語音識別設定
語音識別設定頁面用於配置 FunASR 語音識別服務、系統音訊捕獲、Piper TTS 語音合成、音訊裝置和測試引數。所有設定統一儲存到伺服器,並自動同步到桌面客戶端。
NOTE
系統音訊捕獲的平臺差異:
- macOS:使用 AudioTee 進行系統音訊捕獲
- Windows:使用 Electron Audio Loopback 進行系統音訊捕獲
兩者功能相同 - 都是捕獲面試軟體(騰訊會議、Zoom 等)的音訊輸出。設定頁面顯示 AudioTee 選項,但 Windows 內部使用 Electron Audio Loopback。
注:預設所有配置都有預設值,除了本地的麥克風和揚聲器需要額外配置。
1. 進入語音識別設定
點選頂部下拉選單選單中的"語音設定",進入設定頁面。
頁面包含五個配置標籤頁:
- 裝置配置:麥克風和揚聲器設定
- FunASR 配置:語音識別服務引數
- AudioTee 配置:系統音訊捕獲配置
- Piper TTS 配置:語音合成引數
- 測試配置:測試引數設定

2. 裝置配置
NOTE
裝置配置需要桌面客戶端正常執行。Web 端會自動從桌面客戶端獲取裝置列表,請確保桌面應用已啟動。
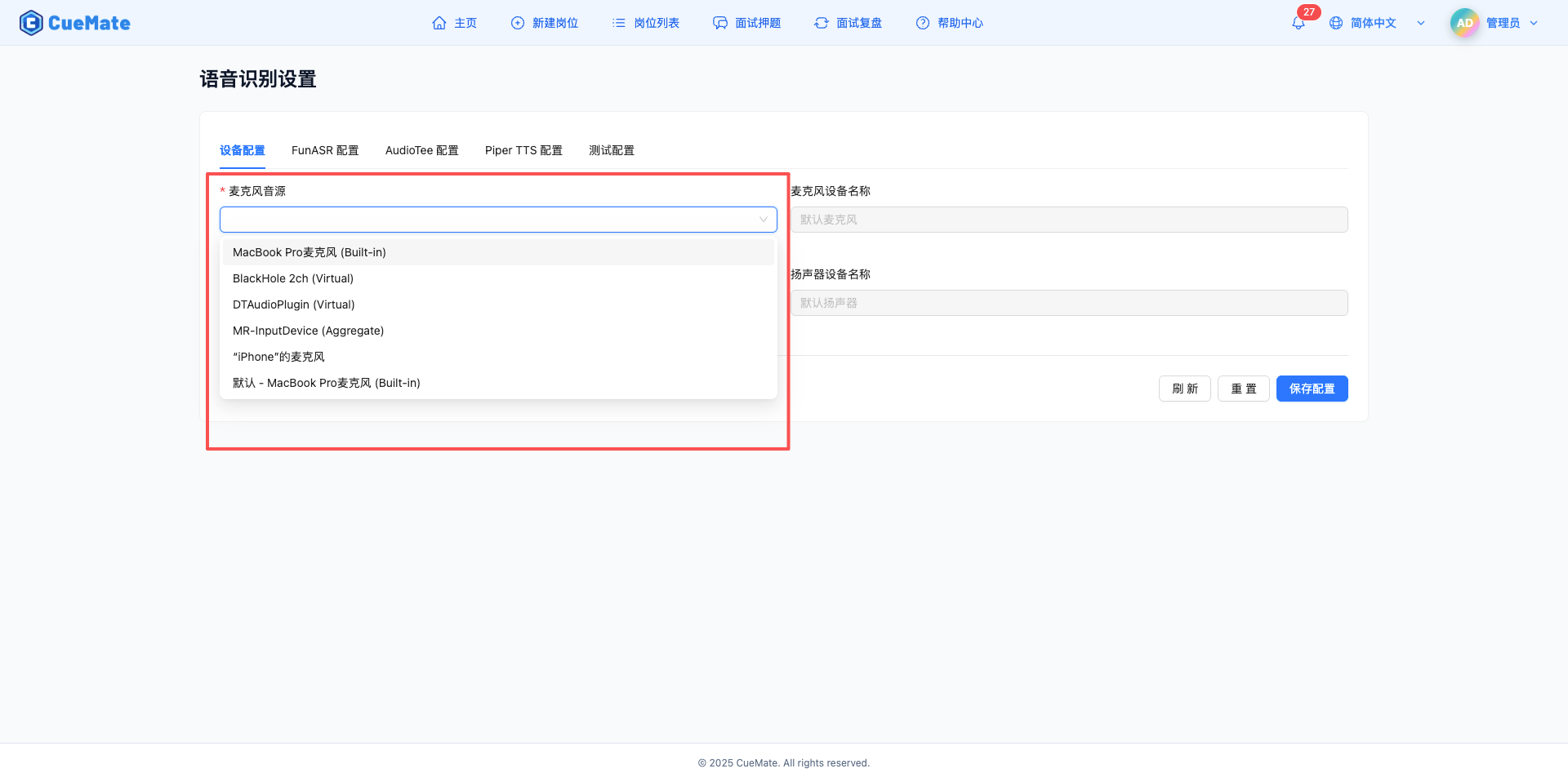
2.1 麥克風設定
在"裝置配置"標籤頁,配置麥克風音訊輸入裝置。
TIP
推薦裝置選擇:
- 首選:電腦內建麥克風(簡單方便)
- 環境嘈雜時:頭戴式耳機麥克風(降噪效果好)
- 追求高質量:專業 USB 麥克風(識別準確率高)
麥克風音源
- 下拉框顯示系統中所有可用的麥克風裝置
- 桌面客戶端會自動檢測並上報裝置列表到 Web 端
- 選擇要使用的麥克風裝置
- 首選電腦本身的內建麥克風(如 MacBook 內建麥克風)
- 也支援外接麥克風(如 USB 麥克風、頭戴式耳機麥克風)
- 裝置格式示例:內建麥克風、USB 麥克風
麥克風裝置名稱
- 自動顯示選中麥克風的完整名稱
- 只讀欄位,不可手動編輯
- 用於確認選擇的裝置是否正確
使用場景
麥克風是模擬面試和麵試訓練的核心輸入裝置,主要用於:
使用者語音輸入
- 使用者在模擬面試中回答問題時,麥克風捕獲您的語音
- 語音透過 FunASR 服務實時轉換為文字
- 文字內容傳送給 LLM 生成智慧答案和建議
- 整個過程實現了"說話 → 識別 → AI 回答"的閉環
面試訓練場景
- 練習口語表達時,麥克風記錄您的回答
- 系統識別您的語音內容,分析回答質量
- 根據識別結果提供針對性反饋
裝置選擇建議
- 優先使用電腦內建麥克風,簡單方便,無需額外裝置
- 環境嘈雜時可選擇頭戴式耳機麥克風,減少背景噪音
- 追求更高識別準確率可使用專業 USB 麥克風
2.2 揚聲器設定
在"裝置配置"標籤頁,配置揚聲器音訊輸出裝置。
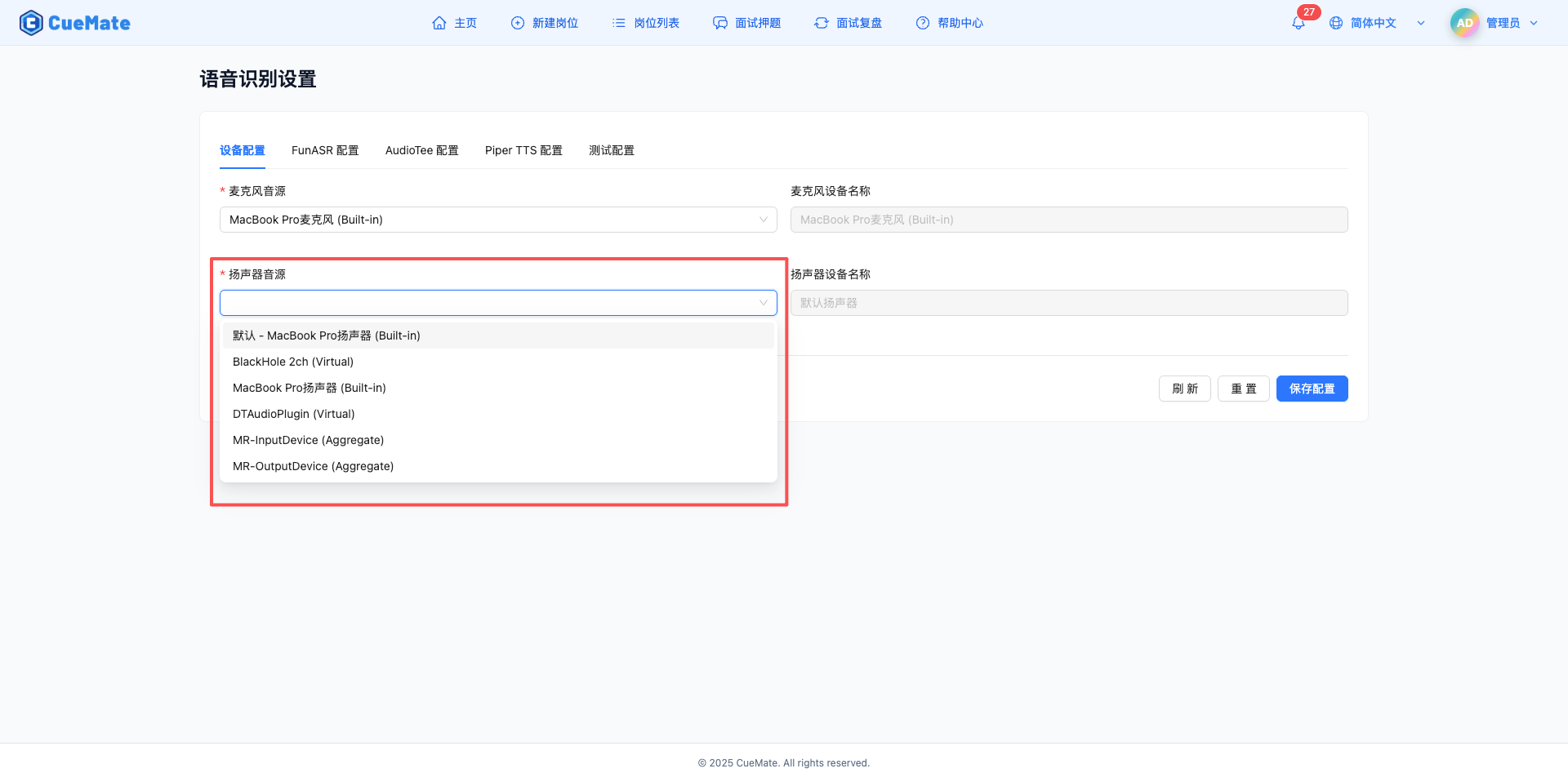
揚聲器音源
- 下拉框顯示系統中所有可用的揚聲器裝置
- 桌面客戶端會自動檢測並上報裝置列表
- 選擇要使用的揚聲器裝置
- 首選電腦本身的內建揚聲器(如 MacBook 內建揚聲器)
- 也支援外接音訊裝置(如 USB 音箱、藍芽耳機、有線耳機)
- 裝置格式示例:內建揚聲器、USB 音箱、藍芽耳機
揚聲器裝置名稱
- 自動顯示選中揚聲器的完整名稱
- 只讀欄位,不可手動編輯
- 用於確認選擇的裝置是否正確
使用場景
揚聲器在模擬面試和麵試訓練中承擔兩個關鍵作用:
播放 AI 生成的答案語音(Piper TTS)
- 當您說話後,AI 會生成智慧答案和建議
- Piper TTS 將文字答案轉換為自然流暢的語音
- 透過揚聲器播放出來,您可以聽到 AI 的回答
- 這樣無需盯著螢幕看文字,解放雙眼,專注思考
捕獲面試官的語音(AudioTee 系統音訊捕獲)
- 這是揚聲器最重要的功能
- 當您使用騰訊會議、Zoom 等軟體進行模擬面試訓練時
- 模擬面試官的聲音會從揚聲器播放出來
- AudioTee 捕獲揚聲器播放的系統音訊流
- 捕獲的音訊透過 FunASR 識別成文字
- AI 分析問題,實時生成答案提示
- 實現了"語音播放 → 揚聲器輸出 → AudioTee 捕獲 → FunASR 識別 → AI 生成答案"的完整流程
技術原理說明
為什麼揚聲器對捕獲面試官語音至關重要:
- 面試軟體(騰訊會議、Zoom)的音訊輸出到揚聲器
- AudioTee 作為系統級音訊捕獲工具,攔截髮送到揚聲器的音訊流
- 即使您戴著耳機,AudioTee 也能捕獲到音訊資料
- 這是一種非侵入式的音訊捕獲方案,不影響面試軟體正常執行
裝置選擇建議
- 優先使用電腦內建揚聲器,系統音訊捕獲最穩定
- 使用耳機時確保 AudioTee 能正確識別音訊裝置
- 避免使用藍芽裝置,可能存在延遲和相容性問題
- 面試訓練場景建議使用有線耳機,保證音質和捕獲穩定性
2.3 重新整理裝置列表
如果連線了新的音訊裝置,點選底部"重新整理"按鈕重新檢測裝置列表。
重新整理操作
- 點選"重新整理"按鈕
- 向桌面客戶端傳送裝置請求
- 瀏覽器重新列舉本地音訊裝置
- 裝置列表自動更新
使用場景
- 插入新的 USB 麥克風或音箱後重新整理列表
- 連線藍芽耳機後重新整理裝置
- 裝置列表顯示異常時重新載入
3. FunASR 配置
3.1 基本配置
在"FunASR 配置"標籤頁,配置 FunASR 語音識別服務的連線引數。
注:預設所有配置都有預設值,不需要修改。
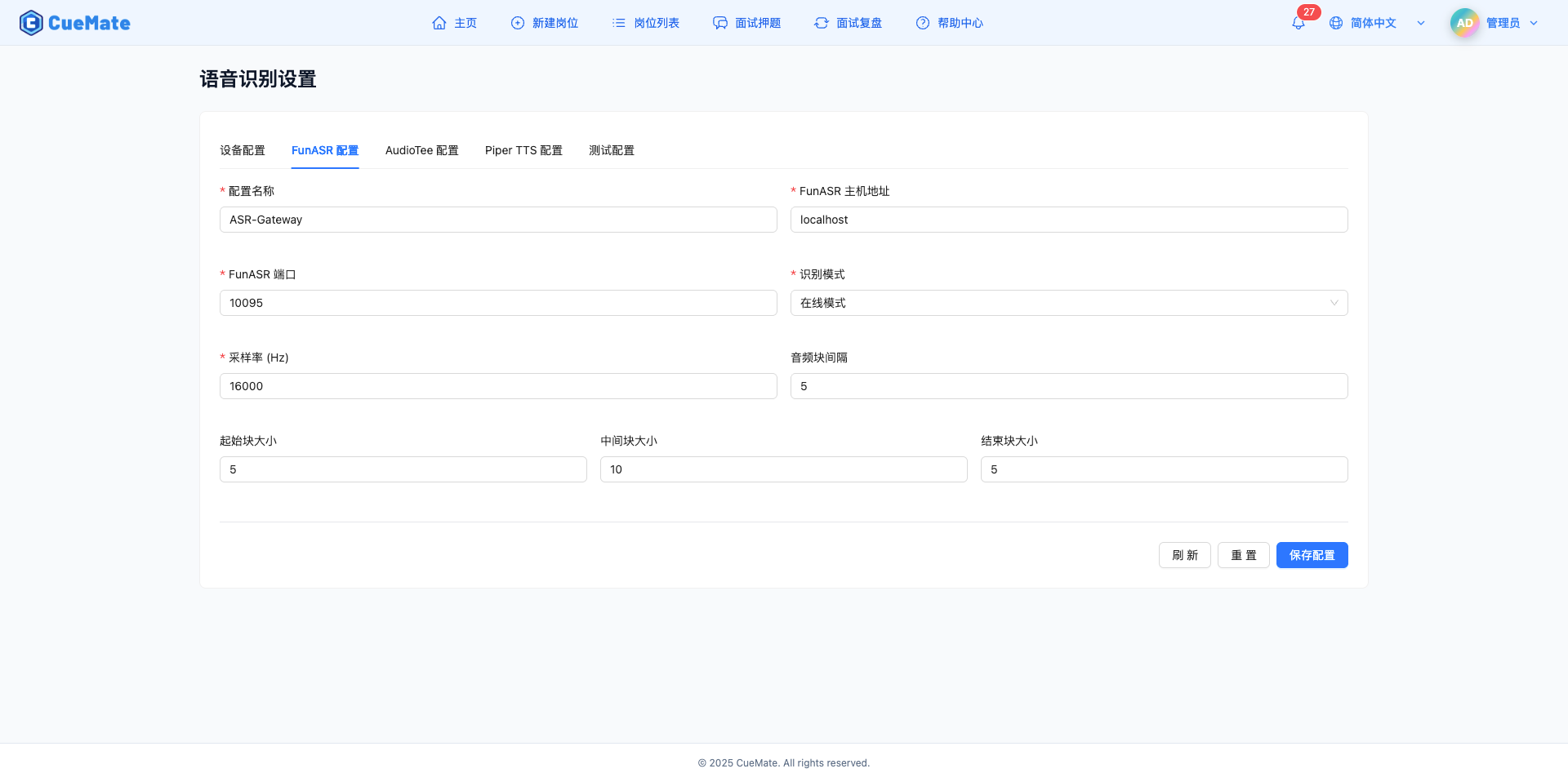
配置名稱
- 為當前配置命名
- 預設值:ASR-Gateway
- 便於識別和管理多個配置
FunASR 主機地址
- FunASR 服務的主機地址
- 預設值:localhost
- 本地部署填寫 localhost 或 127.0.0.1
- 遠端部署填寫伺服器 IP 地址
FunASR 埠
- FunASR 服務的 WebSocket 埠
- 預設值:10095
- 取值範圍:1-65535
- 確保埠未被其他服務佔用
識別模式
- 線上模式(online):實時流式識別,低延遲,邊說邊轉文字
- 離線模式(offline):錄音完成後統一識別,準確率高
- 兩遍模式(2pass):先線上實時顯示,再離線最佳化結果
使用場景
- 面試場景推薦使用"線上模式",實時看到答案
- 錄音轉文字推薦使用"離線模式",準確率更高
- 重要會議推薦使用"兩遍模式",兼顧實時性和準確性
3.2 音訊引數
取樣率(Hz)
- 音訊取樣率,影響識別質量
- 預設值:16000 Hz
- 取值範圍:8000-48000 Hz
- 推薦使用 16000 Hz,平衡質量和效能
音訊塊間隔
- 音訊塊傳送間隔
- 預設值:5
- 取值範圍:1-20
- 值越小延遲越低,但網路壓力越大
3.3 音訊塊大小配置
FunASR 使用分塊識別策略,將音訊流分為起始、中間、結束三個階段。
起始塊大小(chunk_size_start)
- 語音開始階段的音訊塊大小
- 預設值:5
- 取值範圍:1-20
- 較小的值可以快速觸發識別
中間塊大小(chunk_size_middle)
- 語音持續階段的音訊塊大小
- 預設值:10
- 取值範圍:1-20
- 較大的值提高穩定識別
結束塊大小(chunk_size_end)
- 語音結束階段的音訊塊大小
- 預設值:5
- 取值範圍:1-20
- 較小的值可以快速結束識別
調優建議
- 起始塊和結束塊較小,快速響應
- 中間塊較大,穩定識別長句子
- 總體值越小越實時,但識別可能不穩定
- 總體值越大越穩定,但延遲越高
4. AudioTee 配置
4.1 AudioTee 簡介
NOTE
平臺差異說明:
- macOS:使用 AudioTee 進行系統音訊捕獲,支援程序過濾等進階功能
- Windows:使用 Electron Audio Loopback 進行系統音訊捕獲,配置更簡單,無需額外設定
AudioTee 是 macOS 平臺的系統音訊捕獲工具,用於捕獲面試軟體(如騰訊會議、Zoom)的音訊輸出,實現面試官語音識別。
Windows 使用者可以跳過此章節的程序過濾配置,直接使用預設設定即可。
4.2 基本配置
在"AudioTee 配置"標籤頁,配置系統音訊捕獲引數。
注:預設所有配置都有預設值,不需要修改。
AudioTee 取樣率
- 系統音訊捕獲的取樣率
- 預設值:16000 Hz(推薦)
- 可選值:8000/16000/22050/24000/32000/44100/48000 Hz
- 推薦使用 16000 Hz,與 FunASR 取樣率保持一致
音訊塊時長(秒)
- 每個音訊塊的時長
- 預設值:0.2 秒
- 取值範圍:0.1-2.0 秒
- 值越小延遲越低,但處理頻率越高
4.3 程序過濾配置
AudioTee 支援過濾特定程序的音訊,實現精確捕獲。
包含程序列表(JSON)
- 只捕獲指定程序的音訊
- 格式:JSON 字串陣列
- 示例:
["1234", "5678"] - 留空表示捕獲所有程序音訊
排除程序列表(JSON)
- 排除指定程序的音訊
- 格式:JSON 字串陣列
- 示例:
["9999"] - 用於過濾不需要的音訊源
程序過濾邏輯
- 如果設定了"包含程序列表",只捕獲列表中的程序音訊
- 如果設定了"排除程序列表",不捕獲列表中的程序音訊
- 兩個列表可以組合使用
使用場景
- 只捕獲騰訊會議的音訊:包含程序列表填寫騰訊會議的程序 ID
- 排除音樂播放器的音訊:排除程序列表填寫音樂播放器的程序 ID
- 預設捕獲所有系統音訊:兩個列表都留空
[]
獲取程序 ID(macOS)
# 查詢騰訊會議程序 ID
ps aux | grep "TencentMeeting"
# 查詢 Zoom 程序 ID
ps aux | grep "zoom.us"4.4 靜音控制
靜音被捕獲的程序
- 開關控制是否靜音被捕獲的程序音訊
- 開啟後,被捕獲的音訊不會從揚聲器播放
- 關閉後,正常播放音訊的同時進行捕獲
- 預設值:關閉
使用場景
- 面試時想要安靜環境,開啟靜音
- 需要聽到面試官聲音,關閉靜音
- 錄製時不想打擾他人,開啟靜音
5. Piper TTS 配置
5.1 Piper TTS 簡介
Piper TTS 是本地神經網路語音合成系統,將文字轉換為自然流暢的語音。桌面客戶端使用 Piper TTS 朗讀 AI 生成的答案。
技術實現
- Piper TTS 已透過 PyInstaller 打包為獨立可執行檔案
- 內建 Python 執行時和所有必要依賴
- 無需使用者單獨安裝 Python 或配置環境
- 隨桌面客戶端一起分發,開箱即用
- 支援中文(花顏女聲)和英文(Amy 女聲)兩種語音模型
5.2 語音配置
在"Piper TTS 配置"標籤頁,配置語音合成引數。
注:預設所有配置都有預設值,不需要修改。
預設語言
- 選擇 TTS 語音合成的預設語言
- 中文(zh-CN):使用花顏女聲中文模型
- 英文(en-US):使用 Amy 女聲英文模型
- 會根據使用者設定的介面語言自動選擇對應語音
語音速度
- 控制語音朗讀的速度
- 預設值:1.0(正常速度)
- 取值範圍:0.5-2.0
- 0.5 表示慢速,2.0 表示快速
- 建議使用 0.8-1.2 之間的值
語音速度選擇建議
- 0.5-0.7:學習模式,慢速理解
- 0.8-1.0:正常模式,舒適自然
- 1.1-1.5:快速模式,節省時間
- 1.6-2.0:極速模式,快速瀏覽
使用場景
- 中文面試選擇"中文(zh-CN)"
- 英文面試選擇"英文(en-US)"
- 答案較長時降低語音速度,便於理解
- 時間緊迫時提高語音速度,快速瀏覽
配置建議
- 語音語言應與系統設定的介面語言保持一致
- 語音速度建議在 0.9-1.1 之間,過快或過慢都不自然
NOTE
關於 Python 依賴:桌面客戶端已內建 Piper TTS 獨立可執行檔案(使用 PyInstaller 打包),無需單獨安裝 Python 和 piper-tts 依賴。所有必要元件已隨應用一起分發。
6. 測試配置
6.1 測試引數
在"測試配置"標籤頁,配置音訊裝置和語音識別的測試引數。
注:預設所有配置都有預設值,不需要修改。
測試持續時間(秒)
- 裝置測試的最大持續時間
- 預設值:60 秒
- 取值範圍:10-300 秒
- 超過時間後自動停止測試
識別超時時間(秒)
- 語音識別的超時時間
- 預設值:15 秒
- 取值範圍:5-60 秒
- 超過時間未識別到語音,認為識別失敗
6.2 識別長度限制
最小識別長度
- 識別結果的最小字元數
- 預設值:5
- 取值範圍:1-50
- 少於此長度的識別結果可能被過濾
最大識別長度
- 識別結果的最大字元數
- 預設值:30
- 取值範圍:10-200
- 超過此長度的識別結果可能被截斷
使用場景
- 過濾短語音(如"嗯"、"啊")設定最小識別長度為 5
- 限制長句子識別設定最大識別長度
- 測試時可以調整這些引數觀察效果
7. 儲存和重置
7.1 儲存配置
點選底部"儲存配置"按鈕,將所有配置儲存到伺服器。
儲存流程
- 點選"儲存配置"按鈕
- 驗證所有必填欄位是否填寫正確
- 提交配置到伺服器
- 伺服器儲存配置並返回確認
- 顯示"配置已儲存"成功提示
- 桌面客戶端自動同步新配置
儲存內容
- 裝置配置(麥克風、揚聲器)
- FunASR 配置(主機、埠、模式等)
- AudioTee 配置(取樣率、程序過濾等)
- Piper TTS 配置(語言、語音速度等)
- 測試配置(測試時間、識別長度等)
重要提示
- 修改配置後必須點選"儲存配置"才會生效
- 桌面客戶端會自動同步最新配置
- 建議在非面試時間修改配置並測試
7.2 重置配置
點選底部"重置"按鈕,恢復所有配置為預設值。
重置操作
- 點選"重置"按鈕
- 所有欄位恢復為預設值
- 不會自動儲存,需要手動點選"儲存配置"
預設配置值
配置名稱: ASR-Gateway
FunASR 主機: localhost
FunASR 埠: 10095
識別模式: 線上模式
取樣率: 16000 Hz
音訊塊間隔: 5
起始/中間/結束塊大小: 5/10/5
AudioTee 取樣率: 16000 Hz
音訊塊時長: 0.2 秒
程序過濾: 空 []
靜音程序: 關閉
Piper 預設語言: 中文 (zh-CN)
語音速度: 1.0
測試持續時間: 60 秒
識別超時: 15 秒
最小識別長度: 5
最大識別長度: 30使用場景
- 配置修改出錯,恢復預設值
- 不確定如何配置,使用預設配置
- 測試完成後恢復推薦配置
7.3 重新整理裝置
點選底部"重新整理"按鈕,重新檢測音訊裝置列表。
重新整理功能
- 向桌面客戶端請求最新裝置列表
- 瀏覽器重新列舉本地音訊裝置
- 麥克風和揚聲器下拉框自動更新
使用場景
- 插入新的 USB 音訊裝置後重新整理
- 連線藍芽耳機後重新整理
- 裝置列表顯示異常時重新整理
8. 常見問題
8.1 裝置列表為空
問題:麥克風或揚聲器下拉框沒有裝置選項。
解決方案
- 點選"重新整理"按鈕重新檢測裝置
- 檢查桌面客戶端是否正常執行
- 確認瀏覽器已授予麥克風許可權
- 檢查系統是否連線了音訊裝置
- 重啟瀏覽器和桌面客戶端
8.2 儲存配置失敗
問題:點選"儲存配置"按鈕,提示儲存失敗。
解決方案
- 檢查所有必填欄位是否填寫
- 檢查埠號是否在 1-65535 範圍內
- 檢查 JSON 格式的程序列表是否正確
- 檢視瀏覽器控制檯是否有錯誤資訊
- 檢查網路連線是否正常
8.3 FunASR 連線失敗
問題:配置儲存後,桌面客戶端無法連線 FunASR 服務。
解決方案
- 檢查 FunASR 主機地址和埠是否正確
- 確認 FunASR Docker 容器是否正常執行bash
docker ps | grep FunASR - 測試 FunASR 服務是否可訪問bash
curl ws://localhost:10095 - 檢查防火牆是否阻止了連線
- 檢視 FunASR 容器日誌bash
docker logs FunASR
8.4 系統音訊無法捕獲
問題:無法捕獲面試軟體的音訊。
解決方案(macOS - AudioTee)
- 系統偏好設定 > 安全性與隱私 > 螢幕錄製
- 允許 CueMate 或桌面客戶端訪問螢幕錄製許可權
- 檢查程序過濾配置是否正確
- 確認面試軟體正在播放音訊
- 嘗試關閉"靜音被捕獲的程序"開關
- 檢視桌面客戶端日誌是否有錯誤資訊
解決方案(Windows - Electron Audio Loopback)
- 確認揚聲器裝置選擇正確
- 確認面試軟體正在播放音訊
- 檢查 Windows 聲音設定中的輸出裝置是否正確
- 重新啟動 CueMate 應用
- 檢視桌面客戶端日誌是否有錯誤資訊
- 日誌位置:
%APPDATA%\cuemate-desktop-client\data\logs\
- 日誌位置:
8.5 Piper TTS 無聲音
問題:配置了 Piper TTS,但播放答案時沒有聲音。
解決方案
- 檢查揚聲器裝置是否選擇正確
- 確認系統音量未靜音
- 檢查 Piper TTS 語言設定是否與內容匹配(中文內容需選擇中文語音)
- 檢視桌面客戶端日誌是否有 TTS 錯誤
- macOS:
~/Library/Application Support/cuemate-desktop-client/data/logs/
- macOS:
- 確認 Piper TTS 二進位制檔案是否正常
- 二進位制檔案位置:
resources/piper-bin/piper - 如果檔案丟失或損壞,請重新安裝桌面客戶端
- 二進位制檔案位置:
NOTE
Piper TTS 已作為獨立可執行檔案內建在桌面客戶端中,無需單獨安裝 Python 或 piper-tts 包。如果遇到問題,通常是配置或系統許可權問題,而非依賴缺失。
8.6 語音識別準確率低
問題:語音識別經常識別錯誤或識別不出來。
解決方案
- 檢查麥克風裝置是否正常工作
- 選擇安靜的環境,減少背景噪音
- 調整麥克風位置,靠近說話者
- 清晰發音,語速適中,避免快速連讀
- 嘗試提高 FunASR 取樣率到 48000 Hz
- 切換識別模式為"兩遍模式"提高準確率
8.7 識別延遲高
問題:說話後很久才顯示識別結果。
解決方案
- 降低 FunASR 音訊塊間隔(如改為 3)
- 減小 FunASR 塊大小(如起始/中間/結束改為 3/6/3)
- 降低 AudioTee 音訊塊時長(如改為 0.1 秒)
- 使用有線麥克風,避免藍芽延遲
- 檢查系統資源佔用,關閉不必要的程式
- 確認網路連線正常,延遲較低