
配置 vLLM
vLLM 是高效能的大語言模型推理和部署引擎,採用 PagedAttention 技術實現高吞吐量推理,支援多種開源模型。
1. 安裝和部署 vLLM
1.1 訪問 vLLM 官網
訪問 vLLM 官網並檢視文件:https://vllm.ai/
GitHub 倉庫:https://github.com/vllm-project/vllm
1.2 環境要求
- 作業系統:Linux(推薦 Ubuntu 20.04+)
- Python:3.8-3.11
- GPU:NVIDIA GPU(支援 CUDA 11.8+)
- 記憶體:根據模型大小,建議 32GB+
重要提示:
- 注意:vLLM 僅支援 Linux + NVIDIA GPU
- 注意:macOS/Windows 使用者必須使用 Docker 方式執行
- 注意:沒有 NVIDIA GPU 的裝置無法高效能執行 vLLM
1.3 安裝 vLLM
方式一:Linux + NVIDIA GPU(推薦)
# 建立虛擬環境
python3 -m venv vllm-env
source vllm-env/bin/activate
# 安裝vLLM
pip install vllm
# 驗證安裝
python -c "import vllm; print(vllm.__version__)"方式二:使用 Docker(跨平臺,推薦 macOS/Windows 使用者)
# 拉取vLLM官方映象
docker pull vllm/vllm-openai:latest
# 執行vLLM服務(需要 NVIDIA GPU)
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model facebook/opt-125mDocker 拉取失敗解決方案:
如果拉取映象時遇到網路錯誤(如 failed to copy: httpReadSeeker),可以配置映象加速:
# macOS Docker Desktop 配置
# 開啟 Docker Desktop → Settings → Docker Engine
# 新增以下配置:
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live"
]
}
# 點選 Apply & Restart配置完成後重新拉取映象。
1.4 啟動 vLLM 服務
對於 Linux 使用者:
# 啟動vLLM OpenAI相容伺服器
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \
--port 8000對於 macOS/Windows 使用者(使用 Docker):
由於 vLLM 需要 NVIDIA GPU,macOS/Windows 使用者無法本地執行,建議:
- 在有 NVIDIA GPU 的 Linux 伺服器上部署 vLLM
- 在 CueMate 中配置遠端伺服器地址(如
http://192.168.1.100:8000/v1) - 或使用其他支援 macOS 的本地推理框架(如 Ollama)
常用啟動引數:
--model:模型名稱或路徑--host:服務監聽地址(預設 0.0.0.0)--port:服務埠(預設 8000)--tensor-parallel-size:張量並行大小(多 GPU)--dtype:資料型別(auto/half/float16/bfloat16)
1.5 驗證服務執行
# 檢查服務狀態
curl http://localhost:8000/v1/models正常返回結果示例:
{
"object": "list",
"data": [
{
"id": "Qwen/Qwen2.5-7B-Instruct",
"object": "model",
"created": 1699234567,
"owned_by": "vllm",
"root": "Qwen/Qwen2.5-7B-Instruct",
"parent": null,
"permission": [
{
"id": "modelperm-xxx",
"object": "model_permission",
"created": 1699234567,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}如果返回上述 JSON 內容,說明 vLLM 服務啟動成功。
如果服務未啟動或配置錯誤,會返回:
# 連線失敗
curl: (7) Failed to connect to localhost port 8000: Connection refused
# 或者 404 錯誤
{"detail":"Not Found"}2. 在 CueMate 中配置 vLLM 模型
2.1 進入模型設定頁面
登入 CueMate 系統後,點選右上角下拉選單的 模型設定。
2.2 新增新模型
點選右上角的 新增模型 按鈕。

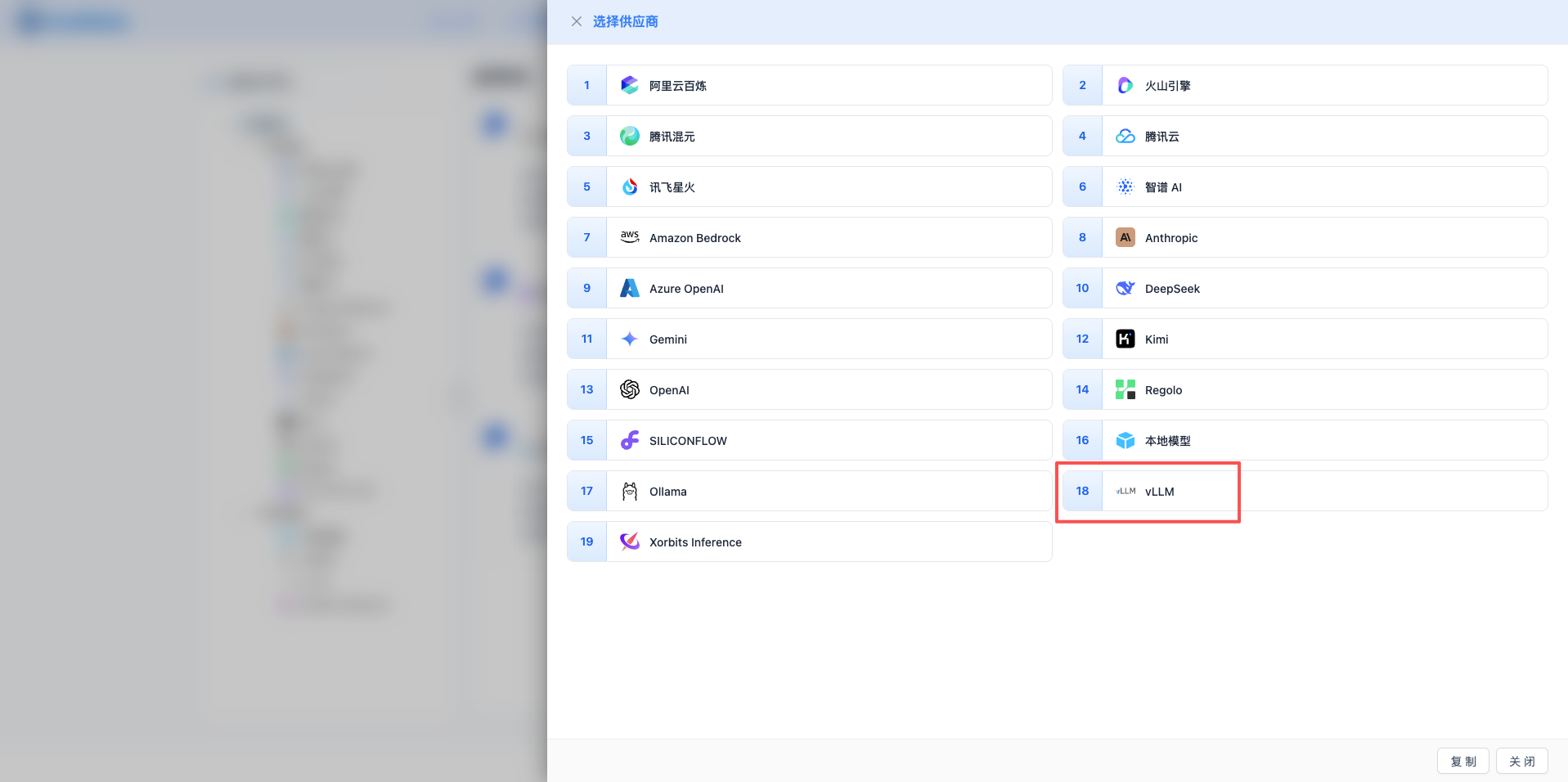
2.3 選擇 vLLM 服務商
在彈出的對話方塊中:
- 服務商型別:選擇 vLLM
- 點選後 自動進入下一步
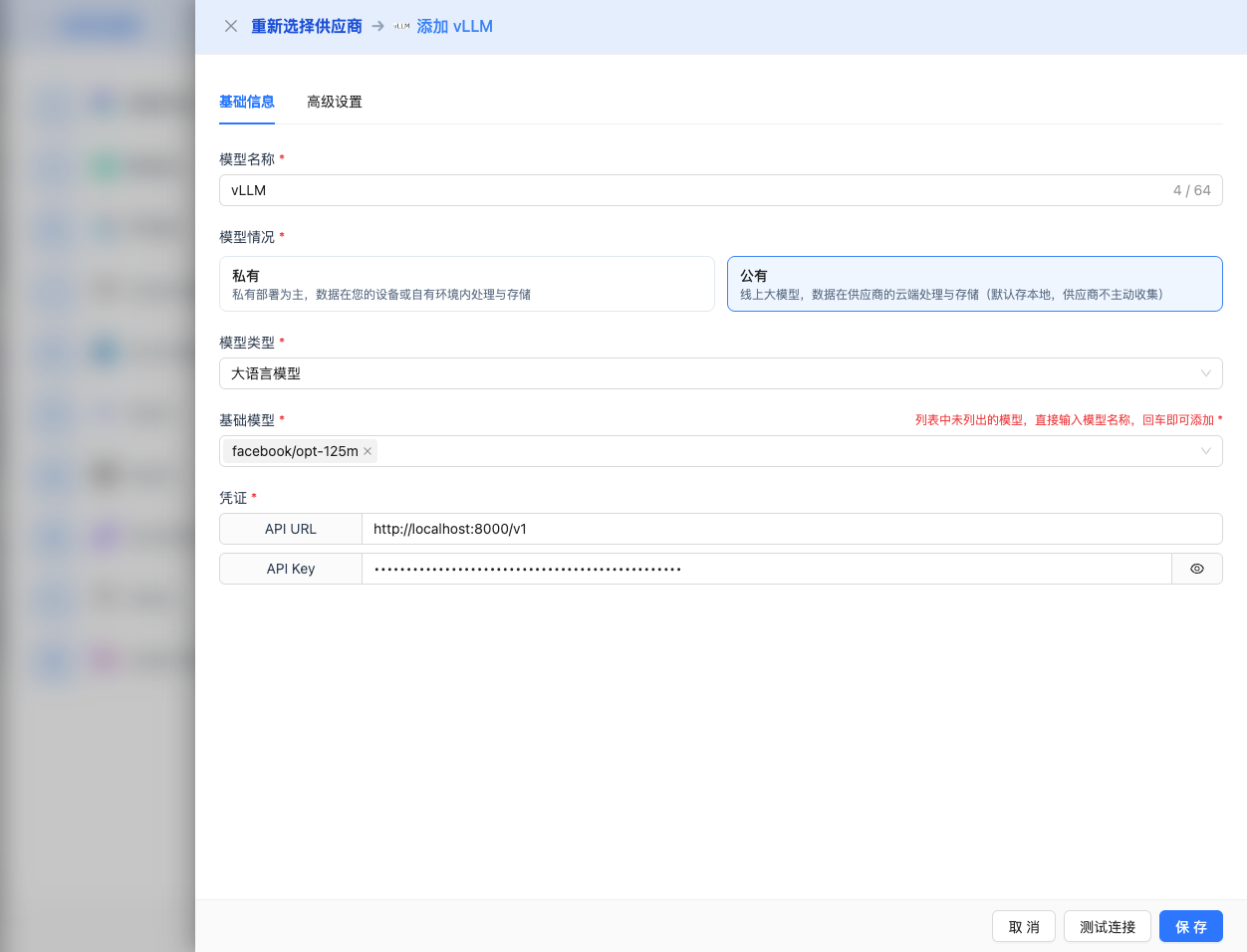
2.4 填寫配置資訊
在配置頁面填寫以下資訊:
基礎配置
- 模型名稱:為這個模型配置起個名字(例如:vLLM Qwen2.5 7B)
- API URL:保持預設
http://localhost:8000/v1(或修改為 vLLM 服務地址) - API Key:如果 vLLM 啟動時設定了
--api-key引數,填寫此處(可選) - 模型版本:輸入 vLLM 部署的模型名稱
2026 推薦模型:
Qwen/Qwen2.5-7B-Instruct:Qwen2.5 7B 對話模型(推薦)Qwen/Qwen2.5-14B-Instruct:Qwen2.5 14B 對話模型meta-llama/Meta-Llama-3.1-8B-Instruct:Llama 3.1 8B 對話模型meta-llama/Meta-Llama-3.1-70B-Instruct:Llama 3.1 70B 對話模型mistralai/Mistral-7B-Instruct-v0.3:Mistral 7B 對話模型deepseek-ai/DeepSeek-V2.5:DeepSeek V2.5 對話模型
注意:模型版本必須與 vLLM 啟動時的 --model 引數一致。
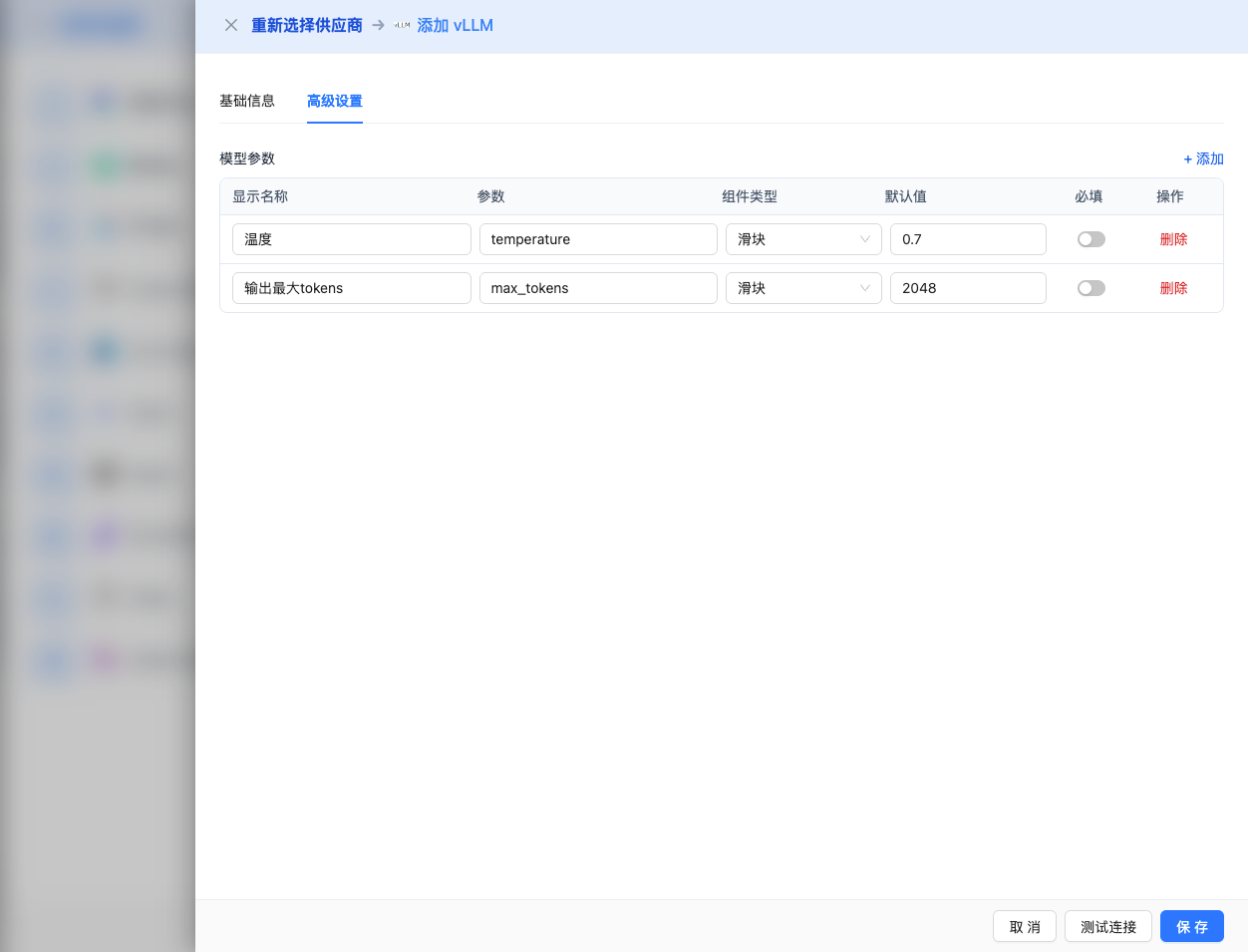
高階配置(可選)
展開 高階配置 面板,可以調整以下引數:
CueMate 介面可調引數:
溫度(temperature):控制輸出隨機性
- 範圍:0-2
- 推薦值:0.7
- 作用:值越高輸出越隨機創新,值越低輸出越穩定保守
- 使用建議:
- 創意寫作/頭腦風暴:1.0-1.5
- 常規對話/問答:0.7-0.9
- 程式碼生成/精確任務:0.3-0.5
輸出最大 tokens(max_tokens):限制單次輸出長度
- 範圍:256 - 131072(根據模型而定)
- 推薦值:8192
- 作用:控制模型單次響應的最大字數
- 模型限制:
- Qwen2.5 系列:最大 32K tokens
- Llama 3.1 系列:最大 131K tokens
- Mistral 系列:最大 32K tokens
- DeepSeek 系列:最大 65K tokens
- 使用建議:
- 簡短問答:1024-2048
- 常規對話:4096-8192
- 長文生成:16384-32768
- 超長文件:65536-131072(僅支援的模型)
vLLM API 支援的其他高階引數:
雖然 CueMate 介面只提供 temperature 和 max_tokens 調整,但如果你透過 API 直接呼叫 vLLM,還可以使用以下高階引數(vLLM 採用 OpenAI 相容的 API 格式):
top_p(nucleus sampling)
- 範圍:0-1
- 預設值:1
- 作用:從機率累積達到 p 的最小候選集中取樣
- 與 temperature 的關係:通常只調整其中一個
- 使用建議:
- 保持多樣性但避免離譜:0.9-0.95
- 更保守的輸出:0.7-0.8
top_k
- 範圍:-1(禁用)或正整數
- 預設值:-1
- 作用:從機率最高的 k 個候選詞中取樣
- 使用建議:
- 更多樣化:50-100
- 更保守:10-30
frequency_penalty(頻率懲罰)
- 範圍:-2.0 到 2.0
- 預設值:0
- 作用:降低重複相同詞彙的機率(基於詞頻)
- 使用建議:
- 減少重複:0.3-0.8
- 允許重複:0(預設)
presence_penalty(存在懲罰)
- 範圍:-2.0 到 2.0
- 預設值:0
- 作用:降低已出現過的詞彙再次出現的機率(基於是否出現)
- 使用建議:
- 鼓勵新話題:0.3-0.8
- 允許重複話題:0(預設)
stop(停止序列)
- 型別:字串或陣列
- 預設值:null
- 作用:當生成內容包含指定字串時停止
- 示例:
["###", "使用者:", "\n\n"] - 使用場景:
- 結構化輸出:使用分隔符控制格式
- 對話系統:防止模型代替使用者說話
stream(流式輸出)
- 型別:布林值
- 預設值:false
- 作用:啟用 SSE 流式返回,邊生成邊返回
- CueMate 中:自動處理,無需手動設定
best_of
- 型別:整數
- 預設值:1
- 範圍:1-20
- 作用:生成多個候選回覆,選擇最佳的一個返回
- 注意:會增加計算成本
use_beam_search
- 型別:布林值
- 預設值:false
- 作用:啟用束搜尋(beam search)演算法
- 使用場景:需要更確定性的輸出(如翻譯任務)
| 序號 | 場景 | temperature | max_tokens | top_p | top_k | frequency_penalty | presence_penalty |
|---|---|---|---|---|---|---|---|
| 1 | 創意寫作 | 1.0-1.2 | 4096-8192 | 0.95 | 50 | 0.5 | 0.5 |
| 2 | 程式碼生成 | 0.2-0.5 | 2048-4096 | 0.9 | 40 | 0.0 | 0.0 |
| 3 | 問答系統 | 0.7 | 1024-2048 | 0.9 | -1 | 0.0 | 0.0 |
| 4 | 摘要總結 | 0.3-0.5 | 512-1024 | 0.9 | 30 | 0.0 | 0.0 |
| 5 | 翻譯任務 | 0.0 | 2048 | 1.0 | -1 | 0.0 | 0.0 |
2.5 測試連線
填寫完配置後,點選 測試連線 按鈕,驗證配置是否正確。
如果配置正確,會顯示測試成功的提示,並返回模型的響應示例。
如果配置錯誤,會顯示測試錯誤的日誌,並且可以透過日誌管理,檢視具體報錯資訊。
2.6 儲存配置
測試成功後,點選 儲存 按鈕,完成模型配置。
3. 使用模型
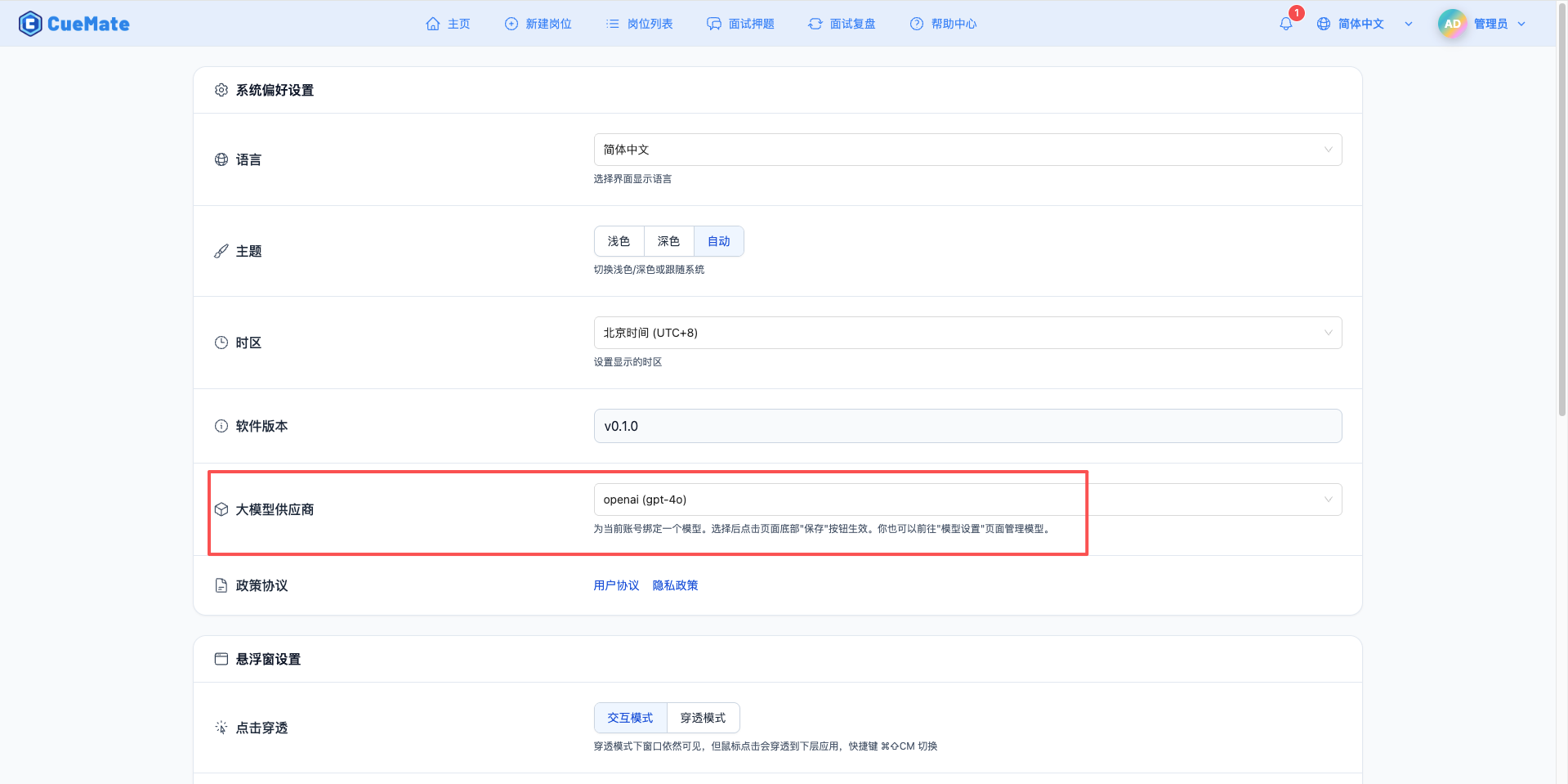
透過右上角下拉選單,進入系統設定介面,在大模型服務商欄目選擇想要使用的模型配置。
配置完成後,可以在面試訓練、問題生成等功能中選擇使用此模型, 當然也可以在面試的選項中單此選擇此次面試的模型配置。
4. 支援的模型列表
4.1 Qwen 系列(推薦)
| 序號 | 模型名稱 | 模型 ID | 引數量 | 最大輸出 | 適用場景 |
|---|---|---|---|---|---|
| 1 | Qwen2.5 7B Instruct | Qwen/Qwen2.5-7B-Instruct | 7B | 32K tokens | 中文對話、通用任務 |
| 2 | Qwen2.5 14B Instruct | Qwen/Qwen2.5-14B-Instruct | 14B | 32K tokens | 高質量中文對話 |
| 3 | Qwen2.5 32B Instruct | Qwen/Qwen2.5-32B-Instruct | 32B | 32K tokens | 複雜任務處理 |
| 4 | Qwen2.5 72B Instruct | Qwen/Qwen2.5-72B-Instruct | 72B | 32K tokens | 超高質量對話 |
4.2 Llama 3.1 系列
| 序號 | 模型名稱 | 模型 ID | 引數量 | 最大輸出 | 適用場景 |
|---|---|---|---|---|---|
| 1 | Llama 3.1 8B Instruct | meta-llama/Meta-Llama-3.1-8B-Instruct | 8B | 131K tokens | 英文對話、長文字 |
| 2 | Llama 3.1 70B Instruct | meta-llama/Meta-Llama-3.1-70B-Instruct | 70B | 131K tokens | 高質量英文對話 |
4.3 Mistral 系列
| 序號 | 模型名稱 | 模型 ID | 引數量 | 最大輸出 | 適用場景 |
|---|---|---|---|---|---|
| 1 | Mistral 7B Instruct | mistralai/Mistral-7B-Instruct-v0.3 | 7B | 32K tokens | 多語言對話 |
4.4 DeepSeek 系列
| 序號 | 模型名稱 | 模型 ID | 引數量 | 最大輸出 | 適用場景 |
|---|---|---|---|---|---|
| 1 | DeepSeek V2.5 | deepseek-ai/DeepSeek-V2.5 | 236B | 65K tokens | 程式碼生成、推理 |
注意:vLLM 支援 200+ HuggingFace Transformer 模型,只需在啟動時指定模型名稱。
4.5 多 GPU 部署
# 使用2個GPU進行張量並行
python -m vllm.entrypoints.openai.api_server \
--model BAAI/Aquila-7B \
--tensor-parallel-size 24.6 量化加速
# 使用AWQ 4-bit量化
python -m vllm.entrypoints.openai.api_server \
--model TheBloke/Llama-2-7B-Chat-AWQ \
--quantization awq4.7 PagedAttention
vLLM 的核心優勢是 PagedAttention 技術:
- 提升吞吐量高達 24 倍
- 顯著降低 GPU 記憶體使用
- 支援更大的 batch size
5. 常見問題
5.1 GPU 記憶體不足
現象:啟動 vLLM 時提示 CUDA OOM
解決方案:
- 使用量化模型(AWQ/GPTQ)
- 減小
--max-model-len引數 - 使用張量並行
--tensor-parallel-size - 選擇引數量更小的模型
5.2 模型載入失敗
現象:無法載入指定模型
解決方案:
- 確認模型名稱正確(HuggingFace 格式)
- 檢查網路連線,確保可以訪問 HuggingFace
- 預先下載模型到本地,使用本地路徑
- 檢視 vLLM 日誌獲取詳細錯誤資訊
5.3 效能不佳
現象:推理速度慢
解決方案:
- 確認 GPU 驅動和 CUDA 版本匹配
- 使用
--dtype half或--dtype bfloat16 - 調整
--max-num-seqs引數 - 啟用多 GPU 張量並行
5.4 服務無響應
現象:請求超時或掛起
解決方案:
- 檢查 vLLM 服務日誌
- 確認服務埠未被佔用
- 驗證防火牆設定
- 增加請求超時時間
5.5 硬體配置
| 模型大小 | GPU | 記憶體 | 建議配置 |
|---|---|---|---|
| <3B | RTX 3060 | 16GB | 單 GPU |
| 7B-13B | RTX 3090/4090 | 32GB | 單 GPU |
| 30B-70B | A100 40GB | 64GB | 多 GPU 並行 |
5.6 軟體最佳化
使用最新版本
bashpip install --upgrade vllm啟用 FlashAttention
bashpip install flash-attn調優引數
bash--max-num-batched-tokens 8192 \ --max-num-seqs 256 \ --dtype half
| 特性 | vLLM | Ollama | Xinference |
|---|---|---|---|
| 易用性 | 中等 | 非常好 | 較好 |
| 效能 | 非常高 | 一般 | 較高 |
| 功能 | 較豐富 | 基礎 | 非常豐富 |
| 生產級 | 非常成熟 | 一般 | 較成熟 |
| 適用場景 | 生產部署 | 個人開發 | 企業應用 |