
配置 vLLM
vLLM 是高性能的大语言模型推理和部署引擎,采用 PagedAttention 技术实现高吞吐量推理,支持多种开源模型。
1. 安装和部署 vLLM
1.1 访问 vLLM 官网
访问 vLLM 官网并查看文档:https://vllm.ai/
GitHub 仓库:https://github.com/vllm-project/vllm
1.2 环境要求
- 操作系统:Linux(推荐 Ubuntu 20.04+)
- Python:3.8-3.11
- GPU:NVIDIA GPU(支持 CUDA 11.8+)
- 内存:根据模型大小,建议 32GB+
重要提示:
- 注意:vLLM 仅支持 Linux + NVIDIA GPU
- 注意:macOS/Windows 用户必须使用 Docker 方式运行
- 注意:没有 NVIDIA GPU 的设备无法高性能运行 vLLM
1.3 安装 vLLM
方式一:Linux + NVIDIA GPU(推荐)
# 创建虚拟环境
python3 -m venv vllm-env
source vllm-env/bin/activate
# 安装vLLM
pip install vllm
# 验证安装
python -c "import vllm; print(vllm.__version__)"方式二:使用 Docker(跨平台,推荐 macOS/Windows 用户)
# 拉取vLLM官方镜像
docker pull vllm/vllm-openai:latest
# 运行vLLM服务(需要 NVIDIA GPU)
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model facebook/opt-125mDocker 拉取失败解决方案:
如果拉取镜像时遇到网络错误(如 failed to copy: httpReadSeeker),可以配置镜像加速:
# macOS Docker Desktop 配置
# 打开 Docker Desktop → Settings → Docker Engine
# 添加以下配置:
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live"
]
}
# 点击 Apply & Restart配置完成后重新拉取镜像。
1.4 启动 vLLM 服务
对于 Linux 用户:
# 启动vLLM OpenAI兼容服务器
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \
--port 8000对于 macOS/Windows 用户(使用 Docker):
由于 vLLM 需要 NVIDIA GPU,macOS/Windows 用户无法本地运行,建议:
- 在有 NVIDIA GPU 的 Linux 服务器上部署 vLLM
- 在 CueMate 中配置远程服务器地址(如
http://192.168.1.100:8000/v1) - 或使用其他支持 macOS 的本地推理框架(如 Ollama)
常用启动参数:
--model:模型名称或路径--host:服务监听地址(默认 0.0.0.0)--port:服务端口(默认 8000)--tensor-parallel-size:张量并行大小(多 GPU)--dtype:数据类型(auto/half/float16/bfloat16)
1.5 验证服务运行
# 检查服务状态
curl http://localhost:8000/v1/models正常返回结果示例:
{
"object": "list",
"data": [
{
"id": "Qwen/Qwen2.5-7B-Instruct",
"object": "model",
"created": 1699234567,
"owned_by": "vllm",
"root": "Qwen/Qwen2.5-7B-Instruct",
"parent": null,
"permission": [
{
"id": "modelperm-xxx",
"object": "model_permission",
"created": 1699234567,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}如果返回上述 JSON 内容,说明 vLLM 服务启动成功。
如果服务未启动或配置错误,会返回:
# 连接失败
curl: (7) Failed to connect to localhost port 8000: Connection refused
# 或者 404 错误
{"detail":"Not Found"}2. 在 CueMate 中配置 vLLM 模型
2.1 进入模型设置页面
登录 CueMate 系统后,点击右上角下拉菜单的 模型设置。
2.2 添加新模型
点击右上角的 添加模型 按钮。

2.3 选择 vLLM 服务商
在弹出的对话框中:
- 服务商类型:选择 vLLM
- 点击后 自动进入下一步
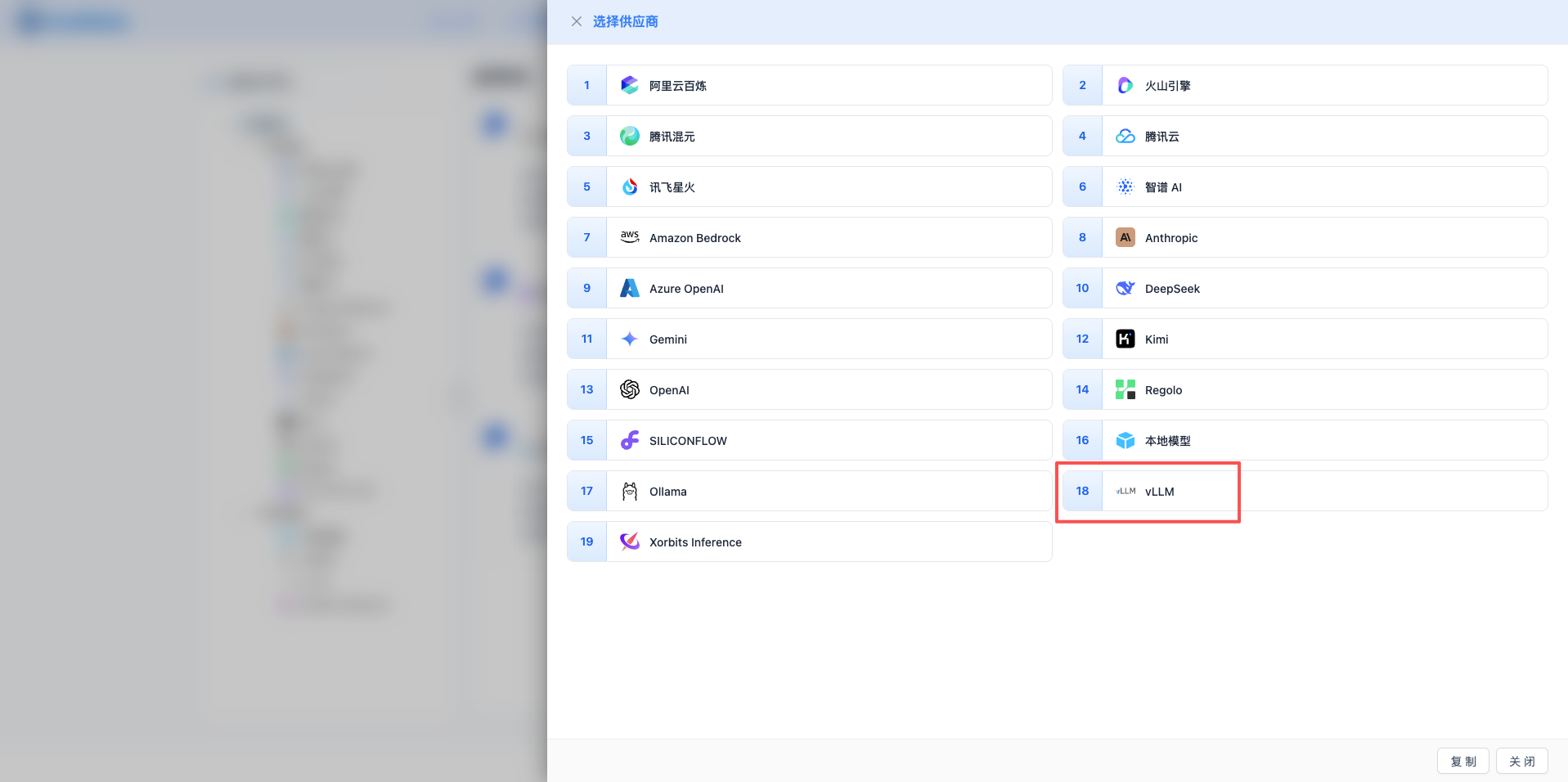
2.4 填写配置信息
在配置页面填写以下信息:
基础配置
- 模型名称:为这个模型配置起个名字(例如:vLLM Qwen2.5 7B)
- API URL:保持默认
http://localhost:8000/v1(或修改为 vLLM 服务地址) - API Key:如果 vLLM 启动时设置了
--api-key参数,填写此处(可选) - 模型版本:输入 vLLM 部署的模型名称
2025 推荐模型:
Qwen/Qwen2.5-7B-Instruct:Qwen2.5 7B 对话模型(推荐)Qwen/Qwen2.5-14B-Instruct:Qwen2.5 14B 对话模型meta-llama/Meta-Llama-3.1-8B-Instruct:Llama 3.1 8B 对话模型meta-llama/Meta-Llama-3.1-70B-Instruct:Llama 3.1 70B 对话模型mistralai/Mistral-7B-Instruct-v0.3:Mistral 7B 对话模型deepseek-ai/DeepSeek-V2.5:DeepSeek V2.5 对话模型
注意:模型版本必须与 vLLM 启动时的 --model 参数一致。
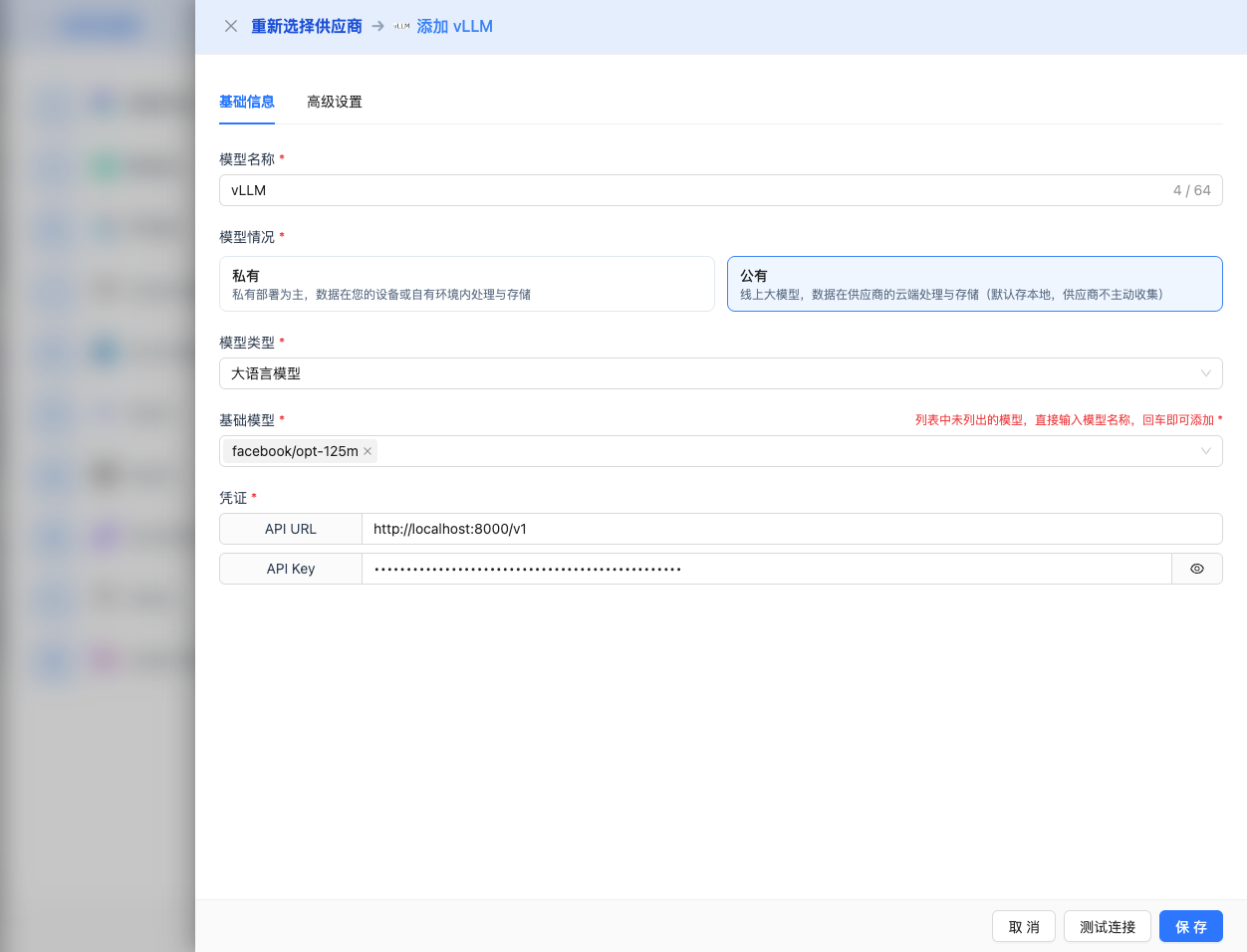
高级配置(可选)
展开 高级配置 面板,可以调整以下参数:
CueMate 界面可调参数:
温度(temperature):控制输出随机性
- 范围:0-2
- 推荐值:0.7
- 作用:值越高输出越随机创新,值越低输出越稳定保守
- 使用建议:
- 创意写作/头脑风暴:1.0-1.5
- 常规对话/问答:0.7-0.9
- 代码生成/精确任务:0.3-0.5
输出最大 tokens(max_tokens):限制单次输出长度
- 范围:256 - 131072(根据模型而定)
- 推荐值:8192
- 作用:控制模型单次响应的最大字数
- 模型限制:
- Qwen2.5 系列:最大 32K tokens
- Llama 3.1 系列:最大 131K tokens
- Mistral 系列:最大 32K tokens
- DeepSeek 系列:最大 65K tokens
- 使用建议:
- 简短问答:1024-2048
- 常规对话:4096-8192
- 长文生成:16384-32768
- 超长文档:65536-131072(仅支持的模型)
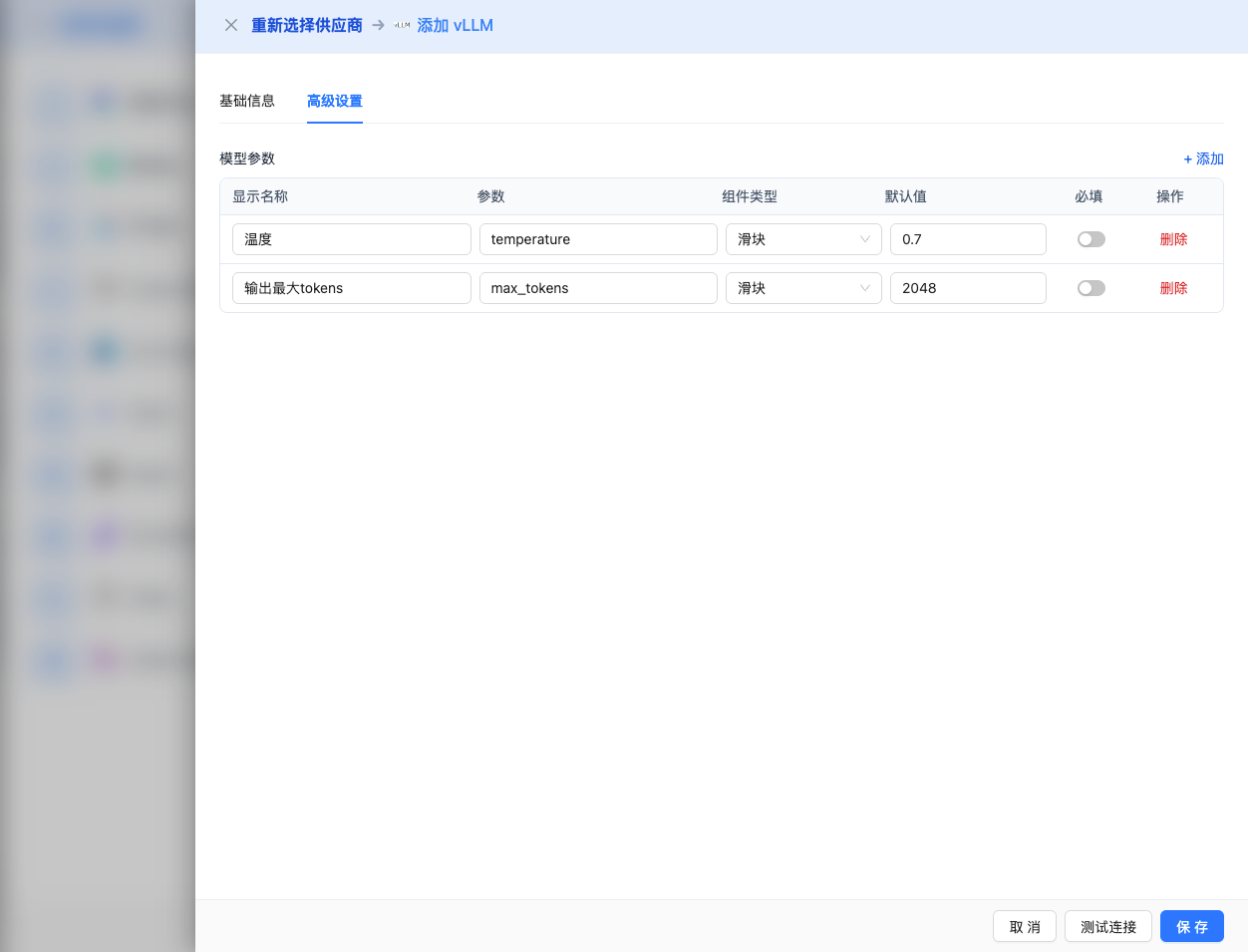
vLLM API 支持的其他高级参数:
虽然 CueMate 界面只提供 temperature 和 max_tokens 调整,但如果你通过 API 直接调用 vLLM,还可以使用以下高级参数(vLLM 采用 OpenAI 兼容的 API 格式):
top_p(nucleus sampling)
- 范围:0-1
- 默认值:1
- 作用:从概率累积达到 p 的最小候选集中采样
- 与 temperature 的关系:通常只调整其中一个
- 使用建议:
- 保持多样性但避免离谱:0.9-0.95
- 更保守的输出:0.7-0.8
top_k
- 范围:-1(禁用)或正整数
- 默认值:-1
- 作用:从概率最高的 k 个候选词中采样
- 使用建议:
- 更多样化:50-100
- 更保守:10-30
frequency_penalty(频率惩罚)
- 范围:-2.0 到 2.0
- 默认值:0
- 作用:降低重复相同词汇的概率(基于词频)
- 使用建议:
- 减少重复:0.3-0.8
- 允许重复:0(默认)
presence_penalty(存在惩罚)
- 范围:-2.0 到 2.0
- 默认值:0
- 作用:降低已出现过的词汇再次出现的概率(基于是否出现)
- 使用建议:
- 鼓励新话题:0.3-0.8
- 允许重复话题:0(默认)
stop(停止序列)
- 类型:字符串或数组
- 默认值:null
- 作用:当生成内容包含指定字符串时停止
- 示例:
["###", "用户:", "\n\n"] - 使用场景:
- 结构化输出:使用分隔符控制格式
- 对话系统:防止模型代替用户说话
stream(流式输出)
- 类型:布尔值
- 默认值:false
- 作用:启用 SSE 流式返回,边生成边返回
- CueMate 中:自动处理,无需手动设置
best_of
- 类型:整数
- 默认值:1
- 范围:1-20
- 作用:生成多个候选回复,选择最佳的一个返回
- 注意:会增加计算成本
use_beam_search
- 类型:布尔值
- 默认值:false
- 作用:启用束搜索(beam search)算法
- 使用场景:需要更确定性的输出(如翻译任务)
| 序号 | 场景 | temperature | max_tokens | top_p | top_k | frequency_penalty | presence_penalty |
|---|---|---|---|---|---|---|---|
| 1 | 创意写作 | 1.0-1.2 | 4096-8192 | 0.95 | 50 | 0.5 | 0.5 |
| 2 | 代码生成 | 0.2-0.5 | 2048-4096 | 0.9 | 40 | 0.0 | 0.0 |
| 3 | 问答系统 | 0.7 | 1024-2048 | 0.9 | -1 | 0.0 | 0.0 |
| 4 | 摘要总结 | 0.3-0.5 | 512-1024 | 0.9 | 30 | 0.0 | 0.0 |
| 5 | 翻译任务 | 0.0 | 2048 | 1.0 | -1 | 0.0 | 0.0 |
2.5 测试连接
填写完配置后,点击 测试连接 按钮,验证配置是否正确。
如果配置正确,会显示测试成功的提示,并返回模型的响应示例。
如果配置错误,会显示测试错误的日志,并且可以通过日志管理,查看具体报错信息。
2.6 保存配置
测试成功后,点击 保存 按钮,完成模型配置。
3. 使用模型
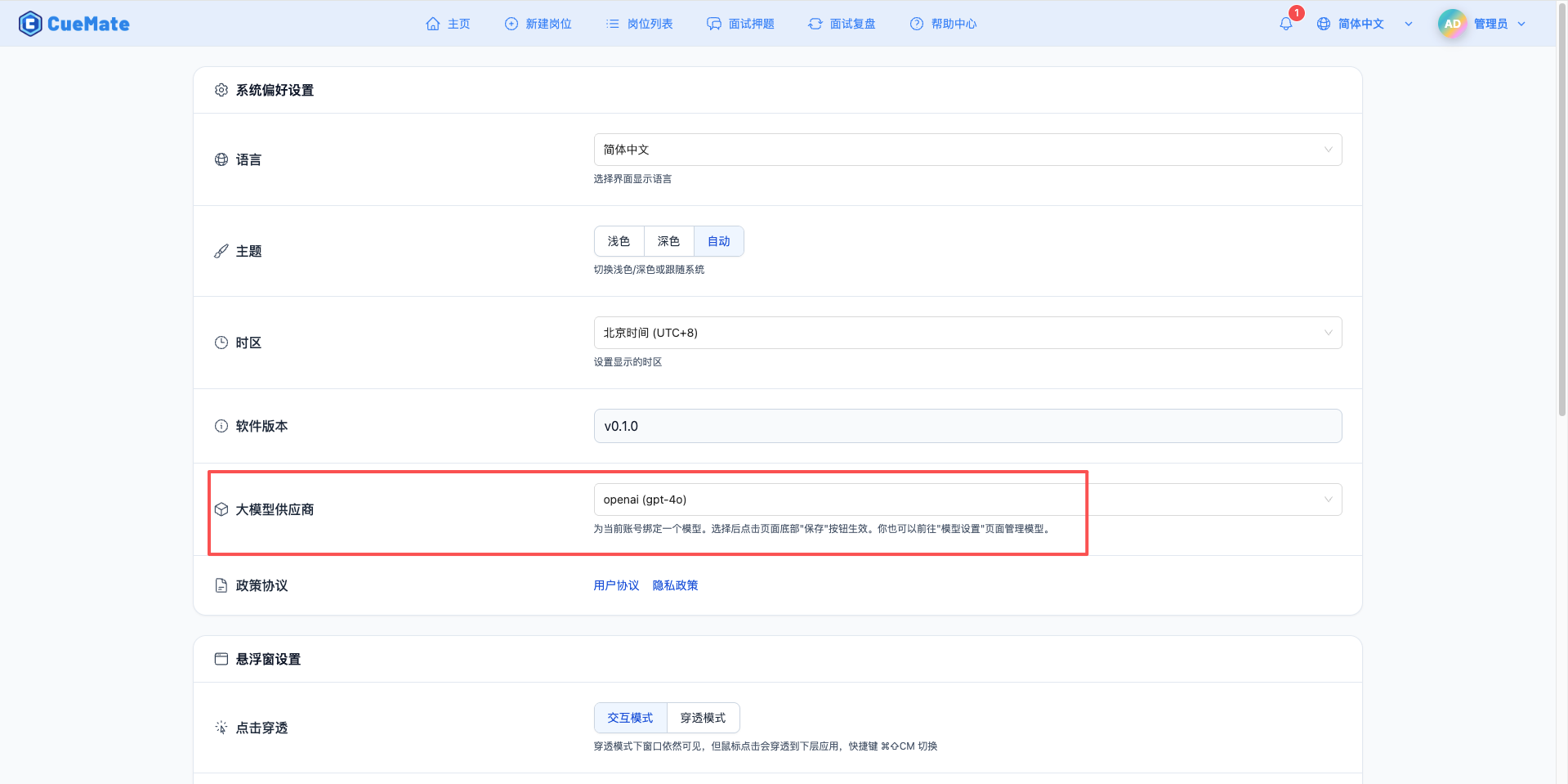
通过右上角下拉菜单,进入系统设置界面,在大模型服务商栏目选择想要使用的模型配置。
配置完成后,可以在面试训练、问题生成等功能中选择使用此模型, 当然也可以在面试的选项中单此选择此次面试的模型配置。
4. 支持的模型列表
4.1 Qwen 系列(推荐)
| 序号 | 模型名称 | 模型 ID | 参数量 | 最大输出 | 适用场景 |
|---|---|---|---|---|---|
| 1 | Qwen2.5 7B Instruct | Qwen/Qwen2.5-7B-Instruct | 7B | 32K tokens | 中文对话、通用任务 |
| 2 | Qwen2.5 14B Instruct | Qwen/Qwen2.5-14B-Instruct | 14B | 32K tokens | 高质量中文对话 |
| 3 | Qwen2.5 32B Instruct | Qwen/Qwen2.5-32B-Instruct | 32B | 32K tokens | 复杂任务处理 |
| 4 | Qwen2.5 72B Instruct | Qwen/Qwen2.5-72B-Instruct | 72B | 32K tokens | 超高质量对话 |
4.2 Llama 3.1 系列
| 序号 | 模型名称 | 模型 ID | 参数量 | 最大输出 | 适用场景 |
|---|---|---|---|---|---|
| 1 | Llama 3.1 8B Instruct | meta-llama/Meta-Llama-3.1-8B-Instruct | 8B | 131K tokens | 英文对话、长文本 |
| 2 | Llama 3.1 70B Instruct | meta-llama/Meta-Llama-3.1-70B-Instruct | 70B | 131K tokens | 高质量英文对话 |
4.3 Mistral 系列
| 序号 | 模型名称 | 模型 ID | 参数量 | 最大输出 | 适用场景 |
|---|---|---|---|---|---|
| 1 | Mistral 7B Instruct | mistralai/Mistral-7B-Instruct-v0.3 | 7B | 32K tokens | 多语言对话 |
4.4 DeepSeek 系列
| 序号 | 模型名称 | 模型 ID | 参数量 | 最大输出 | 适用场景 |
|---|---|---|---|---|---|
| 1 | DeepSeek V2.5 | deepseek-ai/DeepSeek-V2.5 | 236B | 65K tokens | 代码生成、推理 |
注意:vLLM 支持 200+ HuggingFace Transformer 模型,只需在启动时指定模型名称。
4.5 多 GPU 部署
# 使用2个GPU进行张量并行
python -m vllm.entrypoints.openai.api_server \
--model BAAI/Aquila-7B \
--tensor-parallel-size 24.6 量化加速
# 使用AWQ 4-bit量化
python -m vllm.entrypoints.openai.api_server \
--model TheBloke/Llama-2-7B-Chat-AWQ \
--quantization awq4.7 PagedAttention
vLLM 的核心优势是 PagedAttention 技术:
- 提升吞吐量高达 24 倍
- 显著降低 GPU 内存使用
- 支持更大的 batch size
5. 常见问题
5.1 GPU 内存不足
现象:启动 vLLM 时提示 CUDA OOM
解决方案:
- 使用量化模型(AWQ/GPTQ)
- 减小
--max-model-len参数 - 使用张量并行
--tensor-parallel-size - 选择参数量更小的模型
5.2 模型加载失败
现象:无法加载指定模型
解决方案:
- 确认模型名称正确(HuggingFace 格式)
- 检查网络连接,确保可以访问 HuggingFace
- 预先下载模型到本地,使用本地路径
- 查看 vLLM 日志获取详细错误信息
5.3 性能不佳
现象:推理速度慢
解决方案:
- 确认 GPU 驱动和 CUDA 版本匹配
- 使用
--dtype half或--dtype bfloat16 - 调整
--max-num-seqs参数 - 启用多 GPU 张量并行
5.4 服务无响应
现象:请求超时或挂起
解决方案:
- 检查 vLLM 服务日志
- 确认服务端口未被占用
- 验证防火墙设置
- 增加请求超时时间
5.5 硬件配置
| 模型大小 | GPU | 内存 | 建议配置 |
|---|---|---|---|
| <3B | RTX 3060 | 16GB | 单 GPU |
| 7B-13B | RTX 3090/4090 | 32GB | 单 GPU |
| 30B-70B | A100 40GB | 64GB | 多 GPU 并行 |
5.6 软件优化
使用最新版本
bashpip install --upgrade vllm启用 FlashAttention
bashpip install flash-attn调优参数
bash--max-num-batched-tokens 8192 \ --max-num-seqs 256 \ --dtype half
| 特性 | vLLM | Ollama | Xinference |
|---|---|---|---|
| 易用性 | 中等 | 非常好 | 较好 |
| 性能 | 非常高 | 一般 | 较高 |
| 功能 | 较丰富 | 基础 | 非常丰富 |
| 生产级 | 非常成熟 | 一般 | 较成熟 |
| 适用场景 | 生产部署 | 个人开发 | 企业应用 |