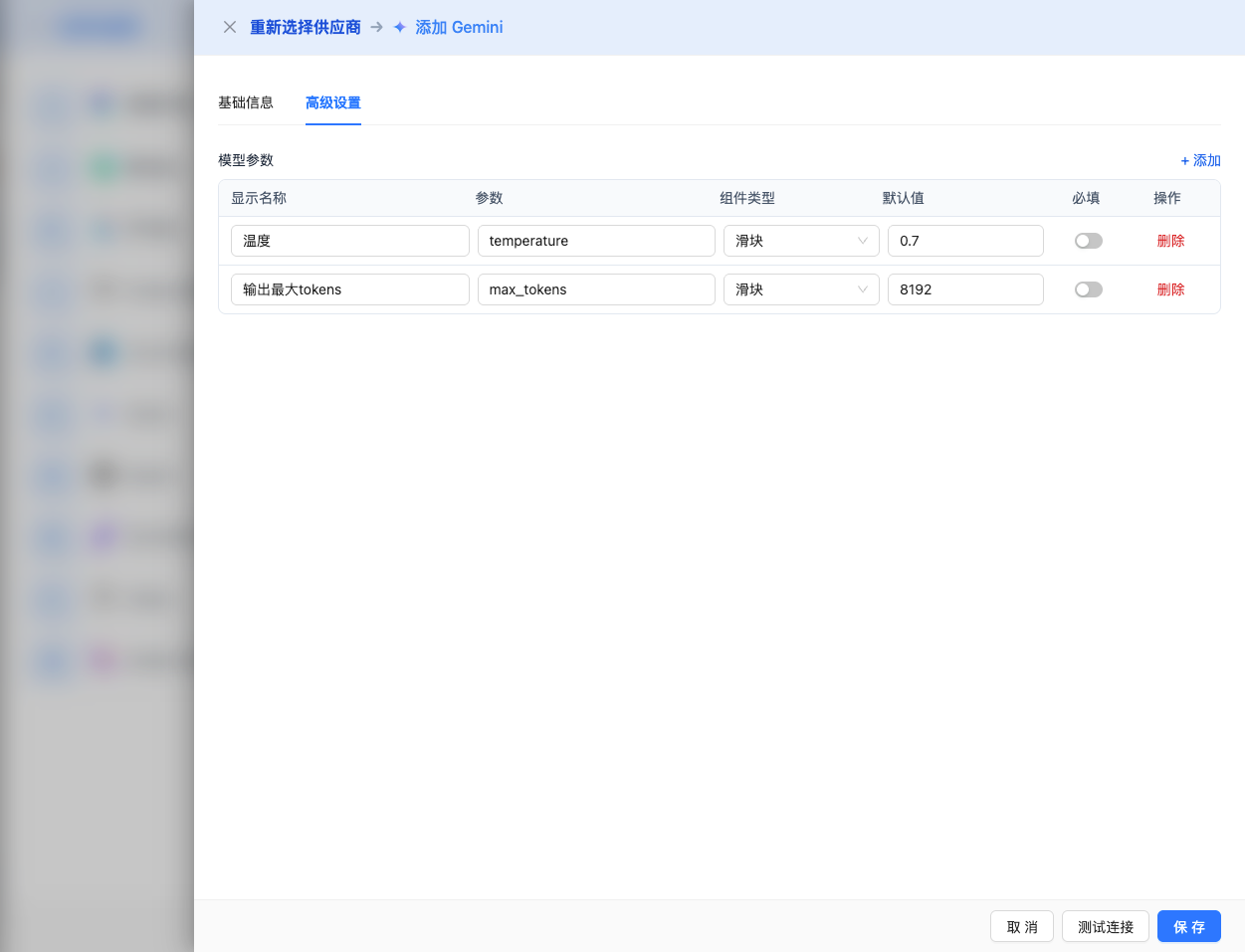
Expand the Advanced Configuration panel to adjust the following parameters:
Parameters Adjustable in CueMate Interface:
Temperature: Controls output randomness
- Range: 0-2
- Recommended Value: 0.7
- Function: Higher values produce more random and creative output, lower values produce more stable and conservative output
- Usage Suggestions:
- Creative writing/brainstorming: 1.0-1.5
- Regular conversation/Q&A: 0.7-0.9
- Code generation/precise tasks: 0.3-0.5
- Note: Gemini's temperature range is 0-2, different from Claude's 0-1
Max Output Tokens (maxOutputTokens): Limits single output length
- Range: 256 - 65536 (depending on model)
- Recommended Value: 8192
- Function: Controls the maximum word count of model's single response
- Model Limits:
- Gemini 2.5 Pro: Maximum 65K tokens
- Gemini 2.0 Series: Maximum 8K tokens
- Gemini 1.5 Series: Maximum 8K tokens
- Gemini 1.0 Pro: Maximum 2K tokens
- Gemini 1.0 Pro Vision: Maximum 4K tokens
- Usage Suggestions:
- Short Q&A: 1024-2048
- Regular conversation: 4096-8192
- Long text generation: 16384-32768
- Ultra-long output: 65536 (2.5 Pro only)
Other Advanced Parameters Supported by Google Gemini API:
Although the CueMate interface only provides temperature and maxOutputTokens adjustments, if you call Gemini directly through the API, you can also use the following advanced parameters:
topP (nucleus sampling)
- Range: 0-1
- Default Value: 0.95
- Function: Samples from the minimum candidate set where cumulative probability reaches p
- Relationship with temperature: Can be used simultaneously
- Usage Suggestions:
- Maintain diversity: 0.9-1.0
- More conservative output: 0.7-0.8
topK
- Range: 1-40
- Default Value: 40 (or null, meaning no limit)
- Function: Samples from the k candidate words with the highest probability
- Usage Suggestions:
- More diverse: 32-40
- More conservative: 10-20
- Note: Gemini's topK maximum value is 40
stopSequences (stop sequences)
- Type: String array
- Default Value: null
- Maximum Count: 5 strings
- Function: Stops when generated content contains specified strings
- Example:
["END", "###", "\n\n"] - Use Cases:
- Structured output: Use delimiters to control format
- Dialogue system: Prevent model from continuing to generate
- Code block control: Use code block end markers
candidateCount
- Type: Integer
- Range: 1-8
- Default Value: 1
- Function: Generate multiple candidate responses for selection
- Use Cases:
- A/B testing different outputs
- Selecting best response
- Note: Will increase API call cost
Gemini Safety Settings:
- safetySettings
- Type: Object array
- Function: Configure content safety filtering level
- Safety Categories:
HARM_CATEGORY_HARASSMENT: Harassment contentHARM_CATEGORY_HATE_SPEECH: Hate speechHARM_CATEGORY_SEXUALLY_EXPLICIT: Sexually explicit contentHARM_CATEGORY_DANGEROUS_CONTENT: Dangerous content
- Filtering Levels:
BLOCK_NONE: No filteringBLOCK_LOW_AND_ABOVE: Filter low risk and aboveBLOCK_MEDIUM_AND_ABOVE: Filter medium and above (default)BLOCK_ONLY_HIGH: Only filter high risk
- Example:json
{ "safetySettings": [ { "category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_MEDIUM_AND_ABOVE" } ] } - Usage Suggestions:
- Public-facing applications: Keep default settings
- Internal tools/research: Can relax appropriately (BLOCK_ONLY_HIGH)
- Strict scenarios: Use BLOCK_LOW_AND_ABOVE
| Scenario | temperature | maxOutputTokens | topP | topK | stopSequences |
|---|---|---|---|---|---|
| Creative Writing | 1.0-1.2 | 4096-8192 | 0.95 | 40 | null |
| Code Generation | 0.2-0.5 | 2048-4096 | 0.9 | 30 | null |
| Q&A System | 0.7 | 1024-2048 | 0.9 | 40 | null |
| Summary | 0.3-0.5 | 512-1024 | 0.9 | 20 | null |
| Structured Output | 0.5 | 2048 | 0.9 | 30 | ["END", "###"] |
2.5 Test Connection
After filling in the configuration, click the Test Connection button to verify if the configuration is correct.
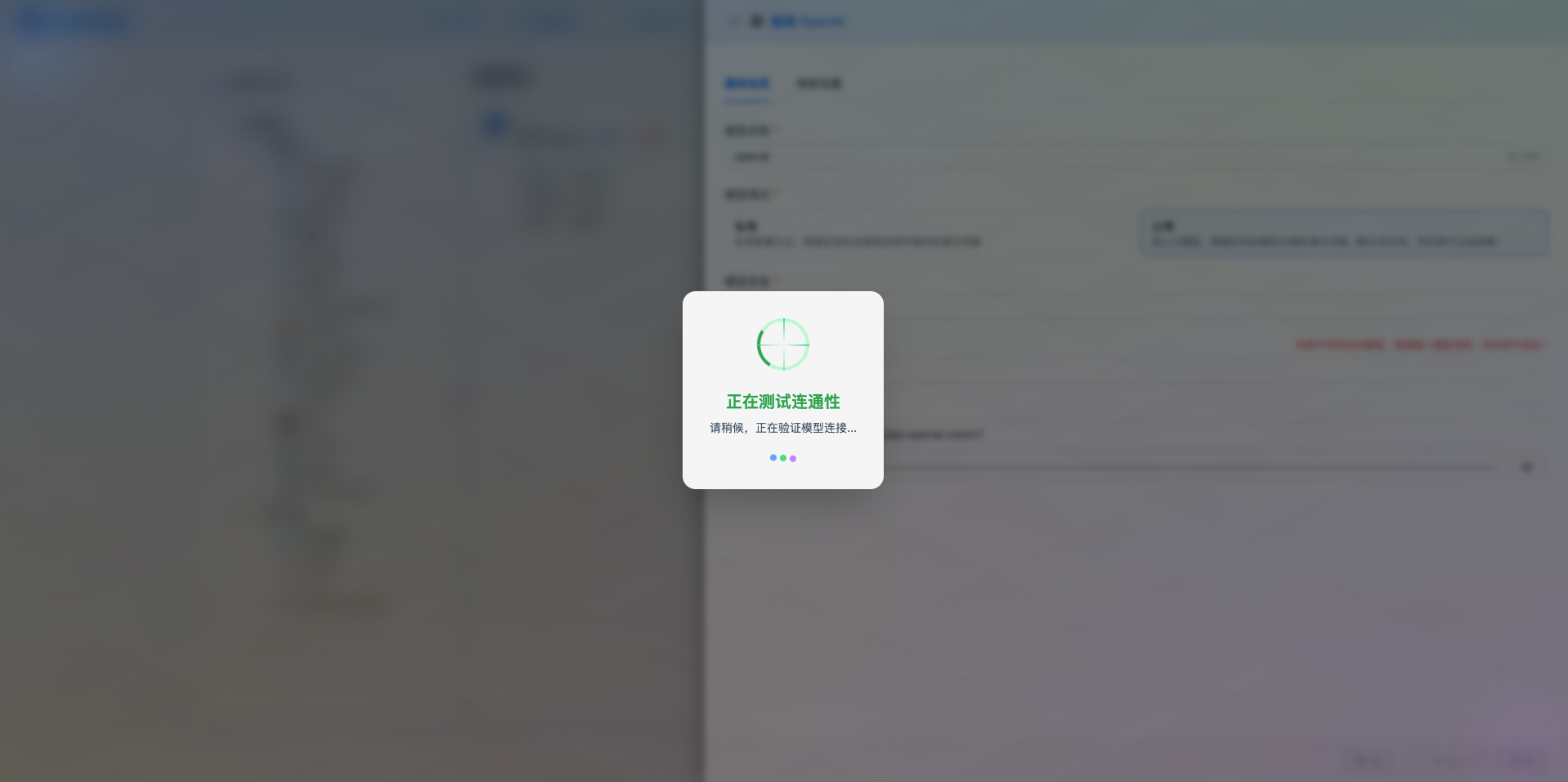
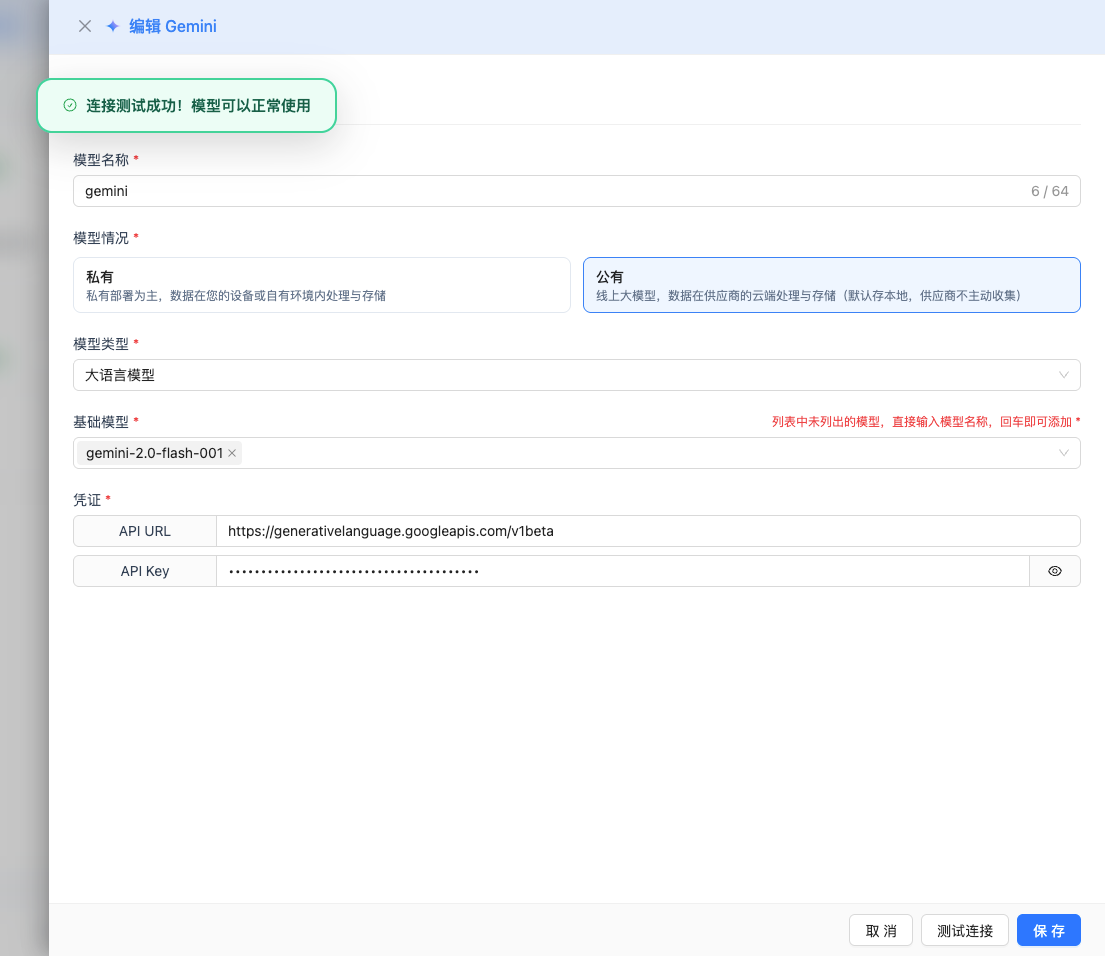
If the configuration is correct, a successful test message will be displayed, along with a sample response from the model.
If the configuration is incorrect, test error logs will be displayed, and you can view specific error information through log management.
2.6 Save Configuration
After a successful test, click the Save button to complete the model configuration.
3. Use Model
Through the dropdown menu in the upper right corner, enter the system settings interface, and select the model configuration you want to use in the LLM provider section.
After configuration, you can select to use this model in interview training, question generation, and other functions. Of course, you can also select the model configuration for a specific interview in the interview options.
4. Supported Model List
4.1 Gemini 2.5 Series (2026 Latest)
| No. | Model Name | Model ID | Max Output | Use Case |
|---|---|---|---|---|
| 1 | Gemini 2.5 Pro (Experimental) | gemini-2.5-pro-exp-03-25 | 65K tokens | Best performance, long text generation |
4.2 Gemini 2.0 Series
| No. | Model Name | Model ID | Max Output | Use Case |
|---|---|---|---|---|
| 1 | Gemini 2.0 Flash | gemini-2.0-flash-001 | 8K tokens | Recommended, stable version |
| 2 | Gemini 2.0 Flash (Experimental) | gemini-2.0-flash-exp | 8K tokens | Experimental feature testing |
4.3 Gemini 1.5 Series
| No. | Model Name | Model ID | Max Output | Use Case |
|---|---|---|---|---|
| 1 | Gemini 1.5 Pro (Latest) | gemini-1.5-pro-latest | 8K tokens | Automatically uses latest version |
| 2 | Gemini 1.5 Pro 002 | gemini-1.5-pro-002 | 8K tokens | Complex reasoning, technical interviews |
| 3 | Gemini 1.5 Flash (Latest) | gemini-1.5-flash-latest | 8K tokens | Automatically uses latest version |
| 4 | Gemini 1.5 Flash 002 | gemini-1.5-flash-002 | 8K tokens | Fast response, regular conversation |
| 5 | Gemini 1.5 Flash 8B | gemini-1.5-flash-8b | 8K tokens | Lightweight tasks, low cost |
4.4 Gemini 1.0 Series (Legacy)
| No. | Model Name | Model ID | Max Output | Use Case |
|---|---|---|---|---|
| 1 | Gemini 1.0 Pro | gemini-1.0-pro | 2K tokens | Basic conversation |
| 2 | Gemini 1.0 Pro Vision | gemini-1.0-pro-vision | 4K tokens | Image understanding, multimodal |
4.5 Recommended Selection
- Production Environment:
gemini-2.0-flash-001(stable, cost-effective) - Long Text Generation:
gemini-2.5-pro-exp-03-25(maximum 65K output) - Fast Response:
gemini-1.5-flash-002(low latency) - Lightweight Applications:
gemini-1.5-flash-8b(lowest cost)
5. Common Issues
5.1 Model Name Does Not Exist (404 Error)
Symptom: models/gemini-1.5-pro is not found for API version v1beta when testing connection
Solution:
- Check if the model name uses the full version number
- Wrong Example:
gemini-1.5-pro(no version number, will return 404) - Correct Examples:
gemini-2.0-flash-001(recommended)gemini-1.5-pro-002gemini-1.5-flash-002gemini-1.5-pro-latest(using latest alias)
- Do not use short aliases like
gemini-1.5-proorgemini-1.5-flash, must use full version number
5.2 Invalid API Key
Symptom: API Key error when testing connection
Solution:
- Check if the API Key starts with
AIzaSy - Confirm the API Key is 39 characters long
- Check if the Google Cloud project has enabled Generative Language API
- Confirm the API Key has not been restricted or disabled
5.3 Request Timeout
Symptom: No response for a long time during testing or use
Solution:
- Check if the network connection is normal
- If in China, may need to use a proxy
- Check firewall settings
5.4 Insufficient Quota
Symptom: Quota exhausted or request frequency too high message
Solution:
- Log in to Google Cloud Console to check quota usage
- Apply to increase quota limit
- Optimize usage frequency
5.5 API Not Enabled
Symptom: API not enabled or project has no permission message
Solution:
- Visit Google Cloud Console
- Enable Generative Language API
- Confirm project configuration is correct
5.6 Cannot Access AI Studio (Permission Denied)
Symptom: "permission denied" error immediately after clicking "Get API Key" and redirects to documentation page
Solution:
- IP Region Restrictions: AI Studio has access restrictions for some regions, need to use a proxy from supported regions like the US
- Bypass AI Studio to Create API Key:
- Visit Google Cloud Console - Credentials Page
- Click "Create Credentials" → "API Key"
- Copy the generated API Key (starts with
AIzaSy) - Select "Generative Language API" in "API Restrictions"
- Note: API Keys created through Cloud Console are identical to those created through AI Studio and can be used normally