模型設定
模型設定用於配置和管理所有大語言模型(LLM),支援公有云模型(OpenAI、Claude、DeepSeek)和私有部署模型(Ollama、vLLM、Xinference)。透過統一的配置介面,您可以新增多個模型、管理憑證、測試連線狀態、配置模型引數。
1. 頁面佈局
1.1 進入模型設定頁面
點選頂部下拉選單選單中的"模型設定",進入模型管理頁面。
1.2 佈局結構
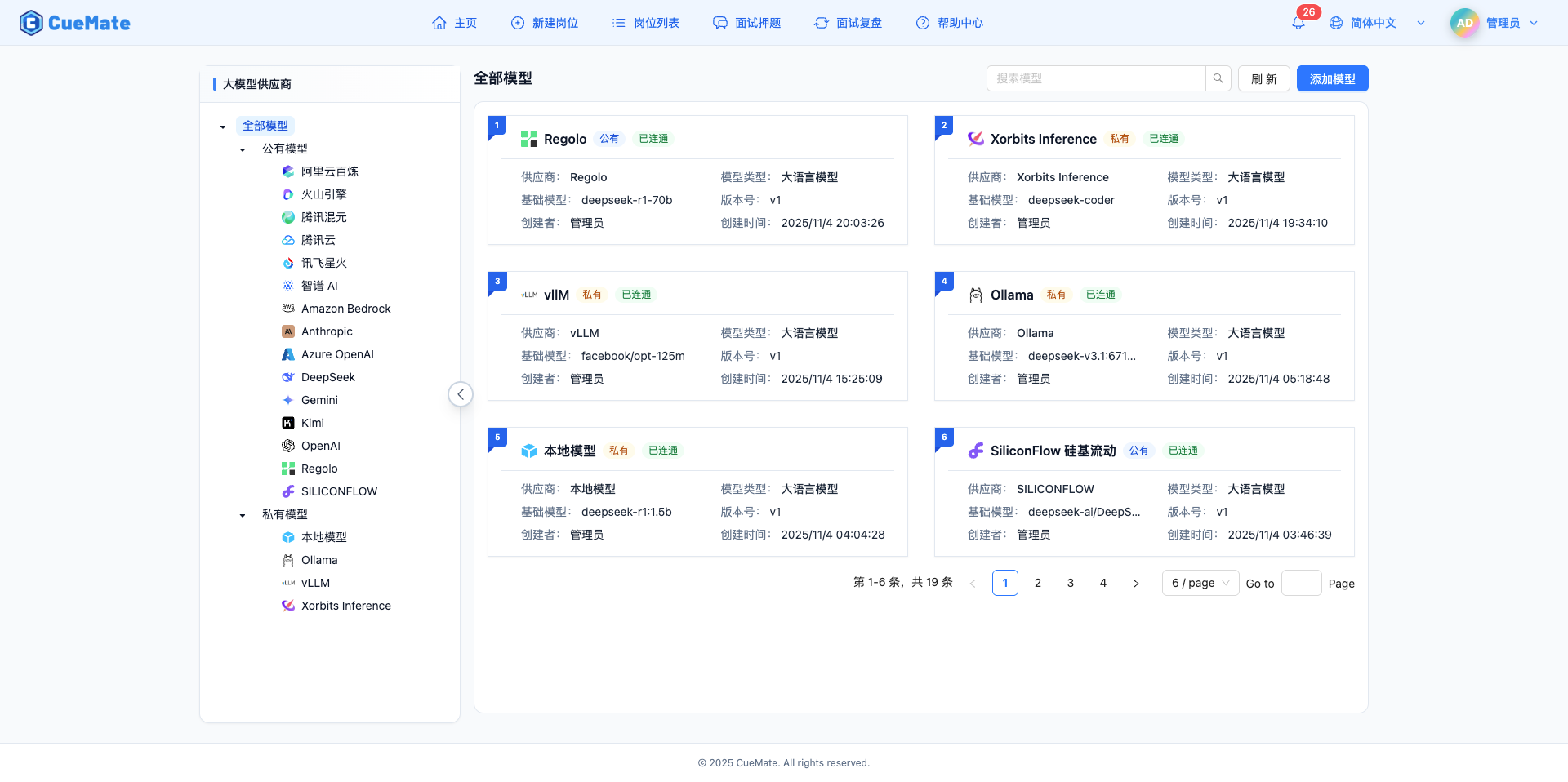
頁面採用左右分欄設計:
左側導航區域
- 樹形結構展示服務商分類
- 全部模型、公有模型、私有模型三級分類
- 每個服務商帶有品牌圖示
- 支援摺疊/展開側邊欄
右側內容區域
- 頂部:標題、搜尋框、重新整理和新增按鈕
- 主體:卡片式模型列表,桌面端 2 列布局
- 底部:分頁導航
模型卡片資訊
- 左上角序號、服務商圖示和模型名稱
- 公有/私有標籤、連通狀態標籤(已連通/不可用)
- 服務商、模型型別、基礎模型、版本號、建立者、建立時間
- 懸停顯示操作按鈕:測試連線、編輯、刪除
2. 瀏覽模型
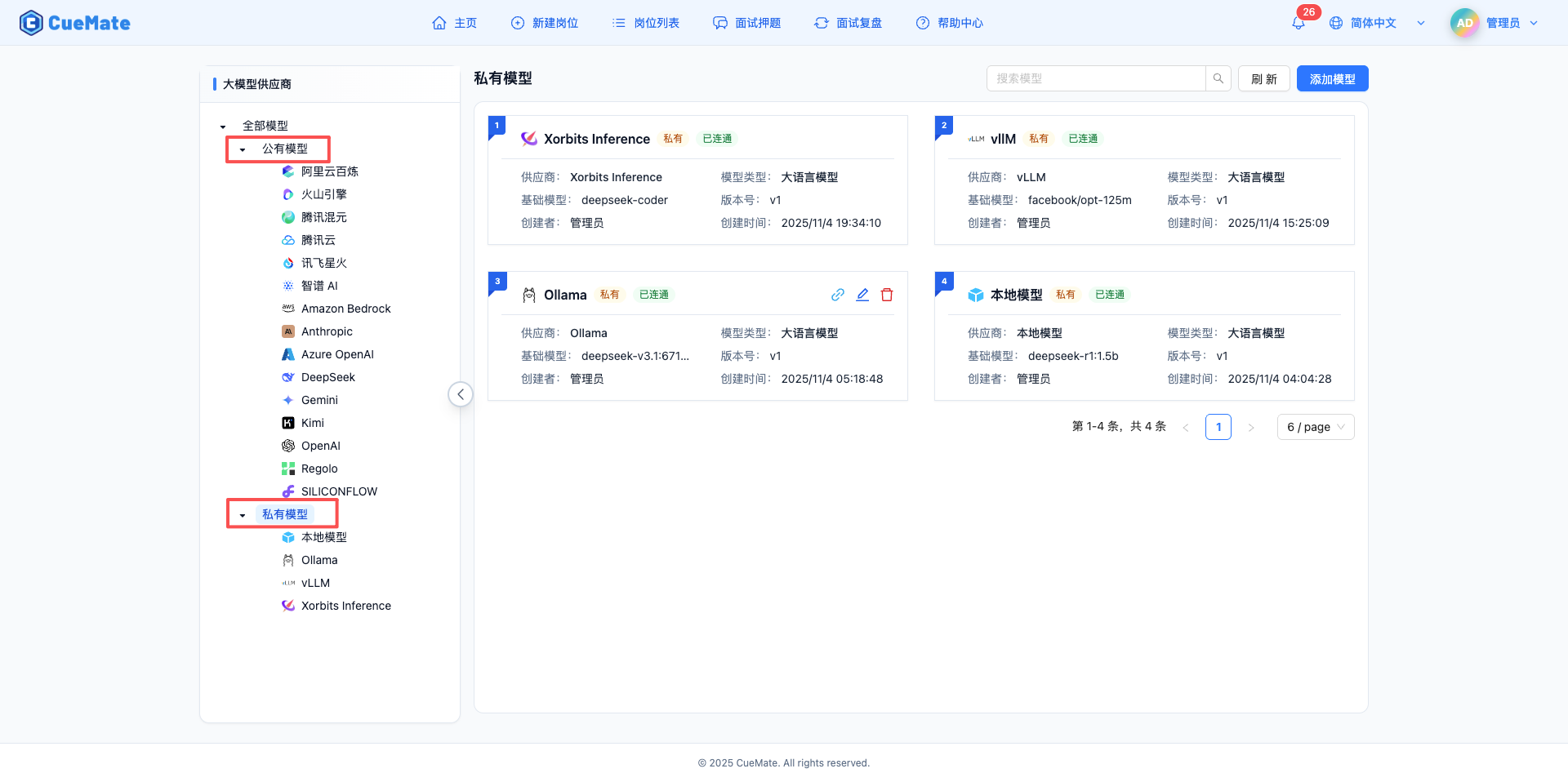
2.1 使用導航樹篩選
左側導航樹以樹形結構組織模型:
全部模型
├── 公有模型
│ ├── OpenAI
│ ├── Claude
│ ├── DeepSeek
│ └── ...
└── 私有模型
├── Ollama
├── vLLM
└── ...操作方式
- 點選"全部模型"顯示所有模型
- 點選"公有模型"或"私有模型"顯示該類別模型
- 點選具體服務商只顯示該服務商的模型
- 選中節點高亮顯示
公有 vs 私有
- 公有模型:雲端服務,資料在服務商雲端處理(如 OpenAI、Claude)
- 私有模型:本地部署,資料在您的裝置內處理(如 Ollama、vLLM)
2.2 檢視模型列表
右側以卡片形式展示模型,每個卡片包含:
- 序號和服務商圖示
- 模型名稱和型別標籤
- 連通狀態(綠色"已連通"/紅色"不可用")
- 詳細資訊(服務商、基礎模型、版本、建立者、時間)
響應式佈局
- 大螢幕:2 列卡片
- 小螢幕:1 列卡片
2.3 搜尋和篩選
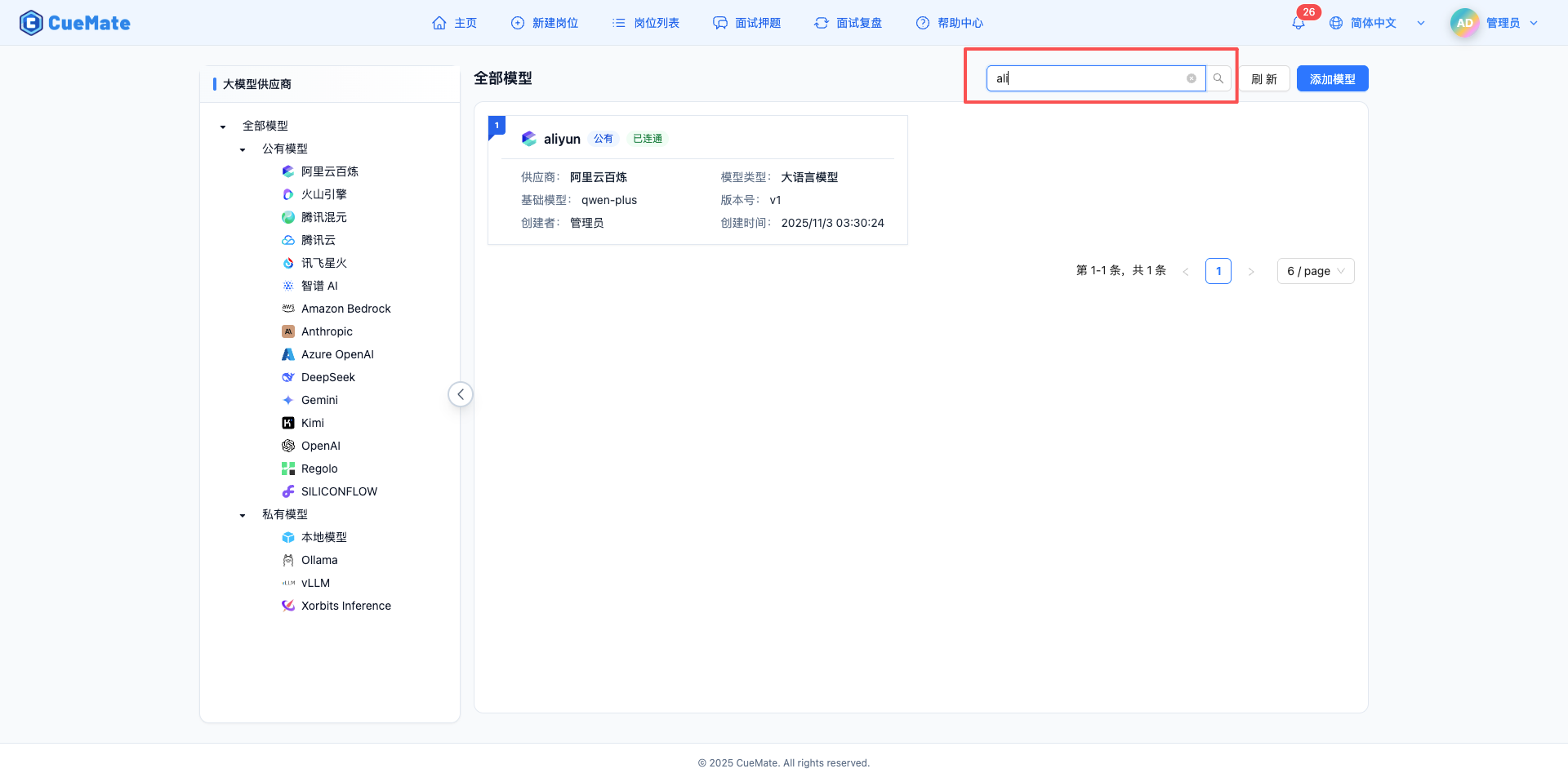
搜尋功能
- 位置:右上角搜尋框
- 搜尋範圍:模型名稱
- 支援實時搜尋和清除
篩選組合
- 搜尋和導航篩選可同時使用
- 例如:選中"公有模型"後搜尋"GPT",只顯示公有模型中包含"GPT"的模型
重新整理列表
- 點選"重新整理"按鈕獲取最新模型狀態
- 自動重新整理:新增、編輯、刪除模型後自動重新整理
3. 新增模型
3.1 選擇服務商
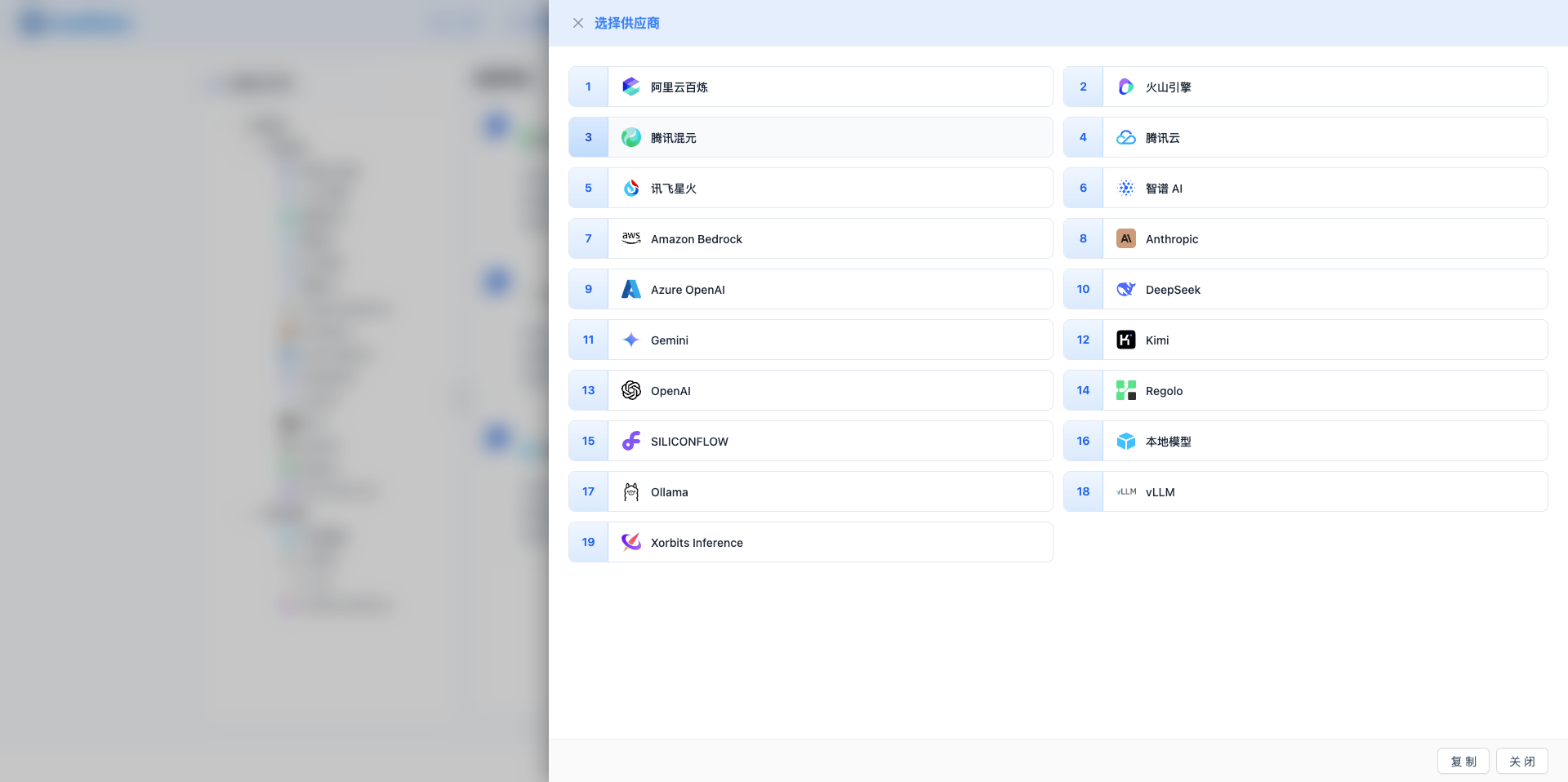
點選右上角"新增模型"按鈕,彈出服務商選擇抽屜。
服務商選擇抽屜
- 寬度:頁面的 65%
- 卡片網格:2 列布局
- 每個卡片顯示:序號、圖示、服務商名稱
- 篩選邏輯:
- 選中"公有模型"只顯示公有服務商
- 選中"私有模型"只顯示私有服務商
- 選中"全部模型"顯示所有服務商
服務商列表示例
公有云模型(16 個):
- 國際主流:OpenAI、Anthropic (Claude)、Google Gemini、DeepSeek
- 國產大廠:Moonshot (Kimi)、智譜 AI、通義千問(阿里雲百鍊)、騰訊混元、訊飛星火、火山引擎(豆包)、百度千帆、商湯日日新
- 新興平臺:百川智慧、MiniMax、階躍星辰、SiliconFlow
雲平臺模型服務(3 個):
- Azure OpenAI、Amazon Bedrock、騰訊雲
私有部署模型(5 個):
- Ollama、vLLM、Xinference、本地模型、Regolo
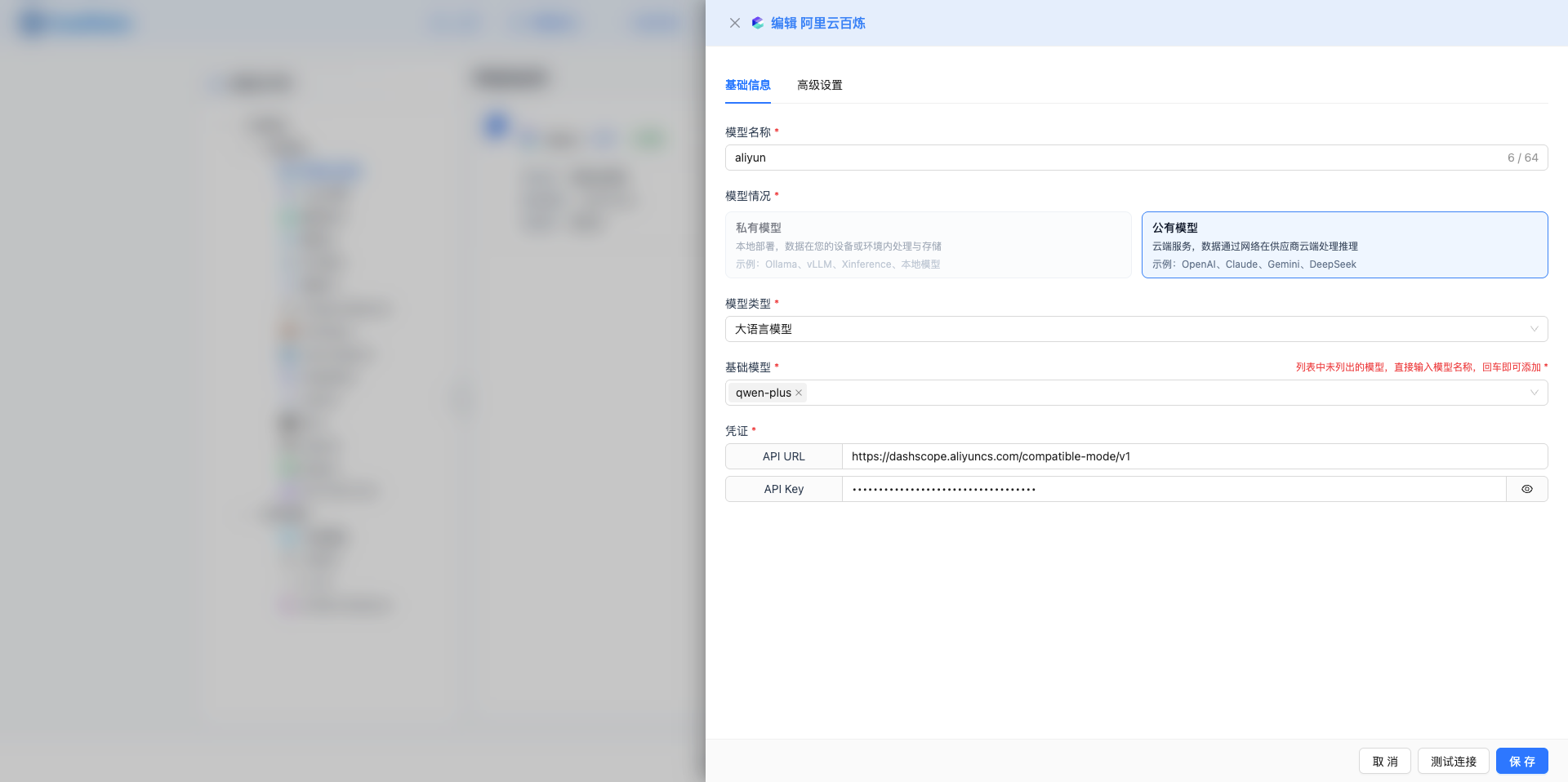
3.2 配置基礎資訊
選擇服務商後,進入配置介面(二級抽屜)。
基礎資訊
- 模型名稱(必填)
- 最多 64 個字元
- 示例:GPT-4 Turbo、Claude 3 Sonnet、DeepSeek Chat
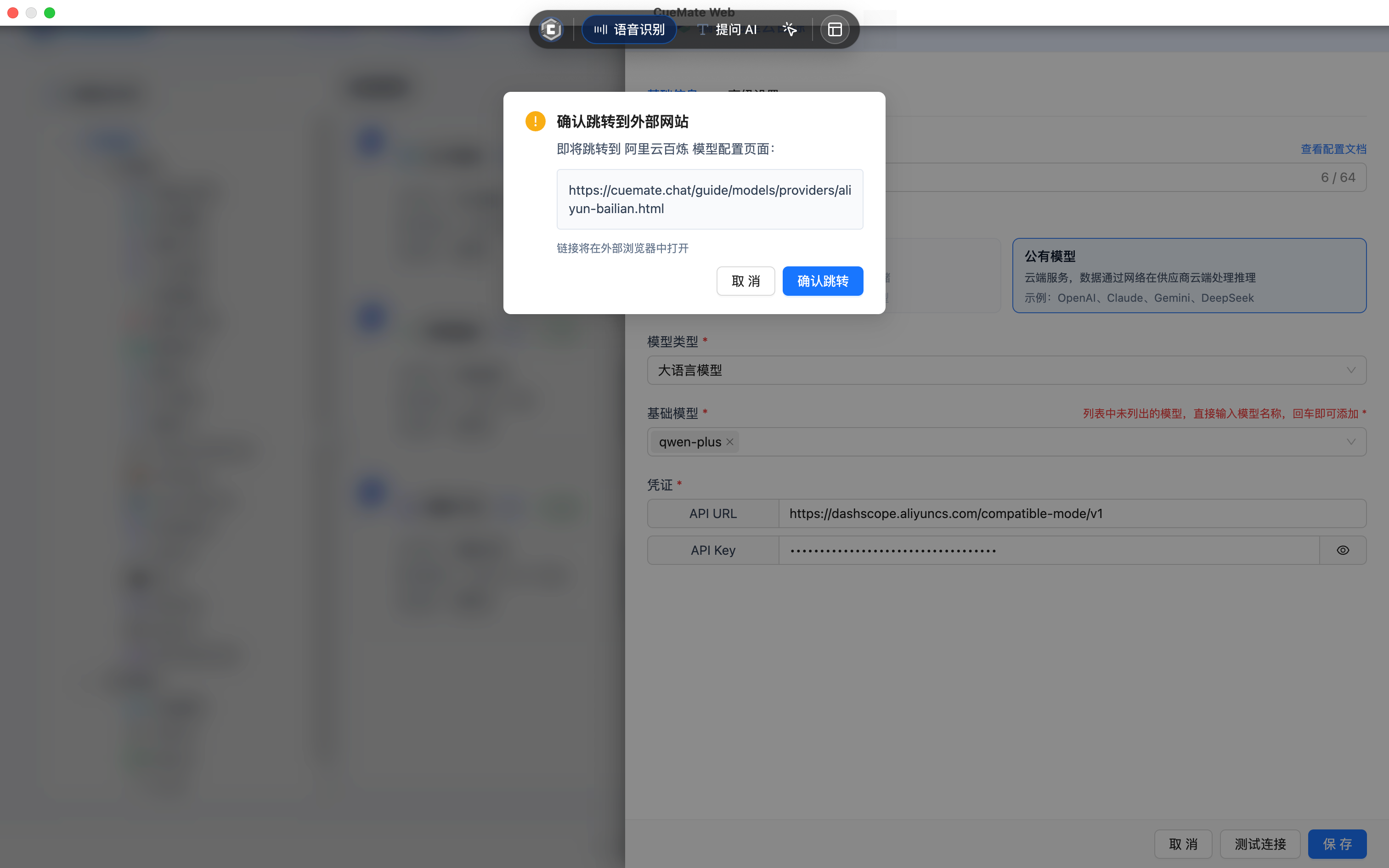
- 右上角提供"檢視配置文件"連結,點選可跳轉到對應服務商的配置說明文件
檢視配置文件
在模型名稱輸入框右上角,提供了"檢視配置文件"連結。點選後會彈出確認對話方塊,確認跳轉後將在外部瀏覽器(客戶端)或新標籤頁(網頁端)開啟對應服務商的配置說明文件。
模型情況(自動選中)
- 根據服務商型別自動選擇
- 私有模型:本地部署,資料在您的裝置或環境內處理
- 公有模型:雲端服務,資料在服務商雲端處理
模型型別(必填)
- 當前選項:大語言模型(llm)
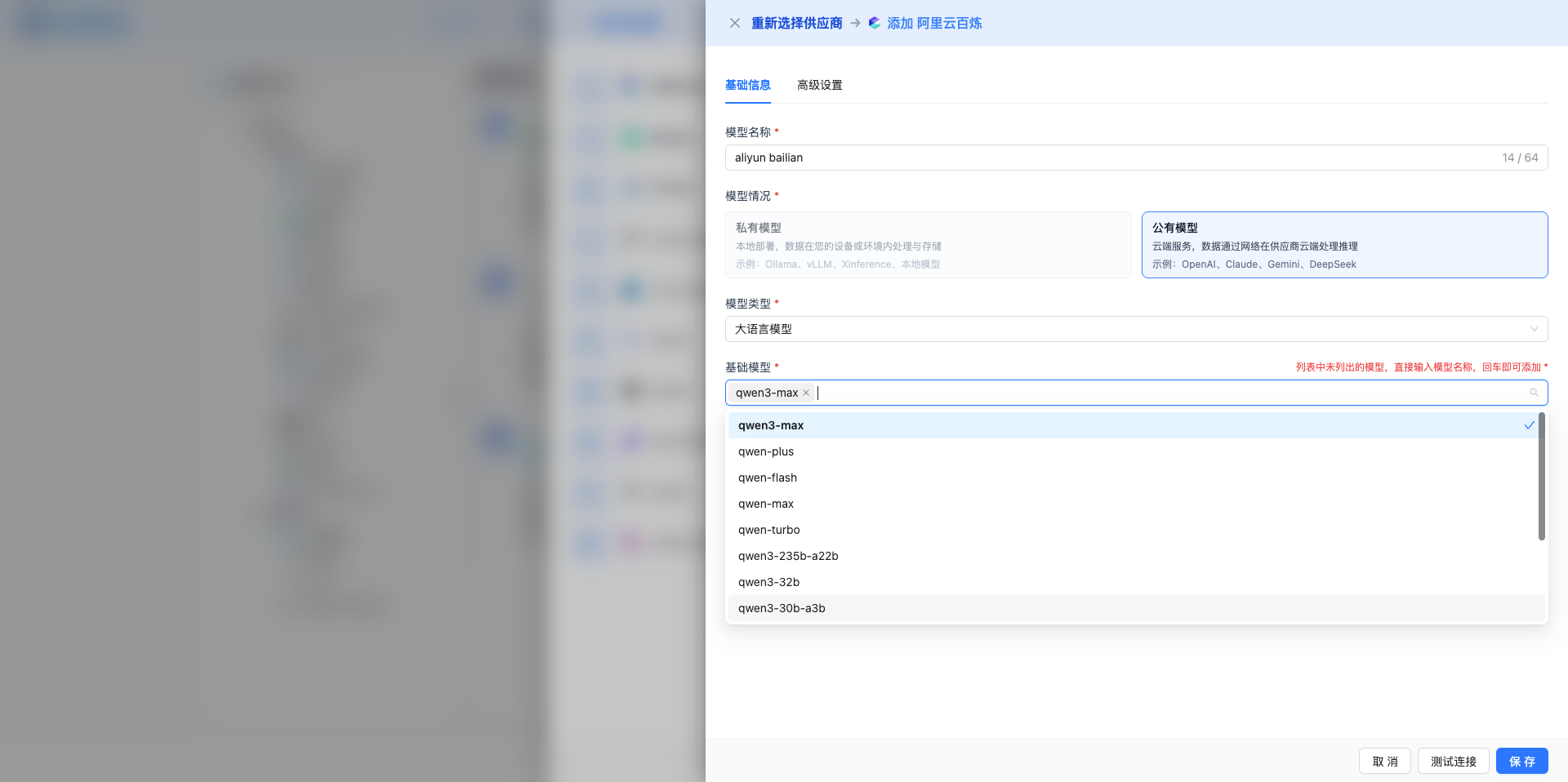
基礎模型(必填)
- 下拉選擇該服務商支援的模型
- 支援搜尋和自定義輸入
- 直接輸入模型名稱後按回車新增
- 示例:
- OpenAI:gpt-5、gpt-5-mini、gpt-4.1、gpt-4o
- Claude:claude-sonnet-4-5、claude-haiku-4-5、claude-opus-4-1
- DeepSeek:deepseek-chat、deepseek-coder
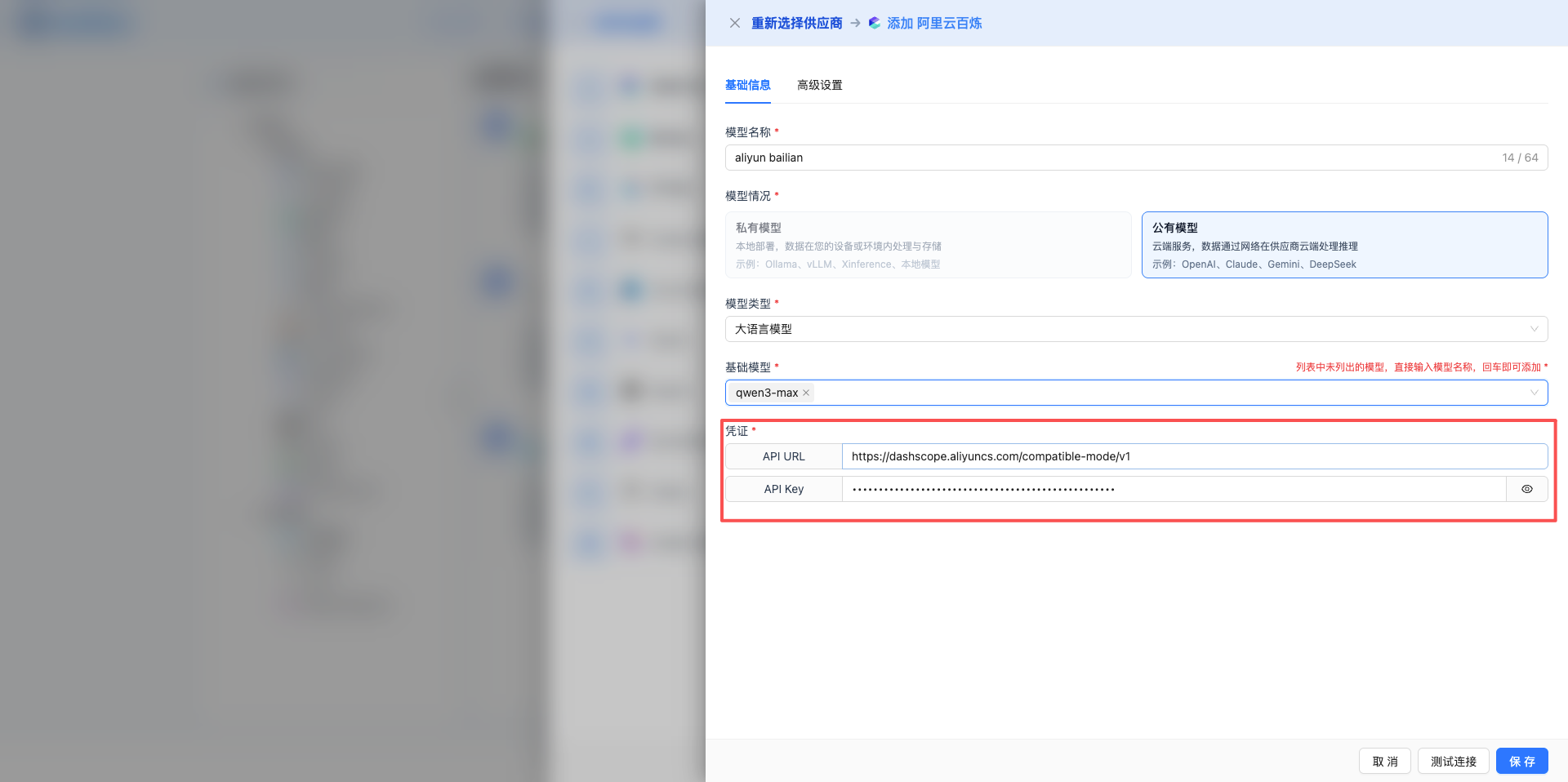
3.3 配置憑證
選擇基礎模型後,自動顯示憑證配置區域。
常見憑證欄位
API Key(密碼型別)
- 輸入框預設隱藏顯示(• • • •)
- 點選眼睛圖示切換顯示/隱藏
- 佔位符:提示格式如 "sk-xxx"
- 必填欄位,未填寫顯示紅色邊框
Base URL(文字型別,會帶出預設值,正常情況下不需要修改)
- 用於私有部署或自定義端點
- 示例:
- OpenAI:https://api.openai.com/v1
- Ollama:http://localhost:11434
- vLLM:http://localhost:8000
其他欄位
- 根據服務商不同,可能包含:Organization ID、Project ID、Access Token、Secret Key
- 每個欄位帶有清晰標籤和佔位符提示
3.4 配置高階引數
點選"高階設定"標籤頁,配置模型執行引數(正常帶出對應模型的預設值,自定義模型沒有預設值,需要自己填寫)。
參數列格
- 表格列:顯示名稱、引數、元件型別、預設值、必填、操作
- 右上角"+ 新增"按鈕新增新引數
- 每行右側"刪除"按鈕刪除該引數
引數配置項
顯示名稱(label)
- 引數在介面上顯示的名稱
- 示例:溫度、最大 Token 數、Top P
引數(param_key)
- 實際傳遞給模型的引數鍵名
- 示例:temperature、max_tokens、top_p、frequency_penalty
- 必須與模型 API 文件一致
元件型別(ui_type)
- 選項:輸入框(input)、滑塊(slider)、開關(switch)、下拉選擇(select)
- 決定該引數在對話設定中的展示形式
預設值(value)
- 引數的預設值
- 示例:temperature:0.7,max_tokens:2048
必填(required)
- 開關控制元件,開啟表示必填項
常用引數示例
顯示名稱:溫度
引數:temperature
元件型別:滑塊
預設值:0.7
必填:是
顯示名稱:最大 Token 數
引數:max_tokens
元件型別:輸入框
預設值:2048
必填:否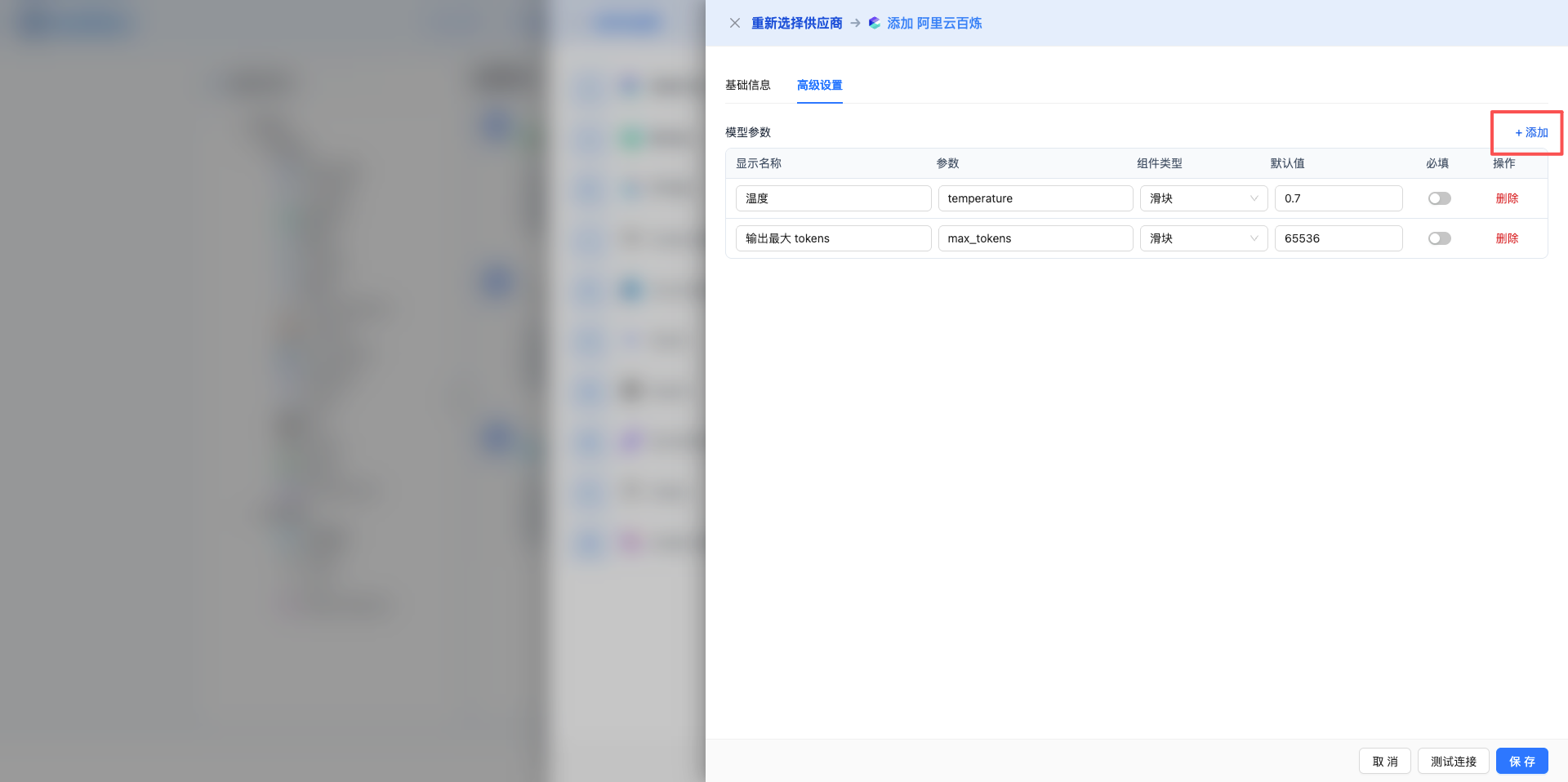
4. 測試連線
4.1 測試未儲存的配置
配置完模型後,建議先測試連線再儲存。
測試按鈕
- 位於抽屜底部,"取消"和"儲存"按鈕之間
- 按鈕文字:"測試連線" / "測試中..."
測試前驗證
- 檢查服務商、基礎模型是否已選擇
- 檢查必填憑證欄位是否已填寫
- 未透過驗證顯示警告提示
測試過程
- 點選"測試連線"按鈕
- 顯示全屏遮罩層:"正在測試連通性"
- 後臺傳送測試請求驗證配置
- 測試成功:顯示綠色成功提示
- 測試失敗:顯示紅色錯誤提示和具體原因
測試意義
- 驗證 API Key 是否有效
- 驗證 Base URL 是否可訪問
- 驗證模型名稱是否正確
- 避免儲存錯誤配置
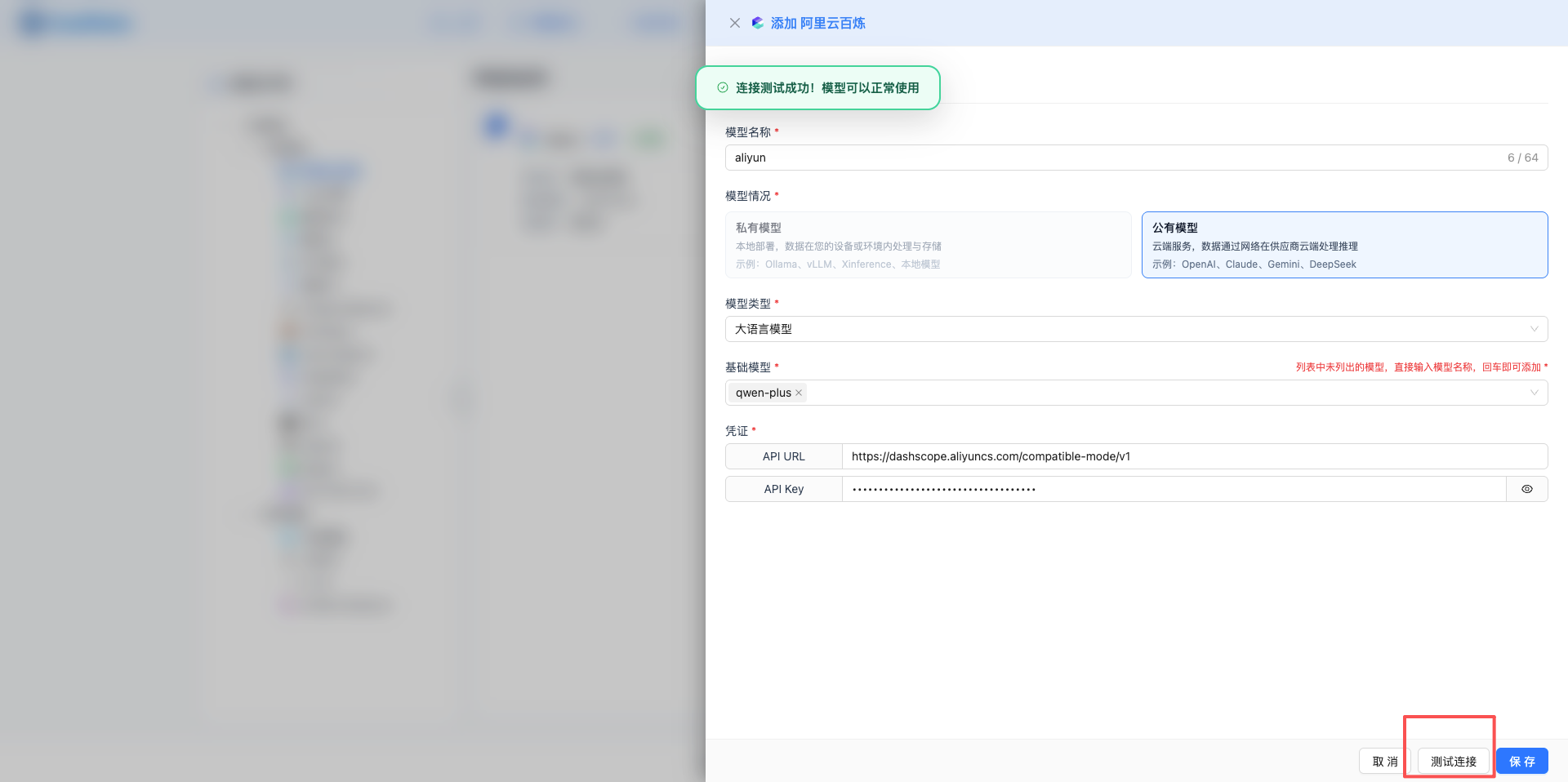
4.2 測試已儲存的模型
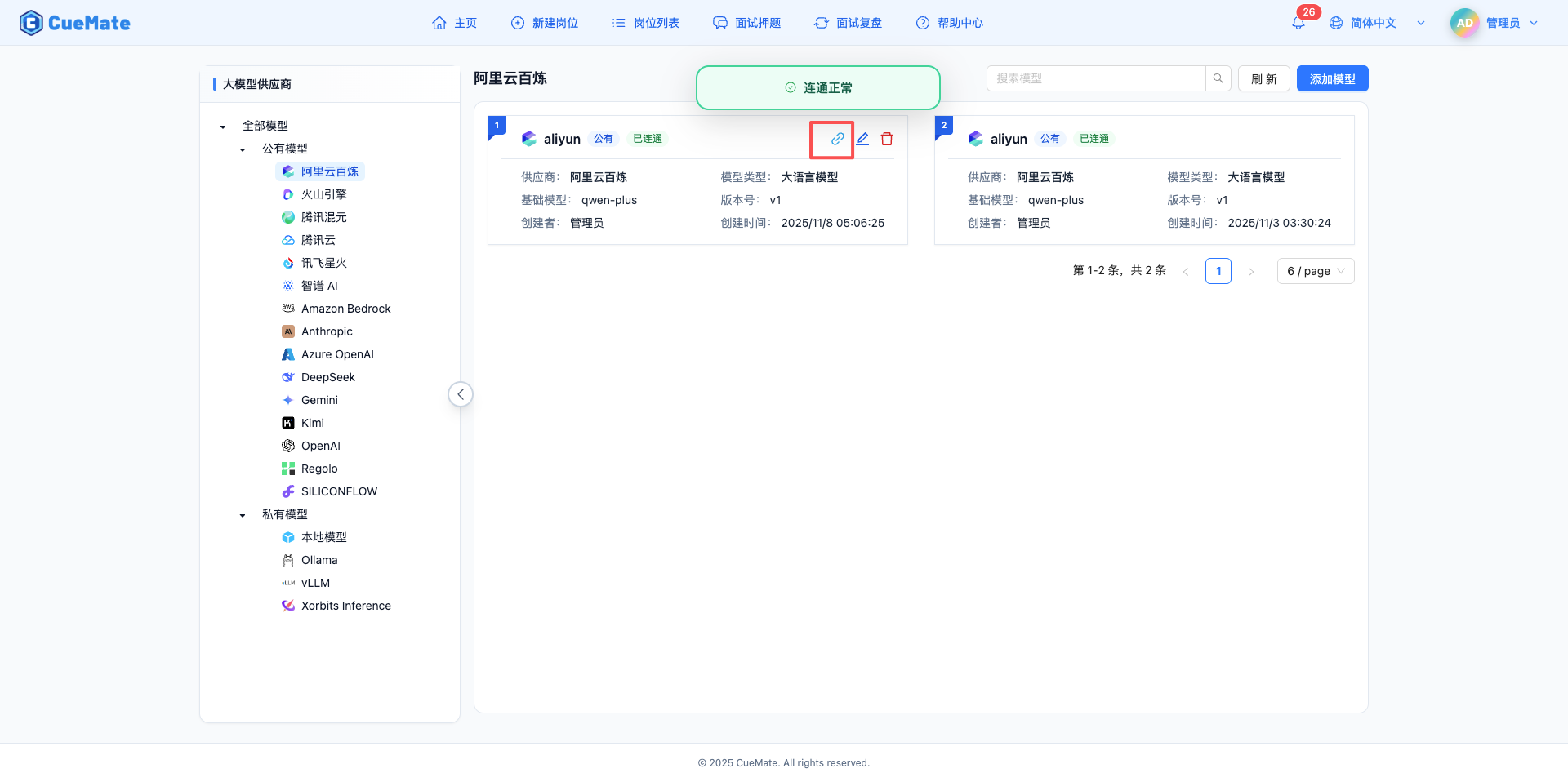
對於已儲存的模型,可以快速測試連通狀態。
觸發方式
- 滑鼠懸停在模型卡片上
- 點選天藍色的"連結"圖示
測試結果
- 成功:顯示綠色提示"連通正常",狀態標籤更新為"已連通"
- 失敗:顯示紅色提示"連通失敗",狀態標籤更新為"不可用"
- 測試完成後自動重新整理列表
最佳實踐
- 定期測試模型連通性
- 發現"不可用"狀態及時檢查配置
- API Key 更換後重新測試
5. 儲存模型配置
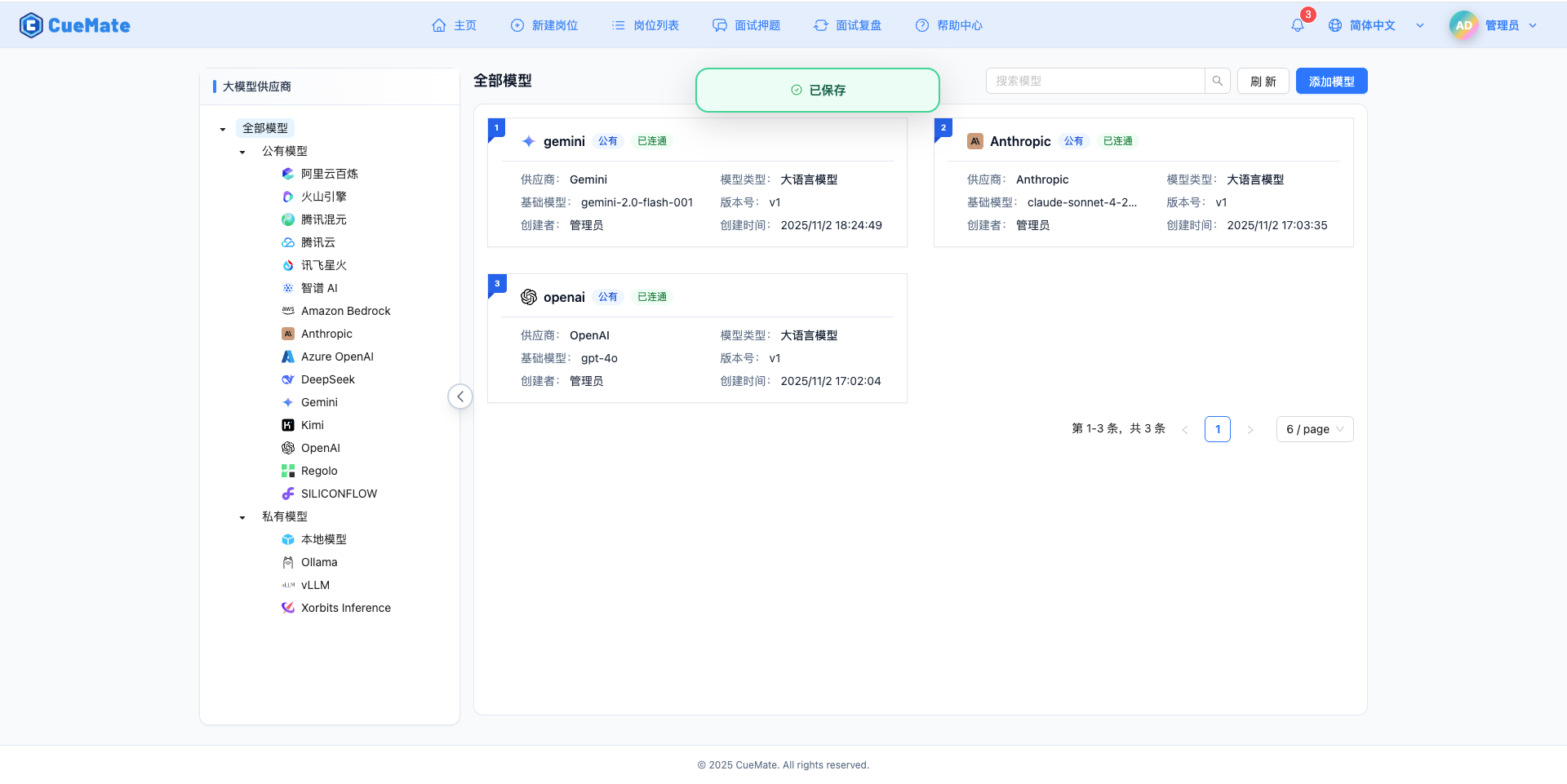
測試連線成功後,點選"儲存"按鈕儲存配置。
儲存前驗證
- 模型名稱:必填,不能為空
- 服務商:必填,必須選擇有效服務商
- 基礎模型:必填,必須選擇或輸入模型名稱
- 憑證欄位:檢查所有必填欄位是否已填寫
儲存過程
- 點選"儲存"按鈕
- 按鈕變為"儲存中..."並顯示載入動畫
- 顯示全屏遮罩層:"正在處理,請稍候..."
- 儲存成功:顯示綠色提示"已儲存"
- 關閉抽屜,自動重新整理模型列表
特殊處理
- 首次新增模型時,自動設定為使用者的預設模型
- 編輯已選中的模型時,同步更新記憶體中的模型資訊
6. 編輯模型
6.1 開啟編輯介面
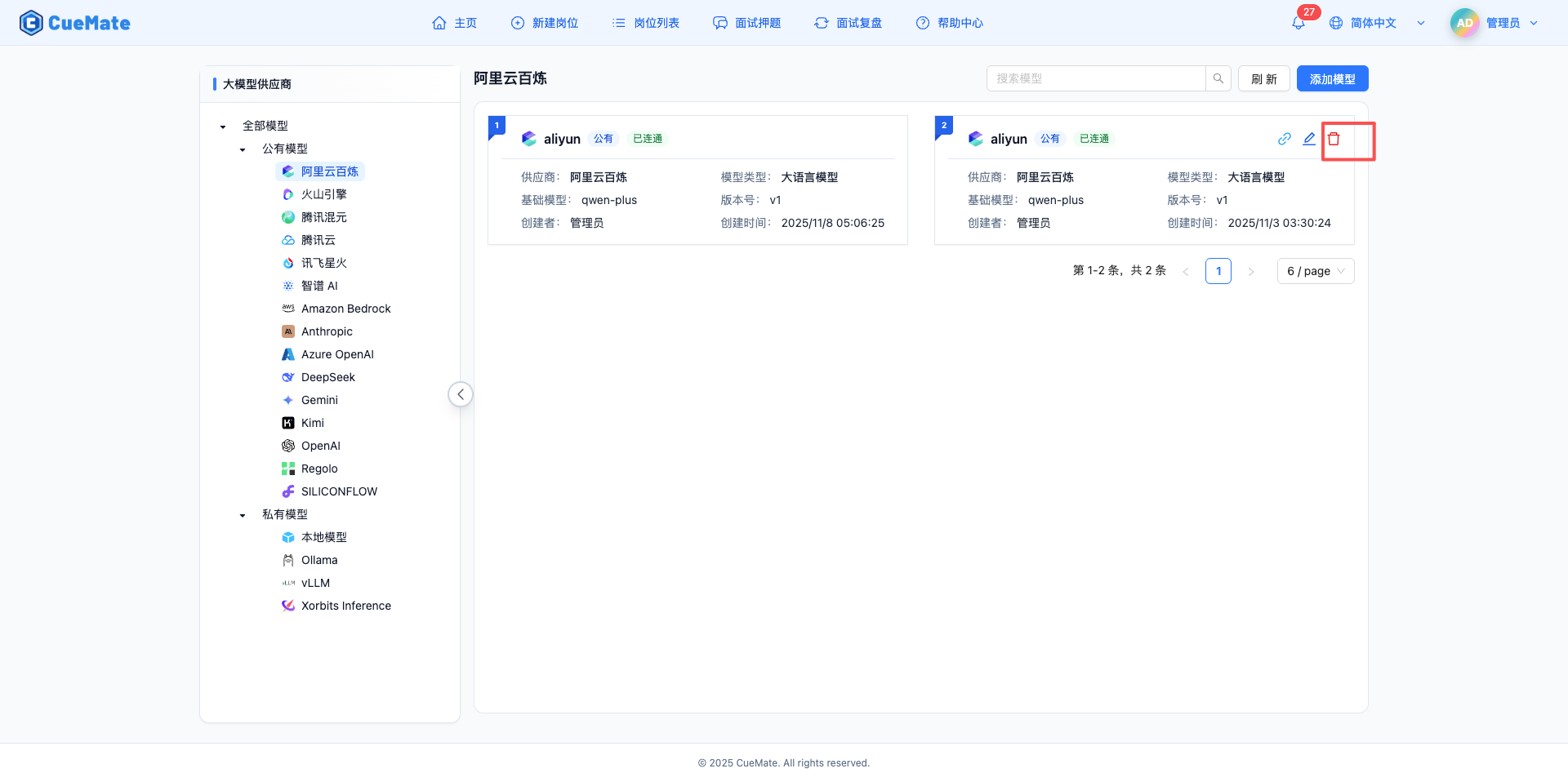
滑鼠懸停在模型卡片上,點選藍色的"編輯"圖示(鉛筆圖示)。
6.2 修改配置
預填充邏輯
- 所有欄位預填充當前模型的配置值
- 憑證欄位展開顯示
- 高階引數載入到表格
可修改項
- 模型名稱:可重新命名
- 基礎模型:可切換到同服務商下的其他模型
- 憑證欄位:可更新 API Key、Base URL 等
- 高階引數:可新增、修改、刪除引數
不可修改項
- 服務商:不能更改,如需更改請刪除後重新新增
- 模型情況(公有/私有):根據服務商自動確定
編輯流程
- 點選編輯圖示
- 抽屜滑出並載入模型詳情
- 修改需要更改的欄位
- (可選)點選"測試連線"驗證修改
- 點選"儲存"按鈕儲存修改
- 關閉抽屜,列表自動重新整理
7. 刪除模型
7.1 觸發刪除
滑鼠懸停在模型卡片上,點選紅色的"刪除"圖示(垃圾桶圖示)。
7.2 確認刪除
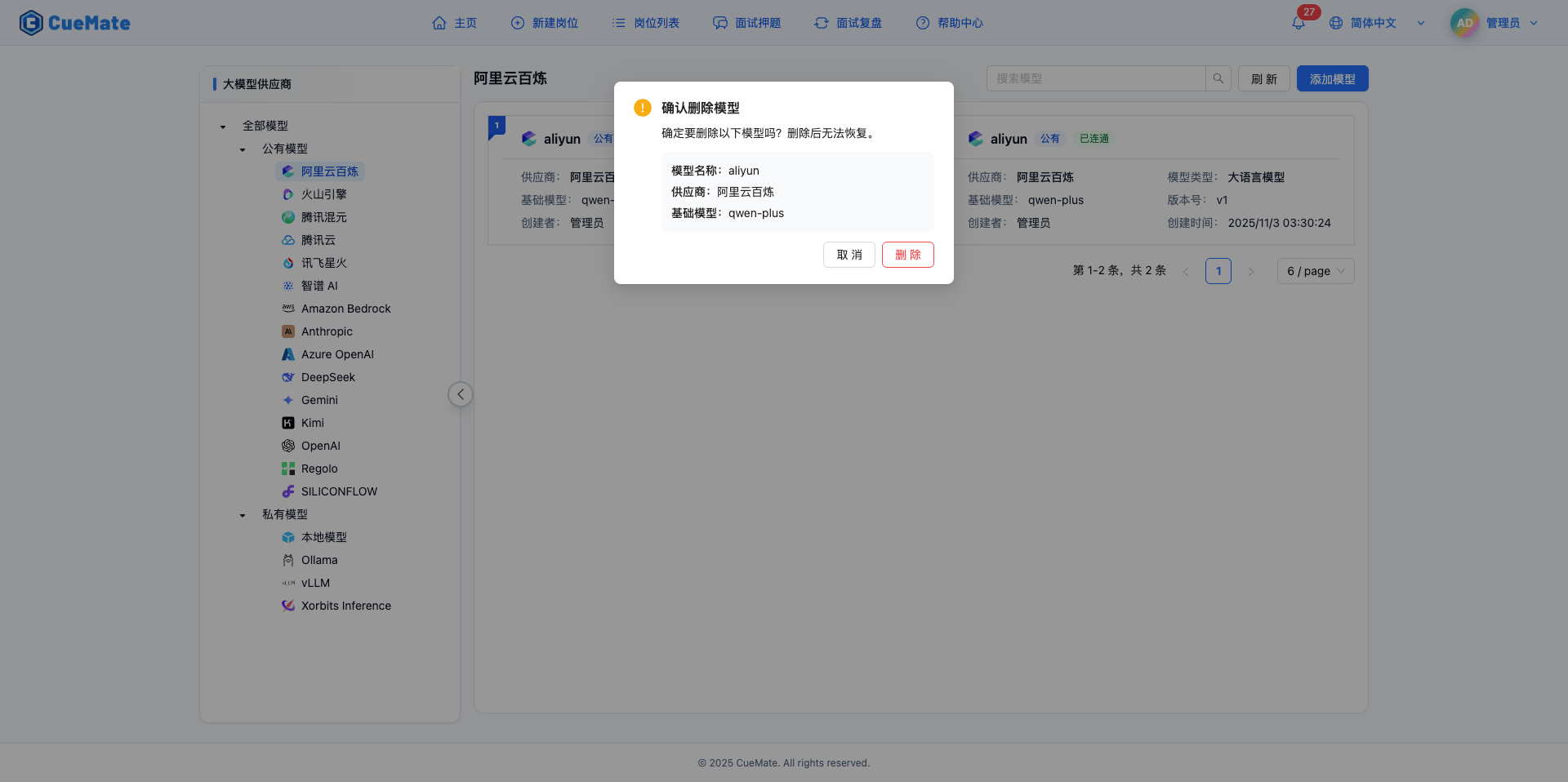
確認對話方塊
- 標題:"確認刪除模型"
- 內容:"確定要刪除該模型嗎?刪除後無法恢復。"
- 操作按鈕:
- "取消"按鈕:灰色,關閉對話方塊
- "刪除"按鈕:紅色危險按鈕,執行刪除
刪除過程
- 點選確認對話方塊中的"刪除"按鈕
- 顯示全屏遮罩層:"正在處理,請稍候..."
- 刪除成功顯示綠色提示:"已刪除"
- 自動重新整理模型列表
- 如果刪除後當前頁沒有資料,自動跳轉到上一頁
注意事項
- 刪除操作無法撤銷,請謹慎操作
- 刪除模型不會影響歷史對話記錄
- 如果刪除的是當前正在使用的模型,需要重新選擇其他模型
8. 支援的模型服務商
CueMate 支援多個主流大語言模型服務商,您可以根據需求選擇合適的模型:
8.1 公有云模型
- OpenAI - 全球領先的 AI 公司,提供 GPT-5、GPT-4.1、GPT-4o 等先進模型,支援複雜推理和多模態理解
- Anthropic - Claude 系列模型,最新 Claude Sonnet 4.5 為世界最強程式設計模型,擅長長文字理解和安全對話
- Google Gemini - Google 最新多模態模型,支援文字、影象、影片理解
- DeepSeek - 國產優秀模型,價效比高,程式碼能力強,支援數學推理
- Moonshot (Kimi) - 月之暗面,支援 200K 超長上下文,適合文件分析
- 智譜 AI - 清華系,GLM-4 系列模型,中文理解能力突出
- 通義千問 - 阿里雲百鍊平臺,Qwen 系列模型,生態完善
- 騰訊混元 - 騰訊自研大模型,中文能力強,接入便捷
- 訊飛星火 - 科大訊飛,語音場景最佳化,中文對話流暢
- 火山引擎 - 位元組跳動,豆包系列模型,多場景適配
- SiliconFlow - 開源模型推理平臺,支援 Llama、Qwen 等多個開源模型
- 百度千帆 - 百度推出的大語言模型平臺,支援 ERNIE-4.0、ERNIE-3.5 等模型
- 百川智慧 - 百川智慧推出的 Baichuan 系列模型,支援 Baichuan4、Baichuan3-Turbo、Baichuan3-Turbo-128k 等模型
- MiniMax - MiniMax 推出的超長文字大模型,支援 abab6.5-chat、abab6.5s-chat 等模型,最高支援 245K tokens 上下文
- 階躍星辰 - 主打長上下文的 Step 系列模型,支援 step-1-8k、step-1-32k、step-1-256k 等模型,最高支援 256K tokens 超長上下文
- 商湯日日新 - 商湯科技推出的 SenseNova 系列模型,支援 SenseChat-5、SenseChat-Turbo 等 22 個模型,包含自研和第三方模型
8.2 雲平臺模型服務
- Azure OpenAI - 微軟 Azure 雲平臺,提供企業級 OpenAI 模型服務,支援私有網路
- Amazon Bedrock - AWS 託管服務,整合 Claude、Llama 等多個模型,安全合規
- 騰訊雲 - 騰訊雲 AI 平臺,提供混元等模型服務
8.3 私有部署模型
- Ollama - 本地執行開源模型,支援 Llama、Qwen、Gemma 等,資料完全本地化
- vLLM - 高效能推理引擎,支援大規模模型部署,吞吐量高
- Xinference - Xorbits 開源推理框架,支援多種模型格式,易於擴充套件
- 本地模型 - 自定義本地模型服務,完全離線執行,資料安全性最高
- Regolo - 企業級私有化部署方案,高可用性保障,專業技術支援
選擇建議:
- 追求效能:OpenAI GPT-5、Claude Sonnet 4.5
- 程式設計場景:Claude Sonnet 4.5(世界最強)、OpenAI GPT-5
- 高價效比:Claude Haiku 4.5、GPT-5 Mini、DeepSeek
- 注重成本:DeepSeek、SiliconFlow、Ollama
- 中文場景:智譜 GLM-4、通義千問、騰訊混元
- 資料安全:Ollama、vLLM、本地模型
- 企業應用:Azure OpenAI、Amazon Bedrock、私有部署
9. 最佳實踐
模型配置建議
命名規範
- 使用清晰描述性的名稱,如"GPT-4 Turbo(生產環境)"
- 區分不同用途的相同模型,如"Claude 3 Sonnet(翻譯)"、"Claude 3 Sonnet(程式碼)"
- 避免使用過長的名稱,建議不超過 30 個字元
憑證安全
- API Key 輸入後使用密碼模式隱藏
- 不要在截圖或錄屏中暴露 API Key
- 定期更換 API Key,更換後重新測試連線
- 不同環境(開發/生產)使用不同的 API Key
引數最佳化
- 根據使用場景調整 temperature 引數:
- 創意寫作:0.7-0.9(更隨機)
- 程式碼生成:0.2-0.4(更確定)
- 翻譯任務:0.3-0.5(平衡)
- max_tokens 根據需求設定,避免過大導致費用增加
- 開啟 stream 引數可以實現打字機效果
連通性管理
- 新新增模型務必先測試連線
- 定期測試已有模型的連通性
- 發現"不可用"狀態及時排查原因
- 保留備用模型以應對主模型故障
效率提升技巧
快速新增模型
- 在左側導航樹選中具體服務商節點
- 點選"新增模型"直接進入配置介面,跳過服務商選擇步驟
搜尋篩選
- 模型較多時使用搜尋功能快速定位
- 結合左側導航和搜尋框實現精確篩選
頁面佈局最佳化
- 模型數量少時可以摺疊左側導航
- 調整每頁顯示數量,大螢幕建議設定為 12 或 18
常見問題排查
連通測試失敗
- 檢查 API Key 是否正確
- 檢查 Base URL 是否可訪問(私有部署模型)
- 檢查網路連線是否正常
- 檢查模型名稱是否正確
儲存失敗
- 確認所有必填欄位已填寫
- 檢查模型名稱是否重複
- 檢查憑證格式是否正確
模型無法使用
- 確認模型狀態為"已連通"
- 重新測試連線
- 檢查 API Key 是否過期
- 檢查餘額是否充足(公有模型)