
配置 Amazon Bedrock
Amazon Bedrock 是 AWS 提供的全託管基礎模型服務,整合了 Anthropic Claude、Meta Llama、Amazon Titan 等多家頂級模型。提供企業級安全、隱私保護和靈活的模型選擇,支援按需付費。
1. 獲取 AWS Bedrock 訪問許可權
1.1 訪問 AWS 控制檯
訪問 AWS Management Console 並登入:https://console.aws.amazon.com/

1.2 進入 Bedrock 服務
- 在搜尋框中輸入 Bedrock
- 點選 Amazon Bedrock
- 選擇您的區域(建議 us-east-1)
1.3 請求模型訪問許可權
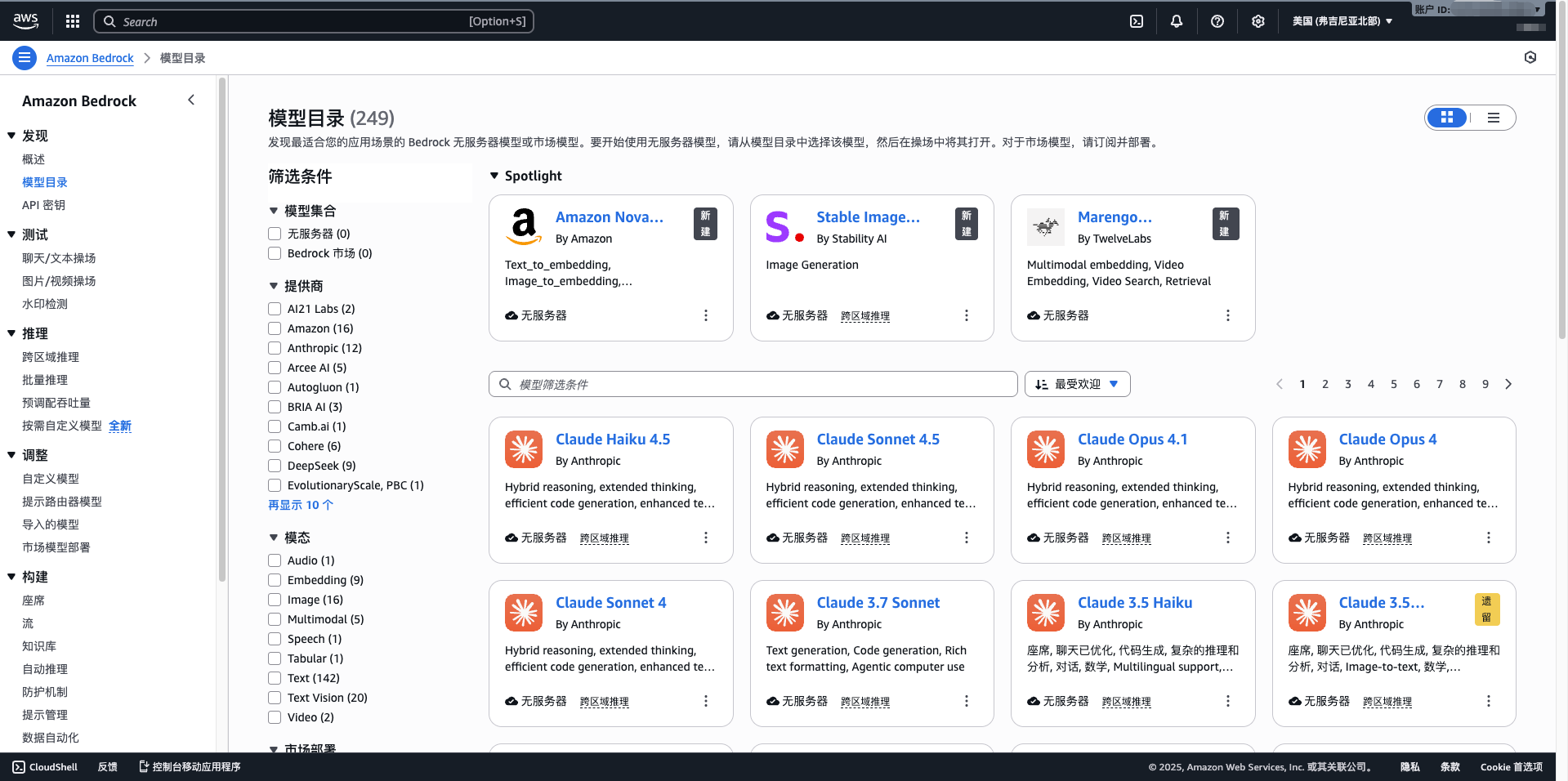
- 點選左側選單的 Model access
- 點選 Manage model access
- 勾選需要使用的模型(如 Claude 3.5 Sonnet、Llama 3.1、Mistral Large)
- 點選 Request model access
- 等待稽覈透過(通常幾分鐘內)
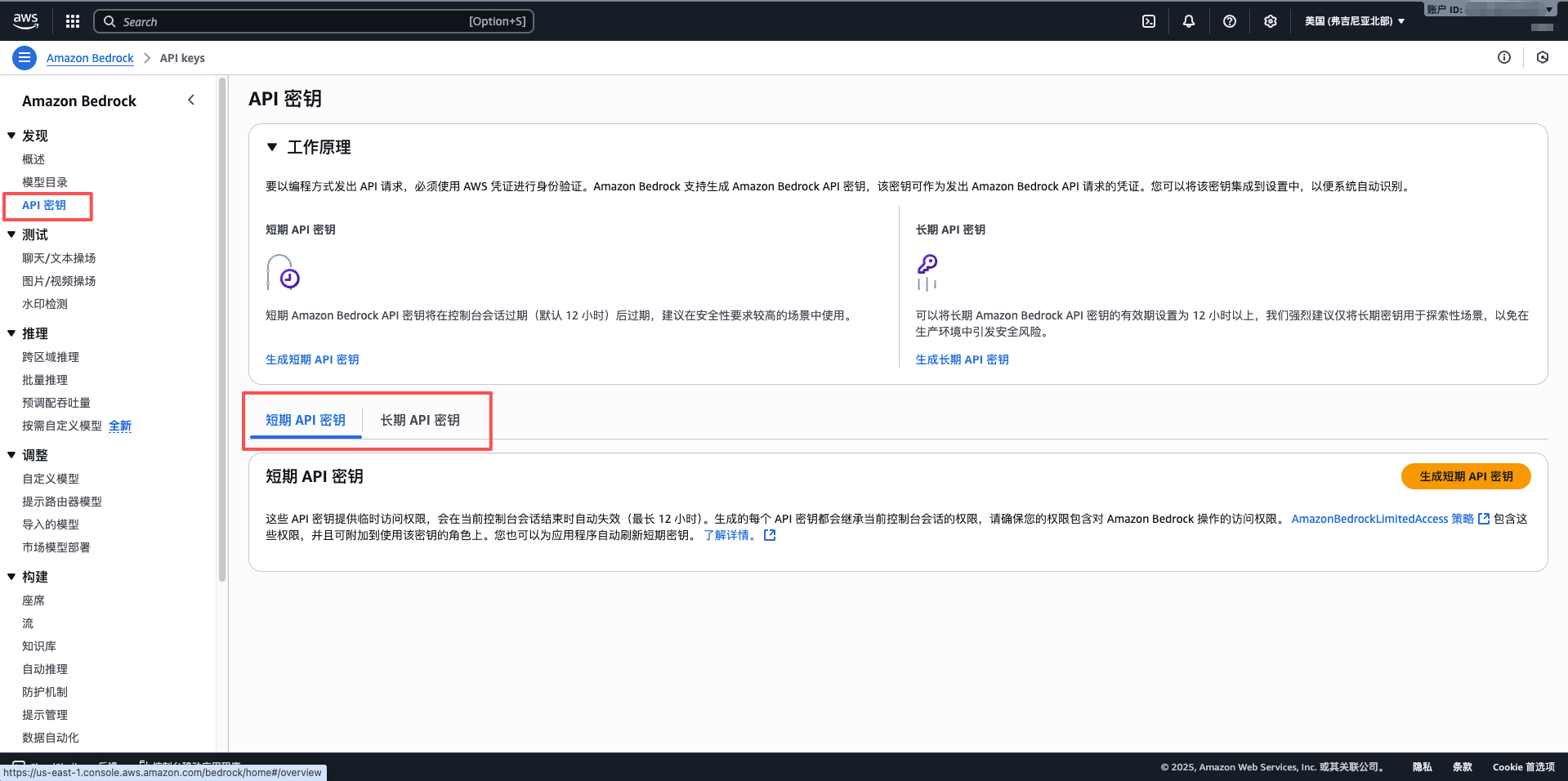
1.4 建立 IAM 使用者和訪問金鑰
- 訪問 IAM 控制檯:https://console.aws.amazon.com/iam/
- 點選 使用者 > 新增使用者
- 輸入使用者名稱(例如:cuemate-bedrock)
- 選擇 訪問金鑰 - 程式化訪問
- 附加策略:AmazonBedrockFullAccess
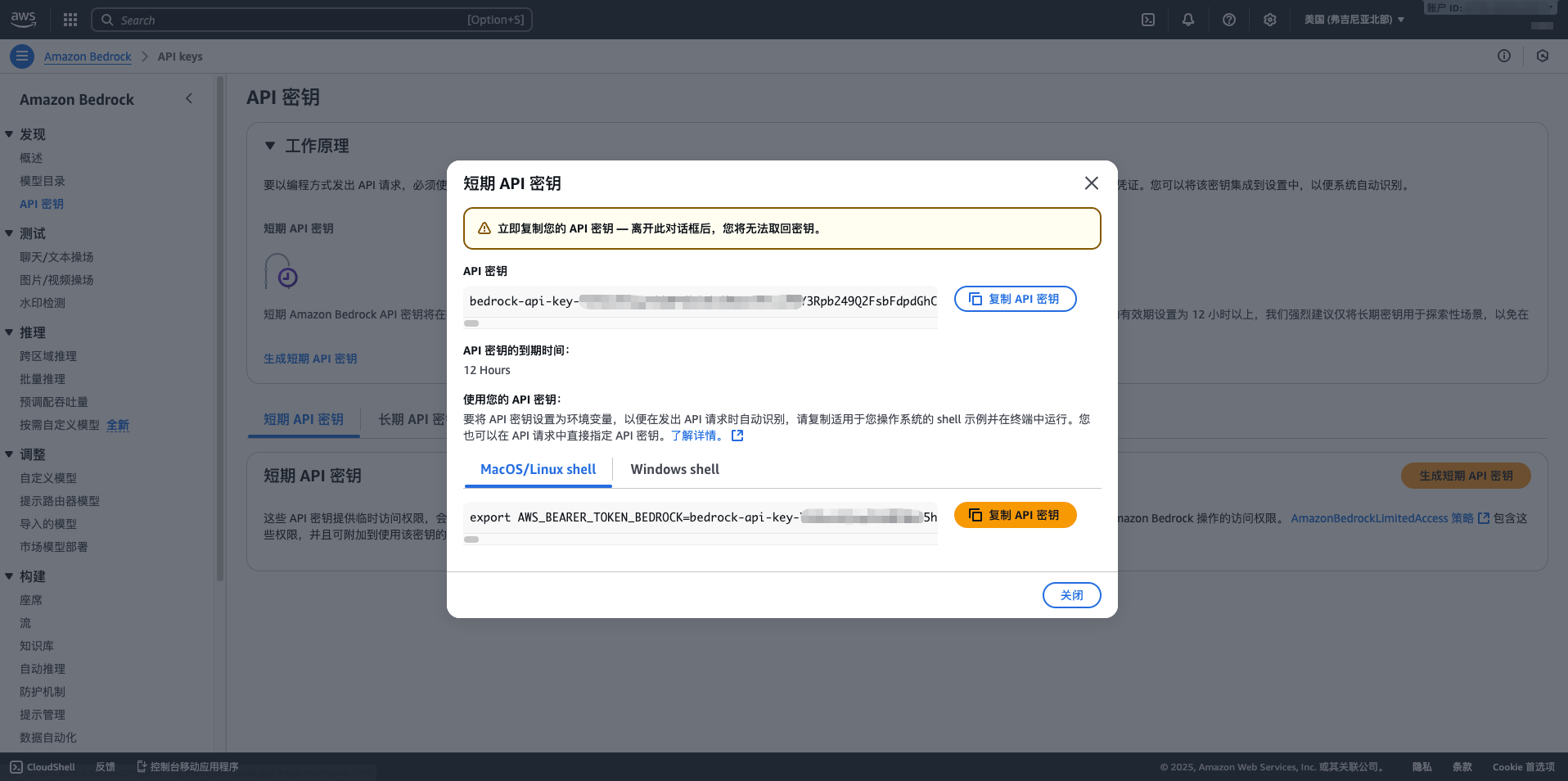
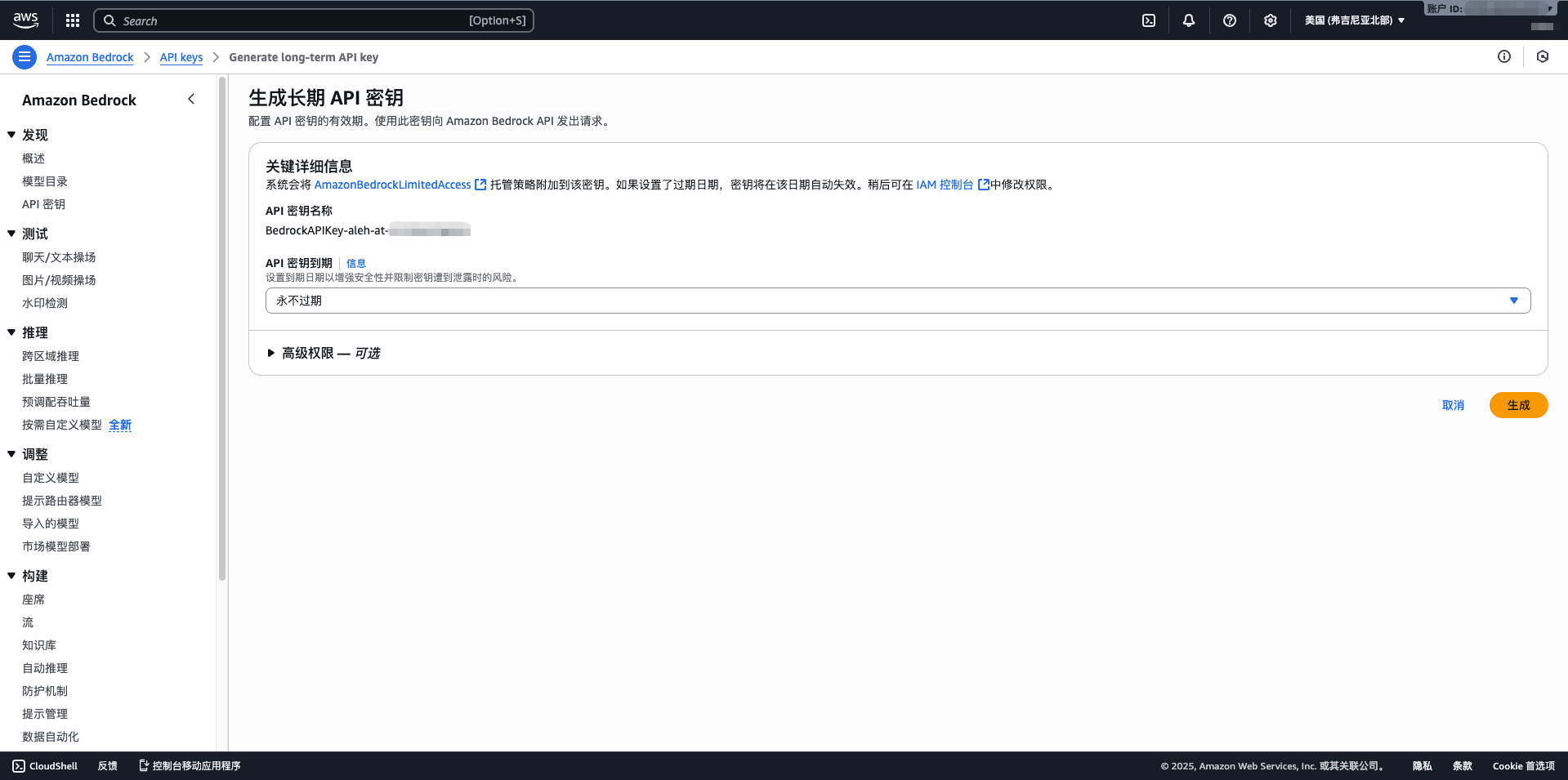
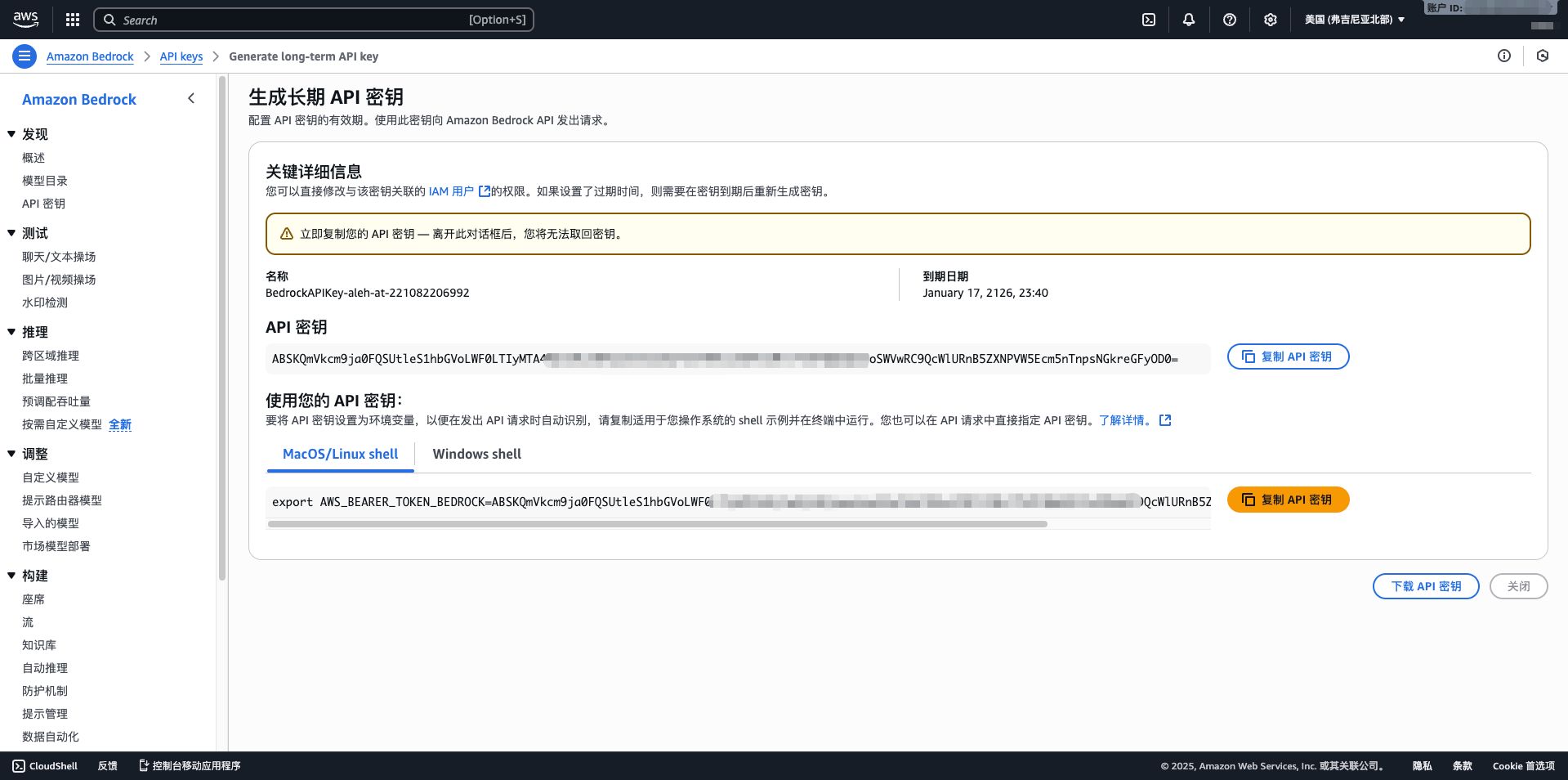
- 完成建立,記錄 Access Key ID 和 Secret Access Key
2. 在 CueMate 中配置 Bedrock 模型
2.1 進入模型設定頁面
登入 CueMate 系統後,點選右上角下拉選單的 模型設定。
2.2 新增新模型
點選右上角的 新增模型 按鈕。

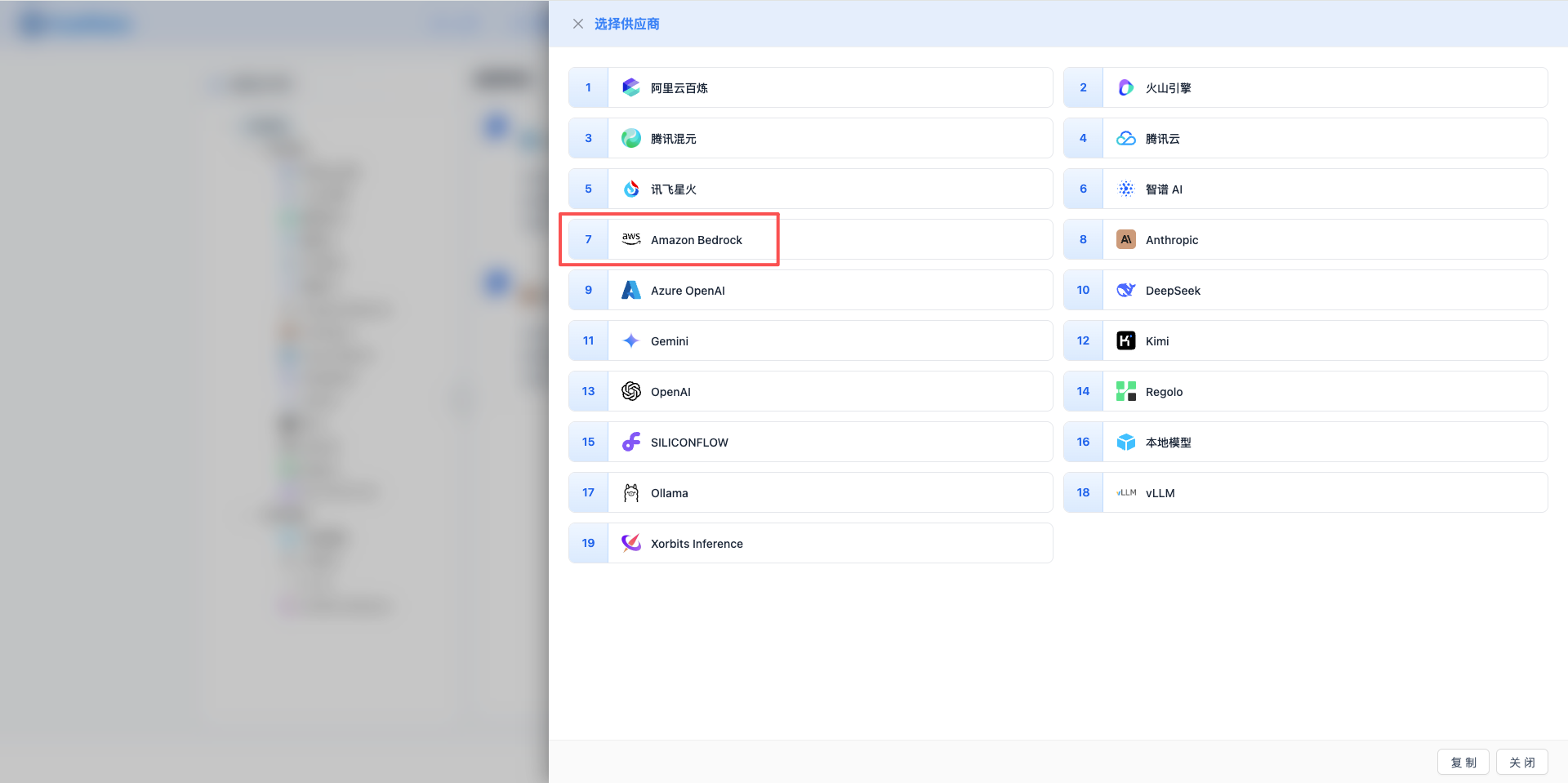
2.3 選擇 Amazon Bedrock 服務商
在彈出的對話方塊中:
- 服務商型別:選擇 Amazon Bedrock
- 點選後 自動進入下一步
2.4 填寫配置資訊
在配置頁面填寫以下資訊:
基礎配置
- 模型名稱:為這個模型配置起個名字(例如:Bedrock Claude 4.5 Sonnet)
- API Key:貼上從 AWS Bedrock 獲取的長期 API 金鑰
- AWS Region:選擇區域(如 us-east-1,預設值)
- 模型版本:選擇或輸入要使用的模型ID,常用模型包括:
anthropic.claude-sonnet-4-5-20250929-v1:0:Claude 4.5 Sonnet(最新,最大輸出64K)anthropic.claude-haiku-4-5-20251001-v1:0:Claude 4.5 Haiku(快速,最大輸出64K)anthropic.claude-opus-4-1-20250805-v1:0:Claude 4.1 Opus(高效能,最大輸出32K)anthropic.claude-3-5-sonnet-20241022-v2:0:Claude 3.5 Sonnet(最大輸出64K)amazon.nova-pro-v1:0:Amazon Nova Pro(多模態,最大輸出8K)meta.llama3-1-405b-instruct-v1:0:Llama 3.1 405B(超大規模,最大輸出8K)mistral.mistral-large-2407-v1:0:Mistral Large(高效能,最大輸出8K)
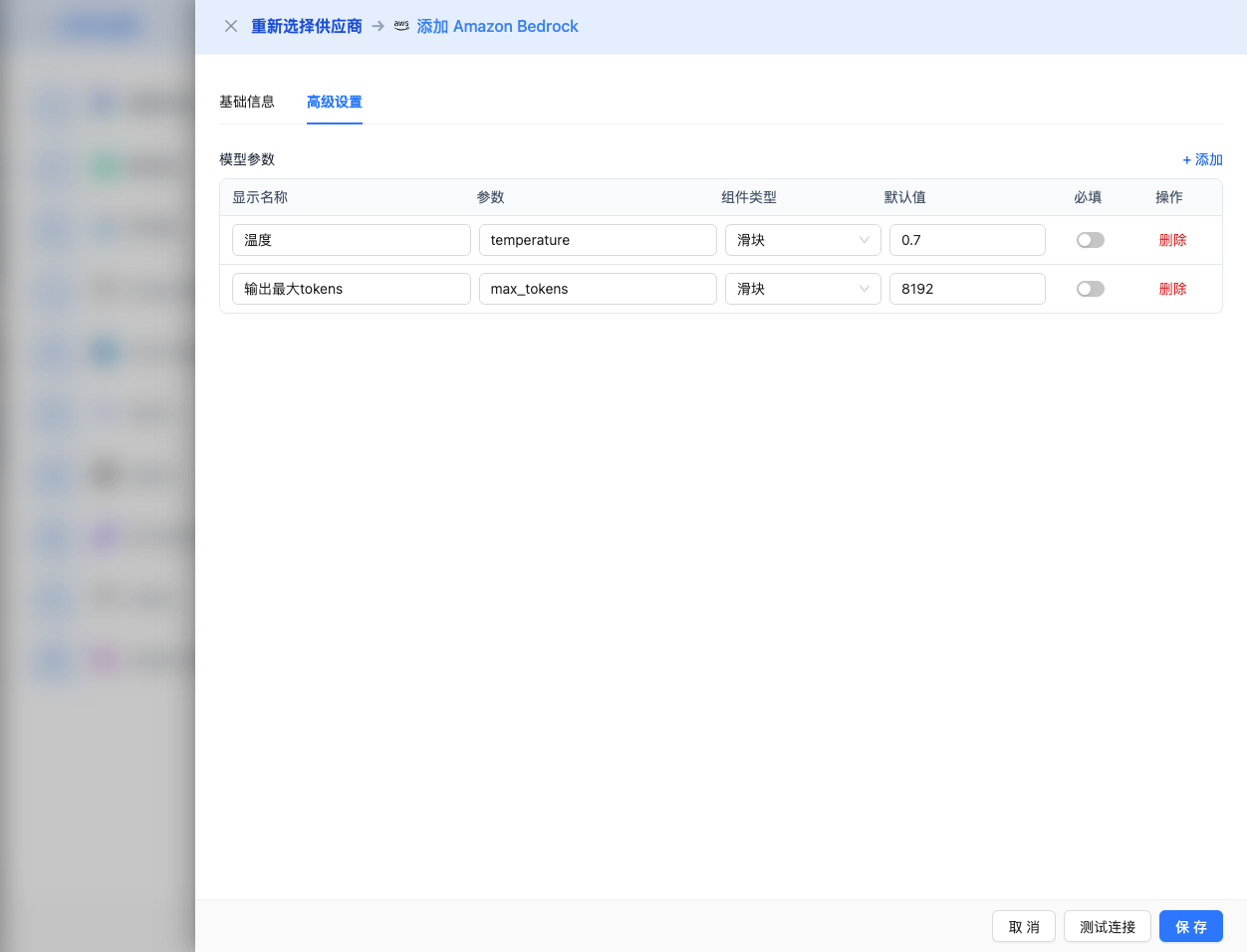
高階配置(可選)
展開 高階配置 面板,可以調整以下引數:
CueMate 介面可調引數:
溫度(temperature):控制輸出隨機性
- 範圍:0-2(根據模型系列而定)
- 推薦值:0.7
- 作用:值越高輸出越隨機創新,值越低輸出越穩定保守
- 模型範圍:
- Claude 系列:0-1
- Llama 系列:0-2
- Mistral 系列:0-1
- DeepSeek 系列:0-2
- Amazon Titan 系列:0-1
- 使用建議:
- 創意寫作/頭腦風暴:0.8-1.2(根據模型上限)
- 常規對話/問答:0.6-0.8
- 程式碼生成/精確任務:0.3-0.5
輸出最大 tokens(max_tokens):限制單次輸出長度
- 範圍:256 - 65536(根據模型而定)
- 推薦值:8192
- 作用:控制模型單次響應的最大字數
- 模型限制:
- Claude 4.5 Sonnet/Haiku: 最大 65536 (64K tokens)
- Claude 4 Opus: 最大 32768 (32K tokens)
- Claude 4 Sonnet: 最大 65536 (64K tokens)
- Claude 3.7 Sonnet: 最大 65536 (64K tokens)
- Claude 3.5 Sonnet: 最大 65536 (64K tokens)
- Claude 3.5 Haiku: 最大 8192 (8K tokens)
- Claude 3 Opus/Sonnet/Haiku: 最大 4096 (4K tokens)
- Amazon Nova 全系列: 最大 8192 (8K tokens)
- Amazon Titan 全系列: 最大 8192 (8K tokens)
- Meta Llama 全系列: 最大 8192 (8K tokens)
- Mistral 全系列: 最大 8192 (8K tokens)
- DeepSeek 全系列: 最大 8192 (8K tokens)
- AI21 Jamba 系列: 最大 4096 (4K tokens)
- Cohere Command 系列: 最大 4096 (4K tokens)
- Qwen 全系列: 最大 8192 (8K tokens)
- 使用建議:
- 簡短問答:1024-2048
- 常規對話:4096-8192
- 長文生成:16384-32768
- 超長文件:65536(僅 Claude 4.5/4/3.7/3.5 Sonnet)
AWS Bedrock API 支援的其他高階引數:
雖然 CueMate 介面只提供 temperature 和 max_tokens 調整,但如果你透過 API 直接呼叫 AWS Bedrock,不同模型系列還支援以下高階引數:
Anthropic Claude 系列引數
top_p(nucleus sampling)
- 範圍:0-1
- 預設值:1
- 作用:從機率累積達到 p 的最小候選集中取樣
- 與 temperature 的關係:通常只調整其中一個
- 使用建議:
- 保持多樣性:0.9-0.95
- 更保守的輸出:0.7-0.8
top_k
- 範圍:0-500
- 預設值:250
- 作用:從機率最高的 k 個候選詞中取樣
- 使用建議:
- 更多樣化:300-500
- 更保守:50-150
stop_sequences(停止序列)
- 型別:字串陣列
- 預設值:
["\n\nHuman:"] - 作用:當生成內容包含指定字串時停止
- 最大數量:4 個
- 示例:
["###", "使用者:", "\n\n"]
Meta Llama 系列引數
top_p(nucleus sampling)
- 範圍:0-1
- 預設值:0.9
- 作用:從機率累積達到 p 的最小候選集中取樣
top_k
- 範圍:1-500
- 預設值:50
- 作用:從機率最高的 k 個候選詞中取樣
Amazon Titan 系列引數
topP(nucleus sampling)
- 範圍:0-1
- 預設值:1
- 作用:從機率累積達到 p 的最小候選集中取樣
stopSequences(停止序列)
- 型別:字串陣列
- 作用:當生成內容包含指定字串時停止
- 示例:
["User:", "###"]
Mistral 系列引數
top_p(nucleus sampling)
- 範圍:0-1
- 預設值:1
- 作用:從機率累積達到 p 的最小候選集中取樣
top_k
- 範圍:0-200
- 預設值:50
- 作用:從機率最高的 k 個候選詞中取樣
AWS Bedrock 通用特性:
stream(流式輸出)
- 型別:布林值
- 預設值:false
- 作用:啟用流式返回,邊生成邊返回
- CueMate 中:自動處理,無需手動設定
guardrails(安全防護)
- 型別:物件
- 作用:配置 AWS Bedrock Guardrails 進行內容過濾
- 使用場景:企業級安全合規要求
- 示例:json
{ "guardrailIdentifier": "your-guardrail-id", "guardrailVersion": "1" }
| 場景 | 模型系列 | temperature | max_tokens | top_p | top_k |
|---|---|---|---|---|---|
| 創意寫作 | Claude | 0.8-0.9 | 4096-8192 | 0.95 | 300 |
| 程式碼生成 | Claude | 0.3-0.5 | 2048-4096 | 0.9 | 100 |
| 問答系統 | Claude | 0.7 | 1024-2048 | 0.9 | 250 |
| 複雜推理 | Claude Opus | 0.7 | 32768 | 0.9 | 250 |
| 長文生成 | Claude Sonnet | 0.7 | 65536 | 0.9 | 250 |
| 快速響應 | Claude Haiku | 0.6 | 4096 | 0.9 | 200 |
| 大規模推理 | Llama 3.1 405B | 0.7 | 8192 | 0.9 | 50 |
| 多模態任務 | Nova Pro | 0.7 | 8192 | 1.0 | - |
2.5 測試連線
填寫完配置後,點選 測試連線 按鈕,驗證配置是否正確。
如果配置正確,會顯示測試成功的提示,並返回模型的響應示例。
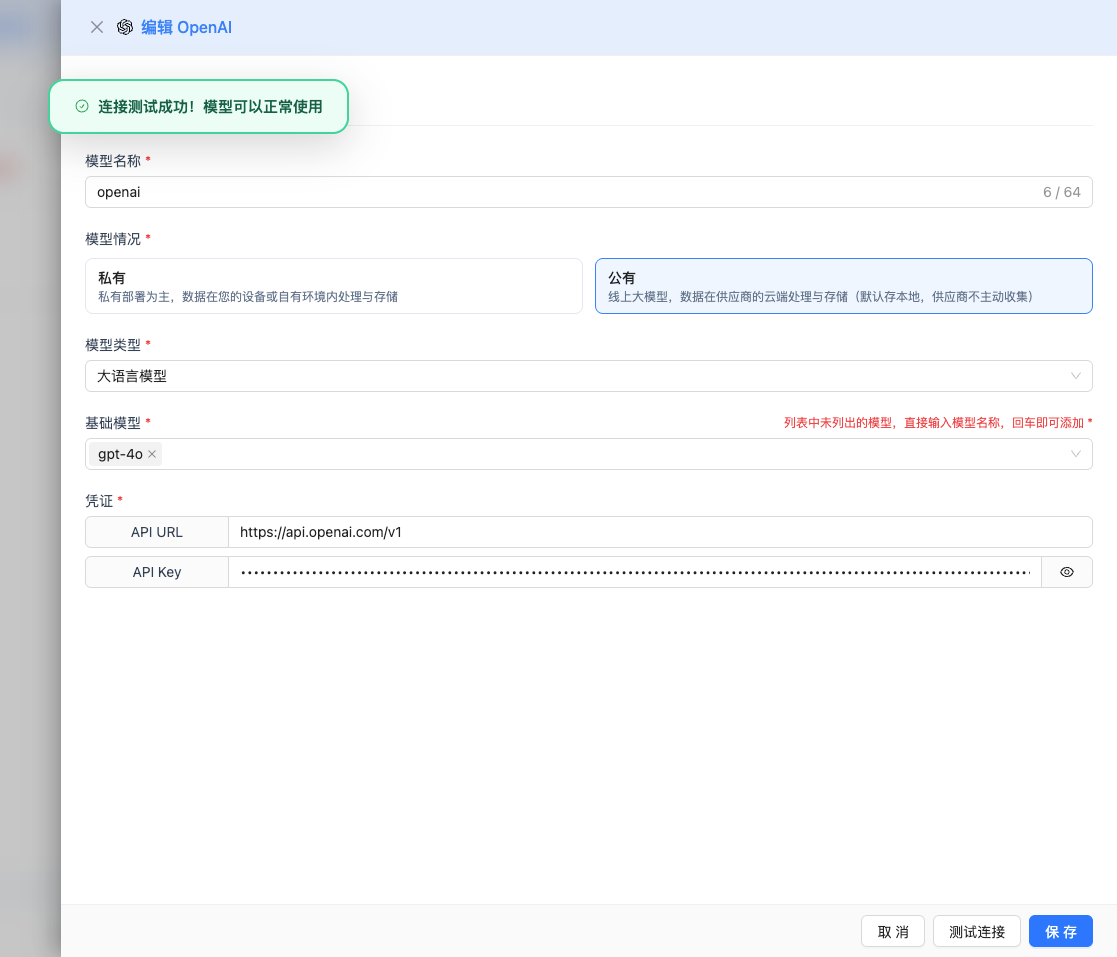
如果配置錯誤,會顯示測試錯誤的日誌,並且可以透過日誌管理,檢視具體報錯資訊。
2.6 儲存配置
測試成功後,點選 儲存 按鈕,完成模型配置。

3. 使用模型
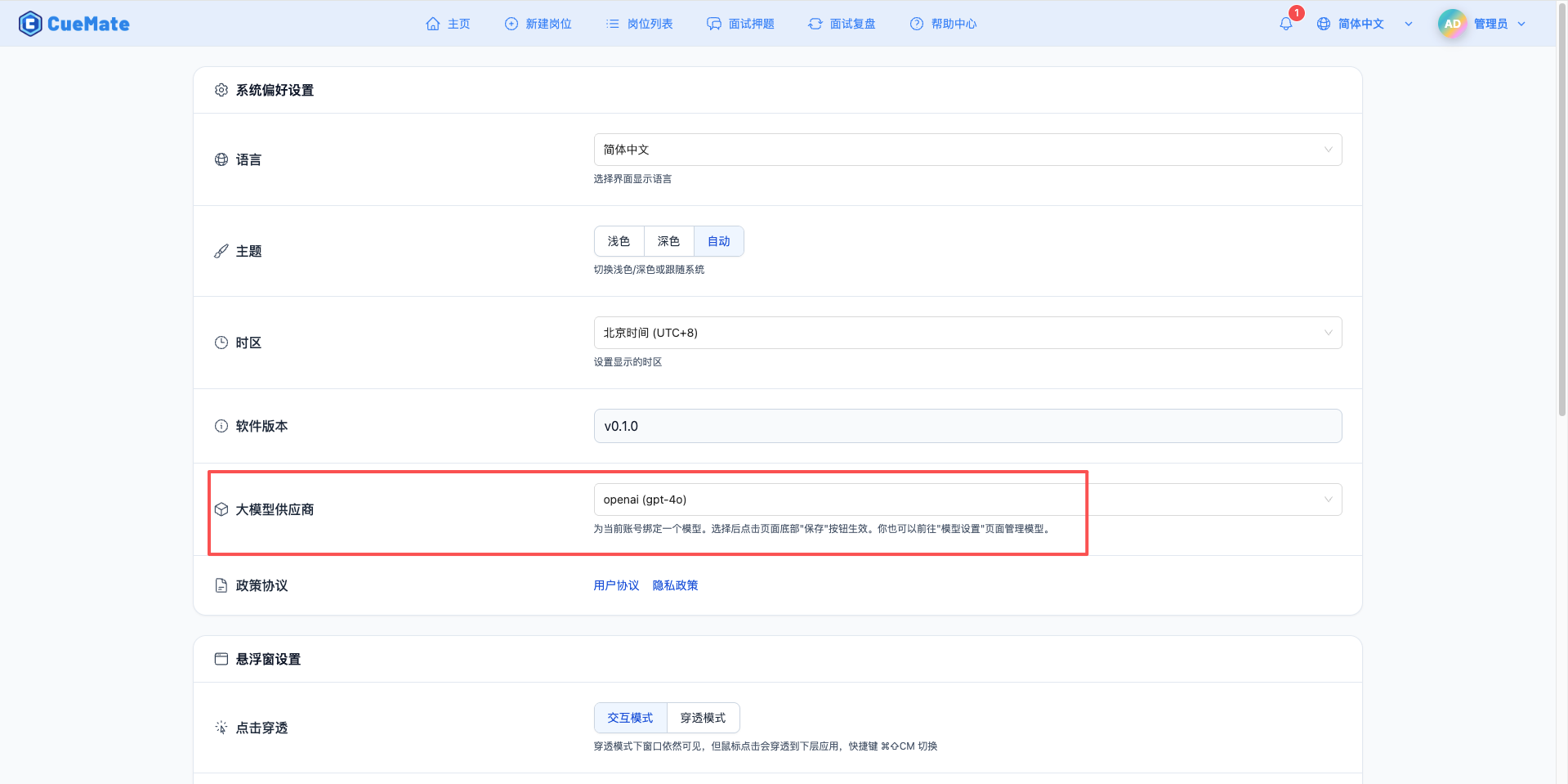
透過右上角下拉選單,進入系統設定介面,在大模型服務商欄目選擇想要使用的模型配置。
配置完成後,可以在面試訓練、問題生成等功能中選擇使用此模型, 當然也可以在面試的選項中單此選擇此次面試的模型配置。
4. 支援的模型列表
CueMate 支援 AWS Bedrock 平臺上的所有主流大模型,涵蓋 10+ 個服務商的 70+ 個模型。以下是各系列的代表性模型:
4.1 Anthropic Claude系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | Claude 4.5 Sonnet | anthropic.claude-sonnet-4-5-20250929-v1:0 | 64K tokens | 最新一代,通用場景、高效能推理 |
| 2 | Claude 4.5 Haiku | anthropic.claude-haiku-4-5-20251001-v1:0 | 64K tokens | 快速響應、高吞吐量 |
| 3 | Claude 4.1 Opus | anthropic.claude-opus-4-1-20250805-v1:0 | 32K tokens | 複雜推理、深度分析 |
| 4 | Claude 4 Opus | anthropic.claude-opus-4-20250514-v1:0 | 32K tokens | 高質量輸出 |
| 5 | Claude 4 Sonnet | anthropic.claude-sonnet-4-20250514-v1:0 | 64K tokens | 平衡效能與成本 |
| 6 | Claude 3.7 Sonnet | anthropic.claude-3-7-sonnet-20250219-v1:0 | 64K tokens | 增強版通用模型 |
| 7 | Claude 3.5 Sonnet v2 | anthropic.claude-3-5-sonnet-20241022-v2:0 | 64K tokens | 通用場景、高效能 |
| 8 | Claude 3.5 Sonnet v1 | anthropic.claude-3-5-sonnet-20240620-v1:0 | 64K tokens | 通用場景 |
| 9 | Claude 3.5 Haiku | anthropic.claude-3-5-haiku-20241022-v1:0 | 8K tokens | 快速響應 |
| 10 | Claude 3 Opus | anthropic.claude-3-opus-20240229-v1:0 | 4K tokens | 複雜推理 |
| 11 | Claude 3 Sonnet | anthropic.claude-3-sonnet-20240229-v1:0 | 4K tokens | 平衡效能 |
| 12 | Claude 3 Haiku | anthropic.claude-3-haiku-20240307-v1:0 | 4K tokens | 輕量級任務 |
4.2 Amazon Nova系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | Nova Premier | amazon.nova-premier-v1:0 | 8K tokens | 旗艦級多模態模型 |
| 2 | Nova Pro | amazon.nova-pro-v1:0 | 8K tokens | 高效能多模態處理 |
| 3 | Nova Lite | amazon.nova-lite-v1:0 | 8K tokens | 輕量級多模態任務 |
| 4 | Nova Micro | amazon.nova-micro-v1:0 | 8K tokens | 超輕量級場景 |
| 5 | Nova Sonic | amazon.nova-sonic-v1:0 | 8K tokens | 快速響應 |
4.3 Amazon Titan系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | Titan Premier | amazon.titan-text-premier-v1:0 | 8K tokens | 企業級應用 |
| 2 | Titan Express | amazon.titan-text-express-v1 | 8K tokens | 快速響應 |
| 3 | Titan Lite | amazon.titan-text-lite-v1 | 8K tokens | 輕量級任務 |
4.4 Meta Llama系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | Llama 4 Scout 17B | meta.llama4-scout-17b-instruct-v1:0 | 8K tokens | 新一代中等規模模型 |
| 2 | Llama 4 Maverick 17B | meta.llama4-maverick-17b-instruct-v1:0 | 8K tokens | 新一代高效能模型 |
| 3 | Llama 3.3 70B | meta.llama3-3-70b-instruct-v1:0 | 8K tokens | 增強版大規模推理 |
| 4 | Llama 3.2 90B | meta.llama3-2-90b-instruct-v1:0 | 8K tokens | 大規模推理 |
| 5 | Llama 3.2 11B | meta.llama3-2-11b-instruct-v1:0 | 8K tokens | 中等規模任務 |
| 6 | Llama 3.2 3B | meta.llama3-2-3b-instruct-v1:0 | 8K tokens | 輕量級任務 |
| 7 | Llama 3.2 1B | meta.llama3-2-1b-instruct-v1:0 | 8K tokens | 超輕量級 |
| 8 | Llama 3.1 405B | meta.llama3-1-405b-instruct-v1:0 | 8K tokens | 超大規模推理 |
| 9 | Llama 3.1 70B | meta.llama3-1-70b-instruct-v1:0 | 8K tokens | 大規模任務 |
| 10 | Llama 3.1 8B | meta.llama3-1-8b-instruct-v1:0 | 8K tokens | 標準任務 |
| 11 | Llama 3 70B | meta.llama3-70b-instruct-v1:0 | 8K tokens | 經典大規模模型 |
| 12 | Llama 3 8B | meta.llama3-8b-instruct-v1:0 | 8K tokens | 經典標準模型 |
4.5 Mistral AI系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | Pixtral Large 2502 | mistral.pixtral-large-2502-v1:0 | 8K tokens | 多模態大模型 |
| 2 | Mistral Large 2407 | mistral.mistral-large-2407-v1:0 | 8K tokens | 高效能場景 |
| 3 | Mistral Large 2402 | mistral.mistral-large-2402-v1:0 | 8K tokens | 通用場景 |
| 4 | Mistral Small 2402 | mistral.mistral-small-2402-v1:0 | 8K tokens | 輕量高效 |
| 5 | Mixtral 8x7B | mistral.mixtral-8x7b-instruct-v0:1 | 4K tokens | 混合專家模型 |
| 6 | Mistral 7B | mistral.mistral-7b-instruct-v0:2 | 8K tokens | 輕量級任務 |
4.6 AI21 Labs系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | Jamba 1.5 Large | ai21.jamba-1-5-large-v1:0 | 4K tokens | 大規模混合架構 |
| 2 | Jamba 1.5 Mini | ai21.jamba-1-5-mini-v1:0 | 4K tokens | 輕量級混合架構 |
4.7 Cohere系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | Command R+ | cohere.command-r-plus-v1:0 | 4K tokens | 增強版命令模型 |
| 2 | Command R | cohere.command-r-v1:0 | 4K tokens | 標準命令模型 |
4.8 DeepSeek系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | DeepSeek R1 | deepseek.r1-v1:0 | 8K tokens | 推理最佳化版本 |
| 2 | DeepSeek V3 | deepseek.v3-v1:0 | 8K tokens | 最新一代模型 |
4.9 Qwen系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | Qwen 3 Coder 480B | qwen.qwen3-coder-480b-a35b-v1:0 | 8K tokens | 超大規模程式碼生成 |
| 2 | Qwen 3 235B | qwen.qwen3-235b-a22b-2507-v1:0 | 8K tokens | 超大規模通用推理 |
| 3 | Qwen 3 Coder 30B | qwen.qwen3-coder-30b-a3b-v1:0 | 8K tokens | 程式碼生成專用 |
| 4 | Qwen 3 32B | qwen.qwen3-32b-v1:0 | 8K tokens | 標準通用模型 |
4.10 OpenAI系列
| 序號 | 模型名稱 | 模型 ID | 最大輸出 | 適用場景 |
|---|---|---|---|---|
| 1 | GPT-OSS 120B | openai.gpt-oss-120b-1:0 | 4K tokens | 開源版GPT大模型 |
| 2 | GPT-OSS 20B | openai.gpt-oss-20b-1:0 | 4K tokens | 開源版GPT中等模型 |
注意事項:
- 以上模型均需要在 AWS Bedrock 控制檯申請訪問許可權後才能使用
- 不同模型的定價不同,請參考 AWS Bedrock 定價說明
- 實際最大輸出取決於您在 CueMate 配置中設定的 Max Tokens 引數
- 部分模型可能僅在特定 AWS 區域可用,建議使用 us-east-1 獲得最佳模型覆蓋
5. 常見問題
5.1 模型訪問未授權
現象:提示模型訪問被拒絕
解決方案:
- 在Bedrock控制檯檢查模型訪問狀態
- 確認已請求並獲得模型訪問許可權
- 等待稽覈透過(部分模型可能需要1-2個工作日)
5.2 IAM許可權不足
現象:提示許可權錯誤
解決方案:
- 確認IAM使用者已附加 AmazonBedrockFullAccess 策略
- 檢查訪問金鑰是否正確
- 驗證區域設定是否與模型可用區域匹配
5.3 區域不支援
現象:提示服務在當前區域不可用
解決方案:
- 使用支援Bedrock的區域(推薦 us-east-1 或 us-west-2)
- 修改API URL中的區域程式碼
- 確認選擇的模型在該區域可用
5.4 配額限制
現象:提示超出請求配額
解決方案:
- 在Bedrock控制檯檢視配額使用情況
- 申請提高TPM(每分鐘Token數)或RPM(每分鐘請求數)限制
- 最佳化請求頻率