
配置 Kimi
Kimi 是月之暗面(Moonshot AI)開發的大語言模型服務,以超長上下文(200萬字)處理能力著稱。支援長文件閱讀、檔案分析、聯網搜尋等功能,特別適合處理大量文字資訊的場景。
1. 獲取 Kimi API Key
1.1 訪問 Kimi 開放平臺
訪問月之暗面開放平臺並登入:https://platform.moonshot.cn/

1.2 進入 API 金鑰管理頁面
登入後,點選左側選單的 API 金鑰管理。

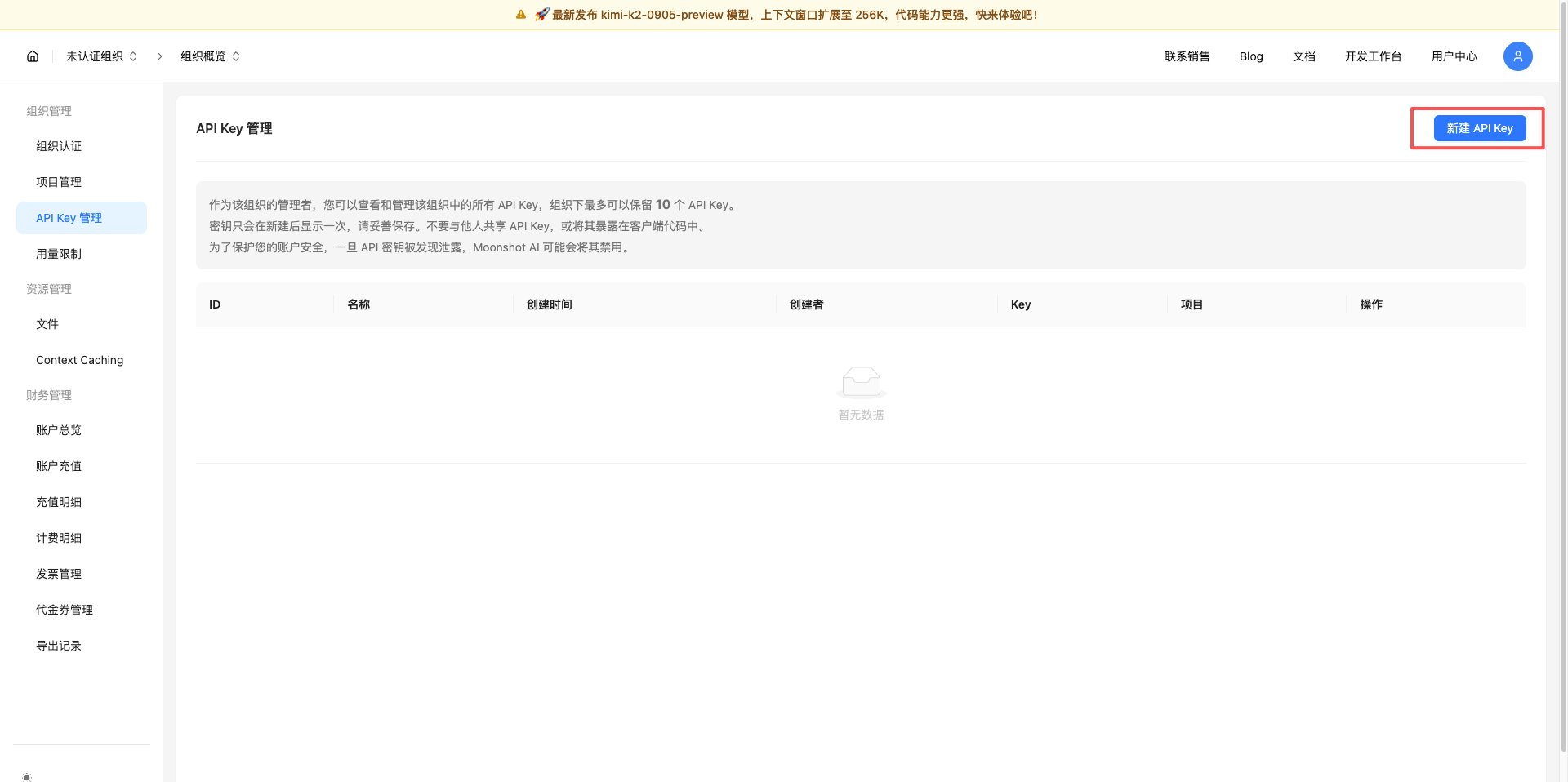
1.3 建立新的 API Key
點選右上角的 新建 按鈕。
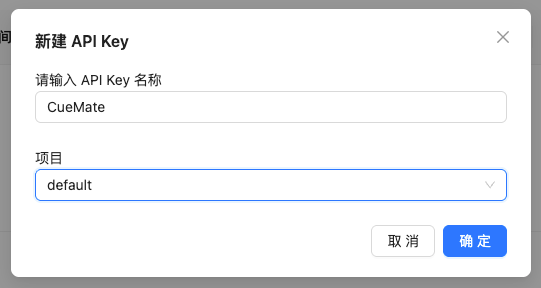
1.4 設定 API Key 資訊
在彈出的對話方塊中:
- 輸入金鑰名稱(例如:CueMate)
- 點選 確定 按鈕
1.5 複製 API Key
建立成功後,系統會顯示 API Key。
重要:請立即複製並妥善儲存,API Key 以 sk- 開頭。

點選複製按鈕,API Key 已複製到剪貼簿。
2. 在 CueMate 中配置 Kimi 模型
2.1 進入模型設定頁面
登入 CueMate 系統後,點選右上角下拉選單的 模型設定。
2.2 新增新模型
點選右上角的 新增模型 按鈕。

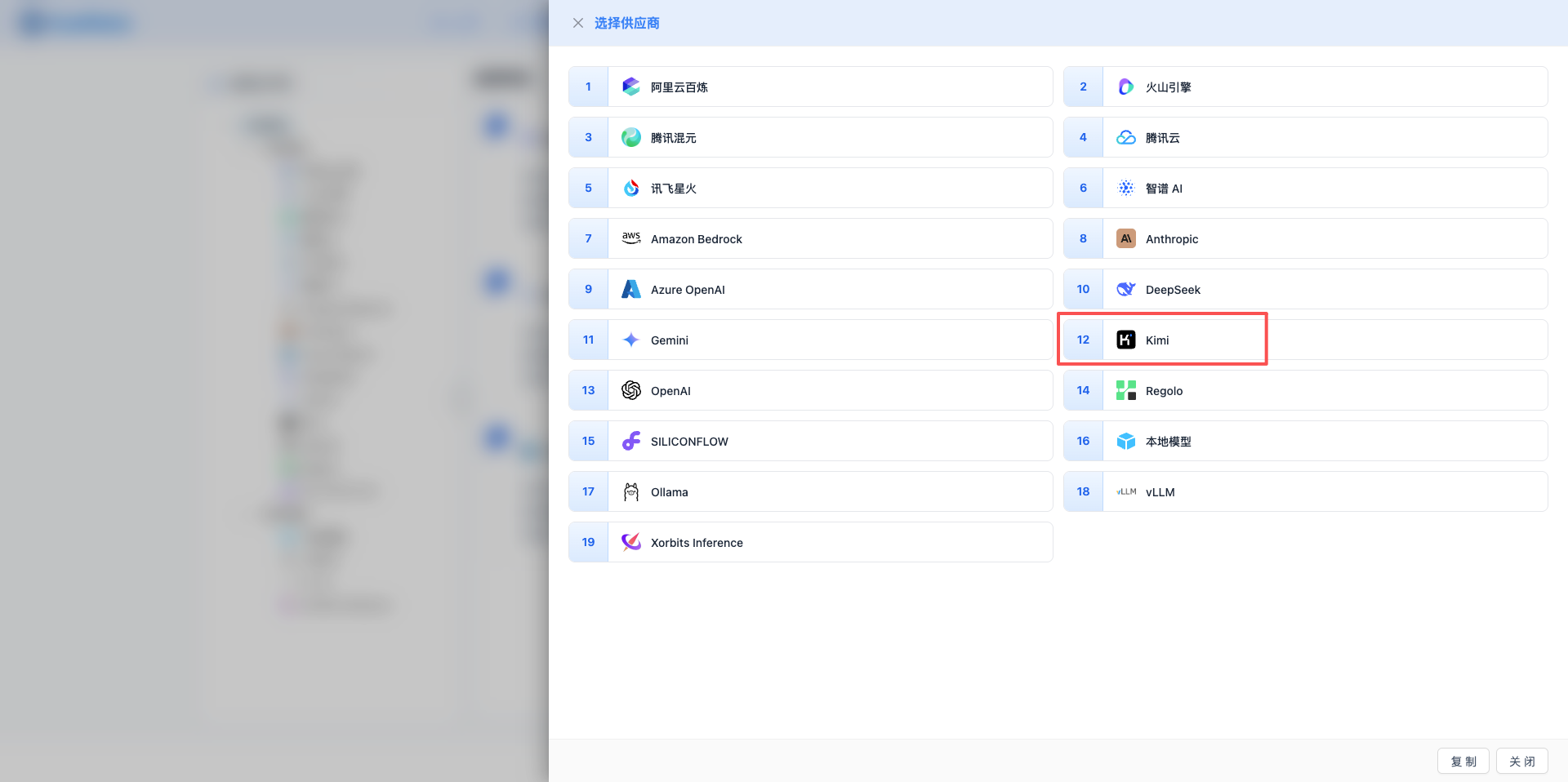
2.3 選擇 Kimi 服務商
在彈出的對話方塊中:
- 服務商型別:選擇 Kimi
- 點選後 自動進入下一步
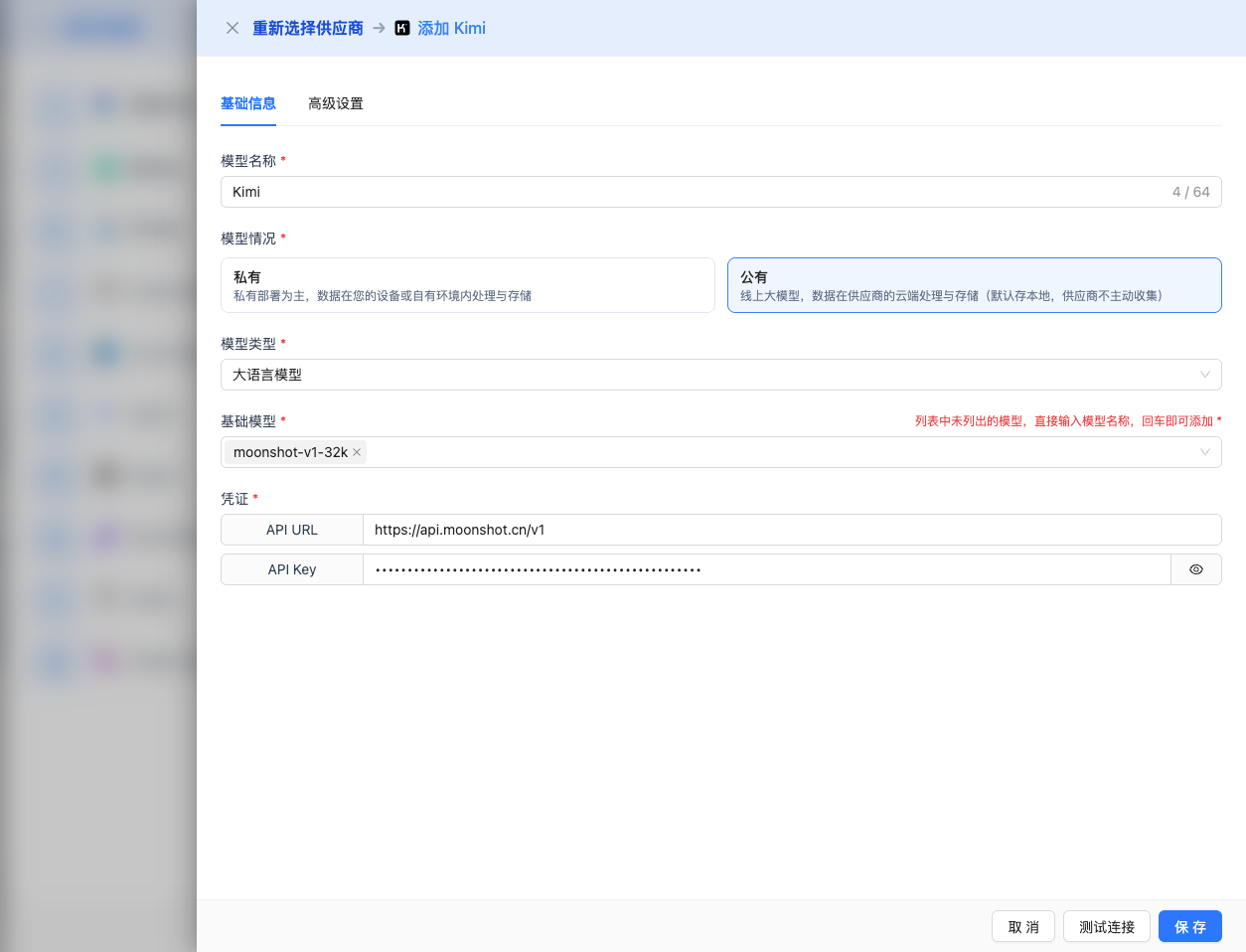
2.4 填寫配置資訊
在配置頁面填寫以下資訊:
基礎配置
- 模型名稱:為這個模型配置起個名字(例如:Kimi-128K)
- API URL:保持預設
https://api.moonshot.cn/v1(OpenAI 相容格式) - API Key:貼上剛才複製的 Kimi API Key
- 模型版本:選擇要使用的模型ID,常用模型包括:
moonshot-v1-128k:128K 超長上下文,最大輸出65K,適合超長文件理解、多輪對話moonshot-v1-32k:32K 長上下文,最大輸出16K,適合長文件處理、複雜推理moonshot-v1-8k:8K 標準上下文,最大輸出4K,適合常規對話、快速響應
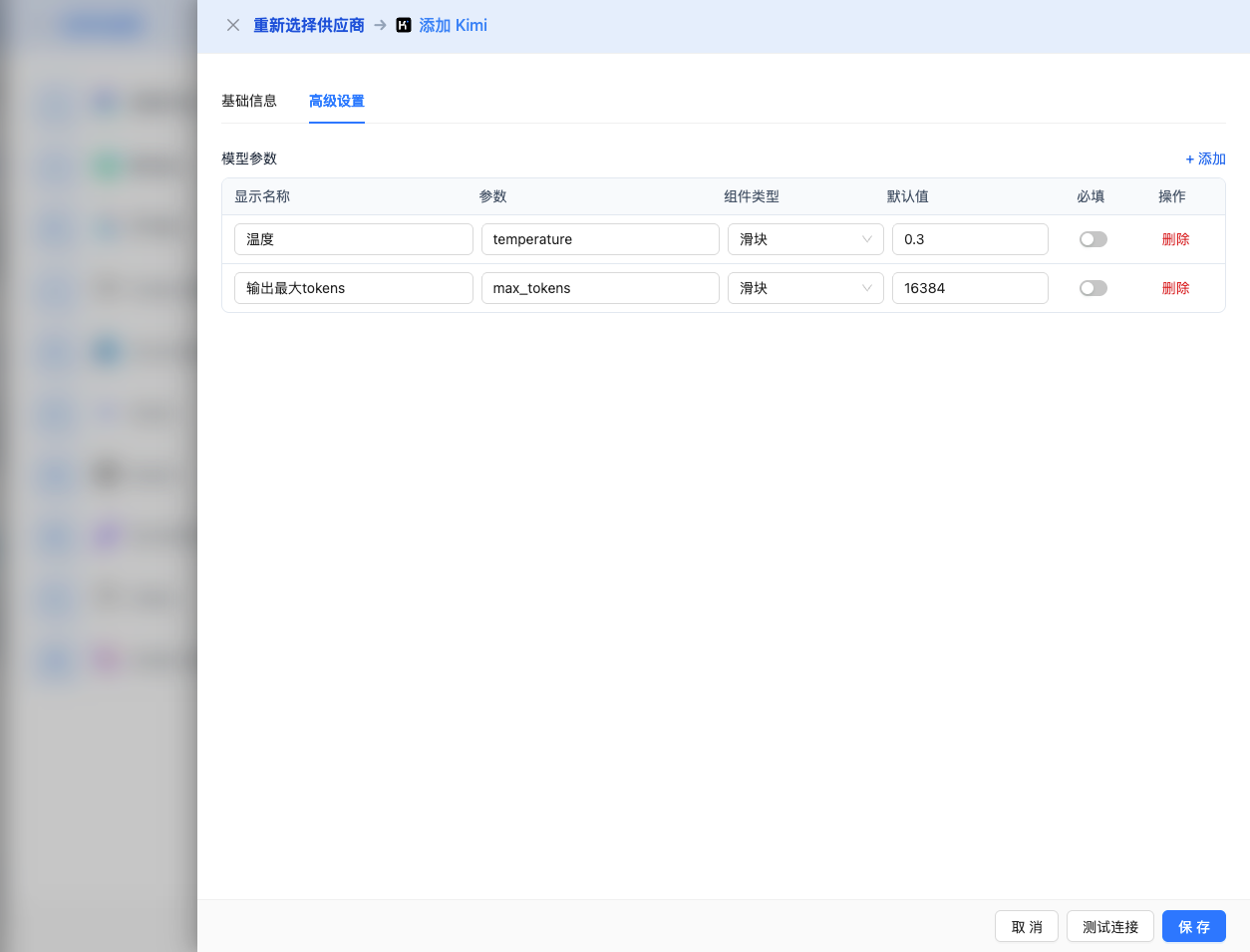
高階配置(可選)
展開 高階配置 面板,可以調整以下引數:
CueMate 介面可調引數:
溫度(temperature):控制輸出隨機性
- 範圍:0-1(注意:Kimi 的溫度上限是 1,不同於 OpenAI 的 2)
- 推薦值:0.3
- 作用:值越高輸出越隨機創新,值越低輸出越穩定保守
- 使用建議:
- 創意寫作/頭腦風暴:0.7-0.9
- 常規對話/問答:0.3-0.5
- 程式碼生成/精確任務:0.1-0.3
- 長文件分析:0.2-0.4
輸出最大 tokens(max_tokens):限制單次輸出長度
- 範圍:256 - 65536(根據模型而定)
- 推薦值:8192
- 作用:控制模型單次響應的最大字數
- 模型限制:
- moonshot-v1-128k:最大 65K tokens
- moonshot-v1-32k:最大 16K tokens
- moonshot-v1-8k:最大 4K tokens
- 使用建議:
- 簡短問答:1024-2048
- 常規對話:4096-8192
- 長文生成:16384-32768
- 超長文件:65536(僅 128k 模型)
Kimi API 支援的其他高階引數:
雖然 CueMate 介面只提供 temperature 和 max_tokens 調整,但如果你透過 API 直接呼叫 Kimi,還可以使用以下高階引數(Kimi 採用 OpenAI 相容的 API 格式):
top_p(nucleus sampling)
- 範圍:0-1
- 預設值:1
- 作用:從機率累積達到 p 的最小候選集中取樣
- 與 temperature 的關係:通常只調整其中一個
- 使用建議:
- 保持多樣性但避免離譜:0.9-0.95
- 更保守的輸出:0.7-0.8
frequency_penalty(頻率懲罰)
- 範圍:-2.0 到 2.0
- 預設值:0
- 作用:降低重複相同詞彙的機率(基於詞頻)
- 使用建議:
- 減少重複:0.3-0.8
- 允許重複:0(預設)
presence_penalty(存在懲罰)
- 範圍:-2.0 到 2.0
- 預設值:0
- 作用:降低已出現過的詞彙再次出現的機率(基於是否出現)
- 使用建議:
- 鼓勵新話題:0.3-0.8
- 允許重複話題:0(預設)
stop(停止序列)
- 型別:字串或陣列
- 預設值:null
- 作用:當生成內容包含指定字串時停止
- 示例:
["###", "使用者:", "\n\n"]
stream(流式輸出)
- 型別:布林值
- 預設值:false
- 作用:啟用 SSE 流式返回
- CueMate 中:自動處理,無需手動設定
| 序號 | 場景 | temperature | max_tokens | top_p | frequency_penalty | presence_penalty |
|---|---|---|---|---|---|---|
| 1 | 創意寫作 | 0.7-0.9 | 8192-16384 | 0.95 | 0.5 | 0.5 |
| 2 | 程式碼生成 | 0.1-0.3 | 2048-4096 | 0.9 | 0.0 | 0.0 |
| 3 | 問答系統 | 0.3-0.5 | 1024-2048 | 0.9 | 0.0 | 0.0 |
| 4 | 文件分析 | 0.2-0.4 | 8192-32768 | 0.9 | 0.0 | 0.0 |
| 5 | 超長文件 | 0.3 | 32768-65536 | 0.9 | 0.0 | 0.0 |
2.5 測試連線
填寫完配置後,點選 測試連線 按鈕,驗證配置是否正確。
如果配置正確,會顯示測試成功的提示,並返回模型的響應示例。
如果配置錯誤,會顯示測試錯誤的日誌,並且可以透過日誌管理,檢視具體報錯資訊。
2.6 儲存配置
測試成功後,點選 儲存 按鈕,完成模型配置。
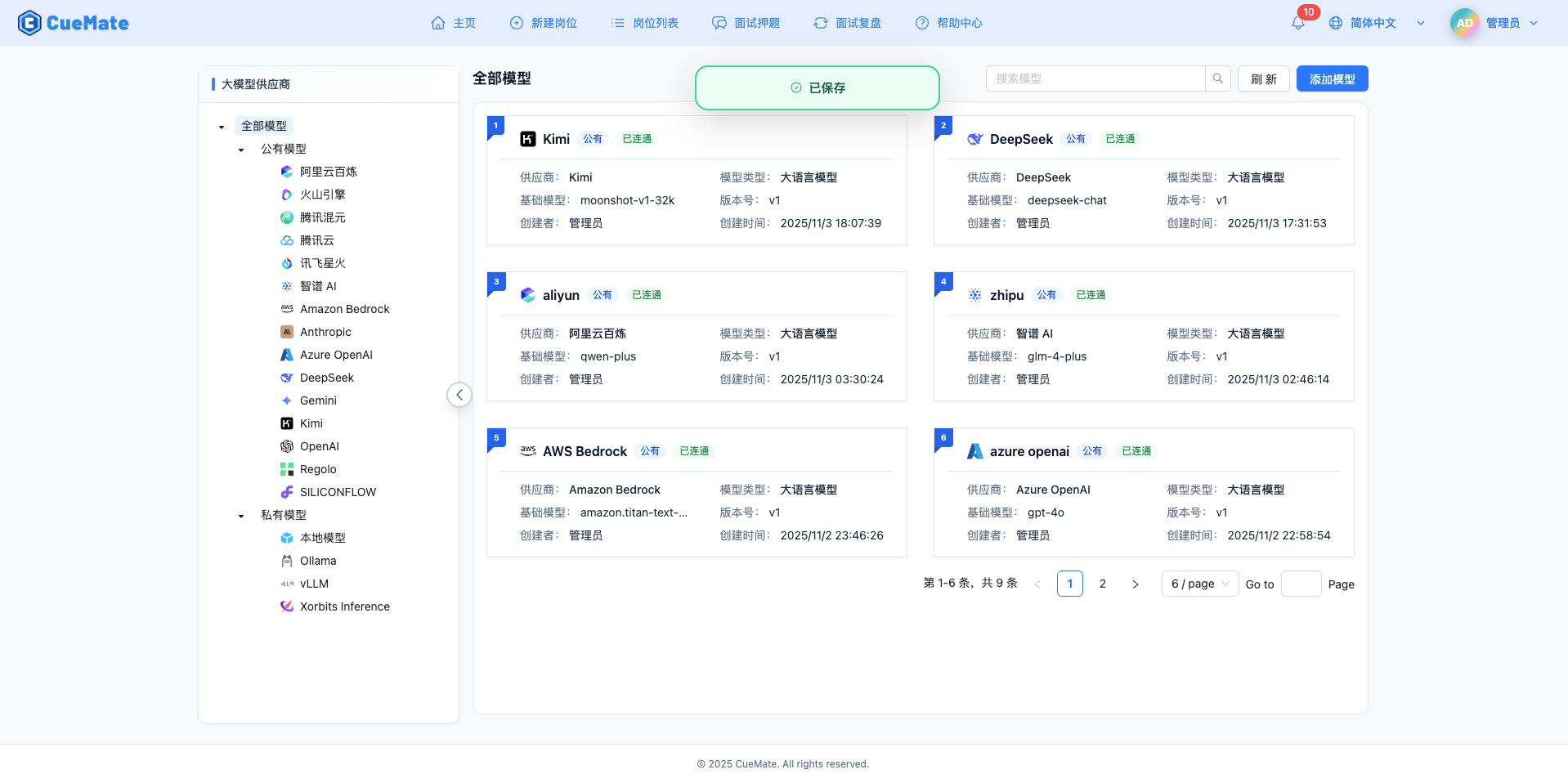
3. 使用模型
透過右上角下拉選單,進入系統設定介面,在大模型服務商欄目選擇想要使用的模型配置。
配置完成後,可以在面試訓練、問題生成等功能中選擇使用此模型, 當然也可以在面試的選項中單此選擇此次面試的模型配置。
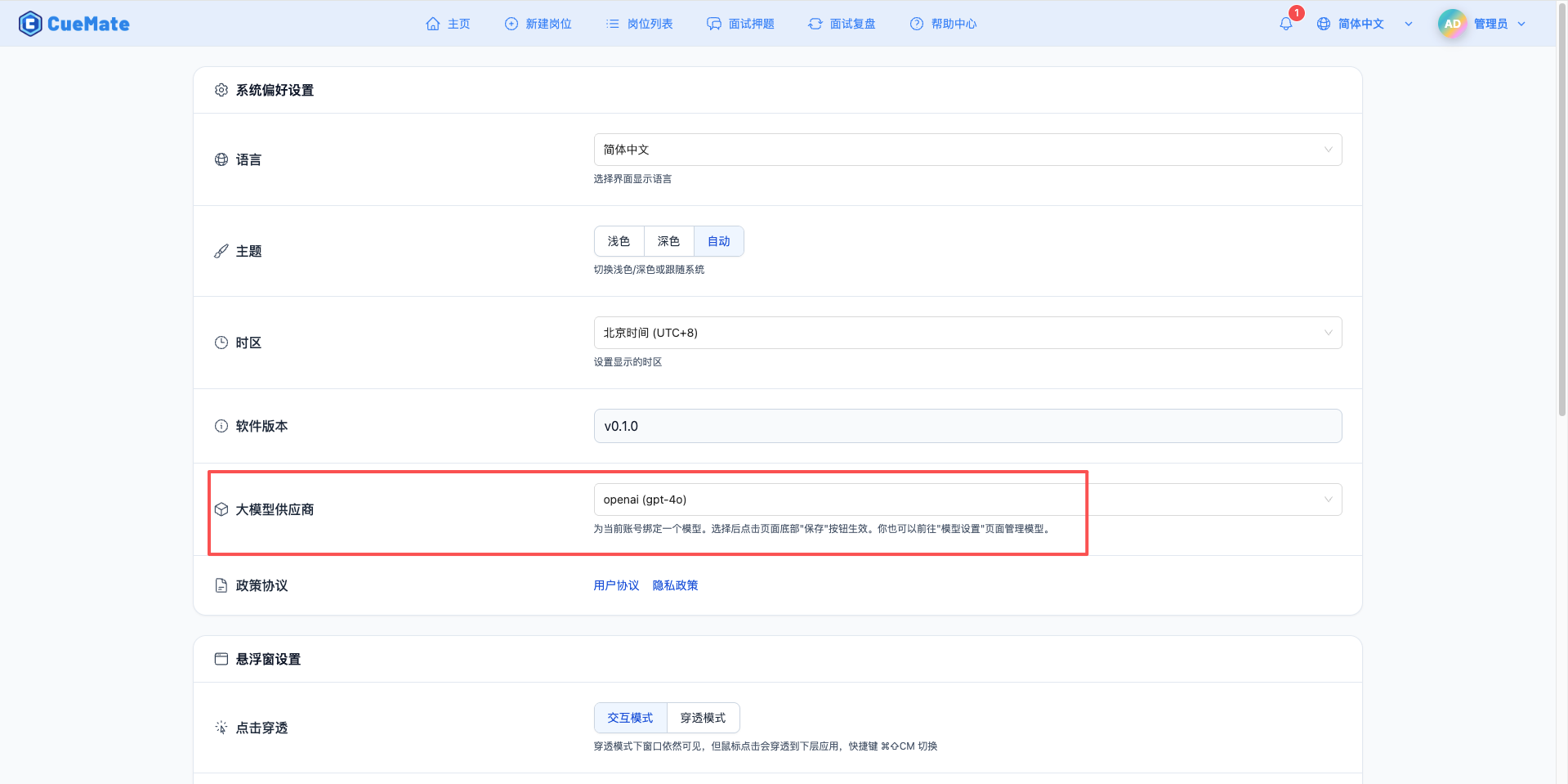
4. 支援的模型列表
4.1 Moonshot v1 系列
| 序號 | 模型名稱 | 模型 ID | 上下文長度 | 最大輸出 | 適用場景 |
|---|---|---|---|---|---|
| 1 | Moonshot v1 128K | moonshot-v1-128k | 128K tokens | 65K tokens | 超長文件理解、多輪對話 |
| 2 | Moonshot v1 32K | moonshot-v1-32k | 32K tokens | 16K tokens | 長文件處理、複雜推理 |
| 3 | Moonshot v1 8K | moonshot-v1-8k | 8K tokens | 4K tokens | 常規對話、快速響應 |
5. 常見問題
5.1 API Key 無效
現象:測試連線時提示 API Key 錯誤
解決方案:
- 檢查 API Key 是否以
sk-開頭 - 確認 API Key 完整複製
- 檢查賬戶是否有可用額度
5.2 請求超時
現象:測試連線或使用時長時間無響應
解決方案:
- 檢查網路連線是否正常
- 確認 API URL 地址正確
- 檢查防火牆設定
5.3 配額不足
現象:提示配額已用完或餘額不足
解決方案:
- 登入月之暗面平臺檢視賬戶餘額
- 充值或申請更多配額
- 選擇合適的模型版本