
配置本地大模型
本地大模型是指在个人电脑或私有服务器上部署的开源大语言模型,无需依赖云端 API。支持多种推理框架(Ollama、vLLM、Xinference 等),提供数据隐私保护和完全离线运行能力。
1. 部署本地模型服务
本地大模型支持多种推理框架,包括 Ollama、vLLM、Xinference 等。本文档以通用方式介绍如何配置本地模型服务。
1.1 选择推理框架
根据您的需求选择合适的推理框架:
- Ollama:易于使用,适合个人开发者
- vLLM:高性能推理,适合生产环境
- Xinference:支持多种模型,功能丰富
详细安装说明请参考各框架的独立文档:
1.2 启动本地服务
以 Ollama 为例:
# 下载模型
ollama pull deepseek-r1:7b
# Ollama 会自动启动服务,默认监听 http://localhost:114341.3 验证服务运行
# 检查服务状态
curl http://localhost:11434/api/version2. 在 CueMate 中配置本地模型
2.1 进入模型设置页面
登录 CueMate 系统后,点击右上角下拉菜单的 模型设置。
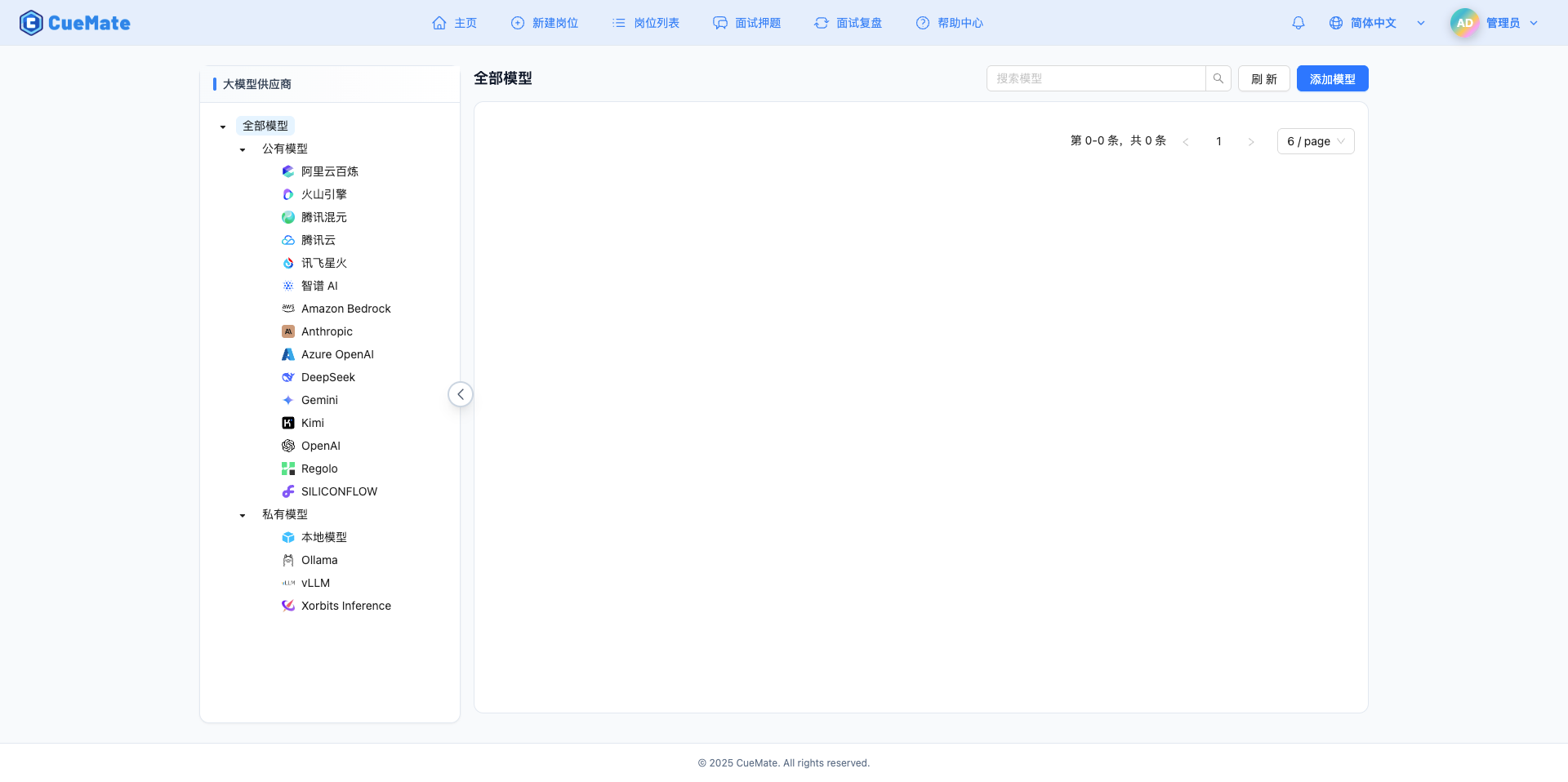
2.2 添加新模型
点击右上角的 添加模型 按钮。

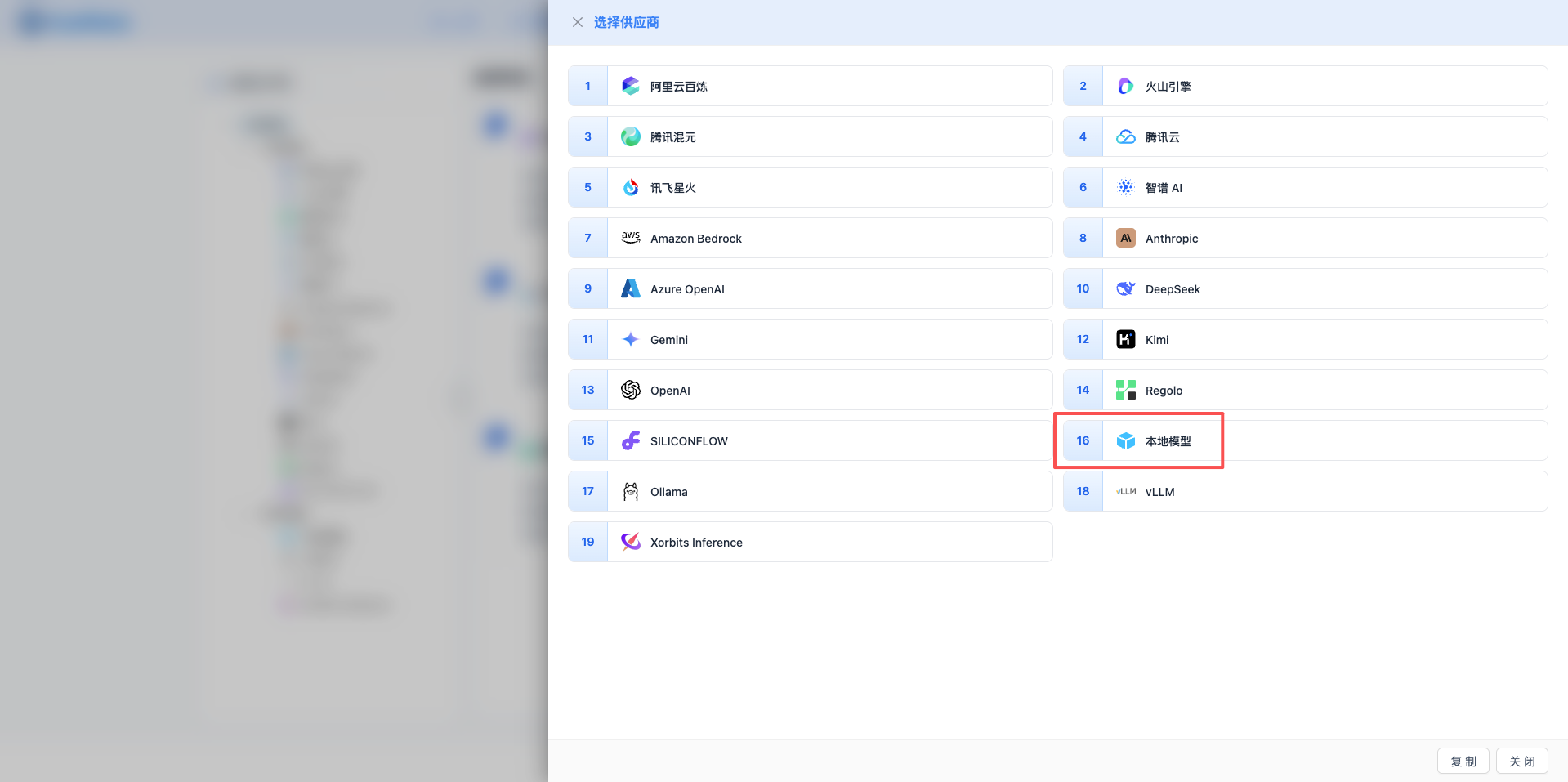
2.3 选择本地模型服务商
在弹出的对话框中:
- 服务商类型:选择 本地模型
- 点击后 自动进入下一步
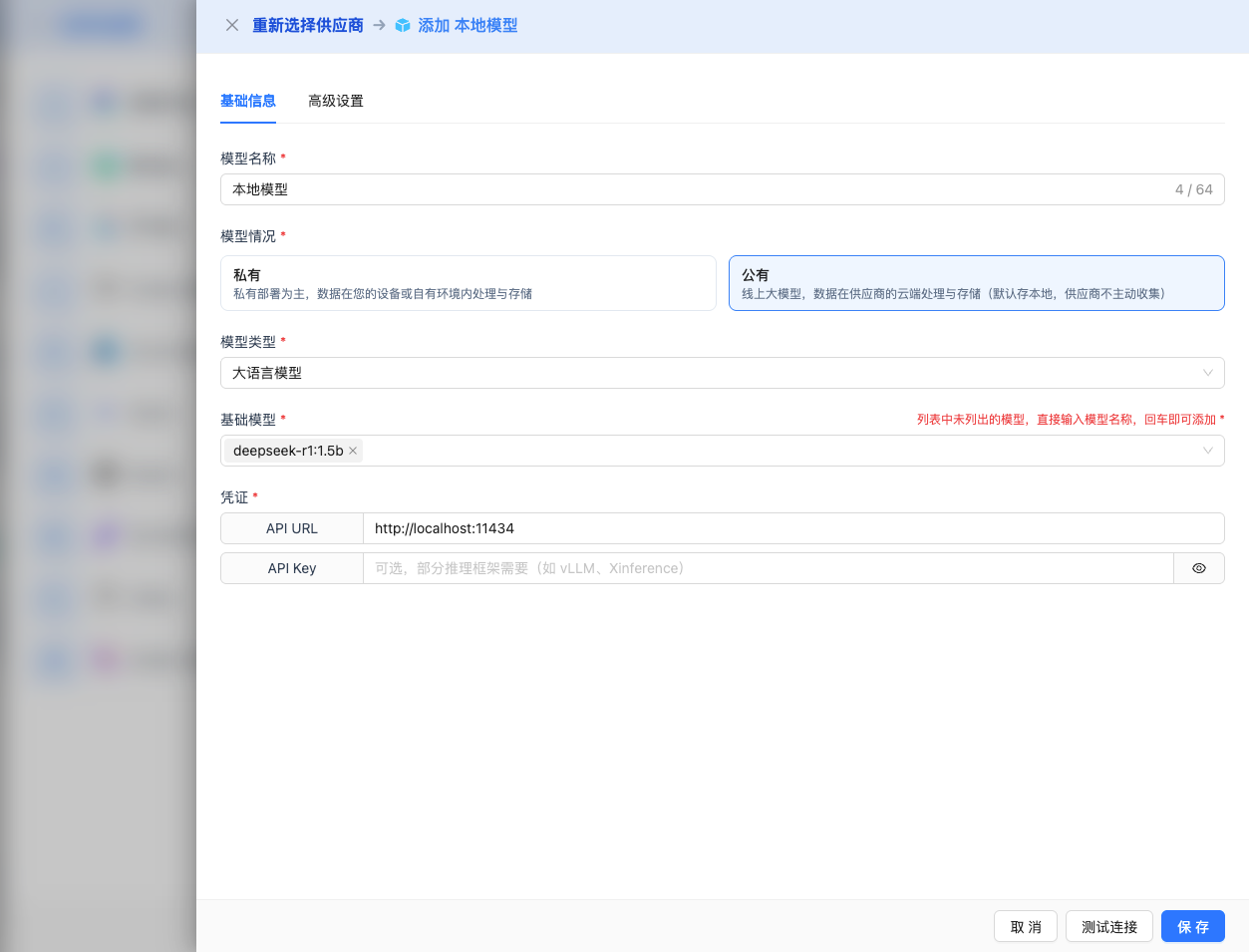
2.4 填写配置信息
在配置页面填写以下信息:
基础配置
- 模型名称:为这个模型配置起个名字(例如:本地 DeepSeek R1)
- API URL:填写本地服务地址
- Ollama 默认:
http://localhost:11434 - vLLM 默认:
http://localhost:8000/v1 - Xinference 默认:
http://localhost:9997/v1
- Ollama 默认:
- 模型版本:输入已部署的模型名称
2025 推荐模型:
- DeepSeek R1 系列:
deepseek-r1:1.5b、deepseek-r1:7b、deepseek-r1:14b、deepseek-r1:32b - Llama 3.3 系列:
llama3.3:70b(最新版本) - Llama 3.2 系列:
llama3.2:1b、llama3.2:3b、llama3.2:11b、llama3.2:90b - Llama 3.1 系列:
llama3.1:8b、llama3.1:70b、llama3.1:405b - Qwen 2.5 系列:
qwen2.5:0.5b、qwen2.5:1.5b、qwen2.5:3b、qwen2.5:7b、qwen2.5:14b、qwen2.5:32b、qwen2.5:72b
注意:模型版本必须是已在本地服务中部署的模型。不同推理框架的模型命名可能略有不同,请根据实际情况调整。
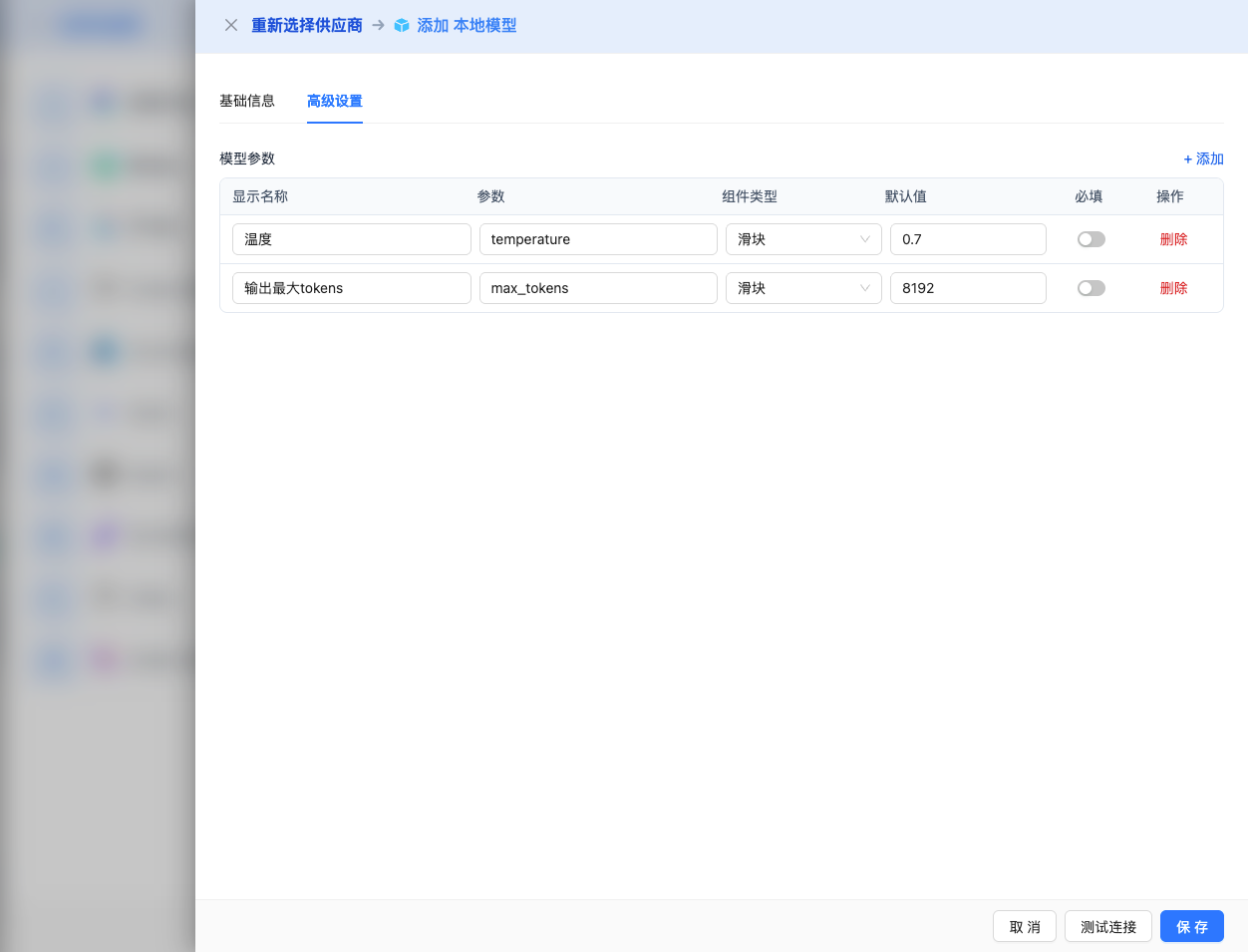
高级配置(可选)
展开 高级配置 面板,可以调整以下参数:
CueMate 界面可调参数:
温度(temperature):控制输出随机性
- 范围:0-2(根据模型而定)
- 推荐值:0.7
- 作用:值越高输出越随机创新,值越低输出越稳定保守
- 模型范围:
- DeepSeek/Llama 系列:0-2
- Qwen 系列:0-1
- 使用建议:
- 创意写作:0.8-1.2
- 常规对话:0.6-0.8
- 代码生成:0.3-0.5
输出最大 tokens(max_tokens):限制单次输出长度
- 范围:256 - 8192
- 推荐值:4096
- 作用:控制模型单次响应的最大字数
- 使用建议:
- 简短问答:1024-2048
- 常规对话:4096-8192
- 长文生成:8192(最大)
本地模型 API 支持的其他参数:
本地模型服务(Ollama、vLLM、Xinference)通常采用 OpenAI 兼容的 API 格式,支持以下高级参数:
top_p(nucleus sampling)
- 范围:0-1
- 默认值:0.9
- 作用:从概率累积达到 p 的最小候选集中采样
- 使用建议:保持默认 0.9,与 temperature 通常只调整一个
top_k
- 范围:1-100
- 默认值:40(Ollama),50(vLLM)
- 作用:从概率最高的 k 个候选词中采样
- 使用建议:通常保持默认值
frequency_penalty(频率惩罚)
- 范围:-2.0 到 2.0
- 默认值:0
- 作用:降低重复相同词汇的概率
- 使用建议:减少重复时设为 0.3-0.8
presence_penalty(存在惩罚)
- 范围:-2.0 到 2.0
- 默认值:0
- 作用:降低已出现过的词汇再次出现的概率
- 使用建议:鼓励新话题时设为 0.3-0.8
stream(流式输出)
- 类型:布尔值
- 默认值:false
- 作用:启用流式返回,边生成边返回
- CueMate 中:自动处理,无需手动设置
| 场景 | temperature | max_tokens | top_p | 推荐模型 |
|---|---|---|---|---|
| 创意写作 | 0.8-1.0 | 4096-8192 | 0.9 | DeepSeek R1 7B/14B |
| 代码生成 | 0.3-0.5 | 2048-4096 | 0.9 | Qwen 2.5 7B/14B |
| 问答系统 | 0.7 | 1024-2048 | 0.9 | Llama 3.2 11B |
| 技术面试 | 0.6-0.7 | 2048-4096 | 0.9 | DeepSeek R1 7B/14B |
| 快速响应 | 0.5 | 1024-2048 | 0.9 | Llama 3.2 3B |
2.5 测试连接
填写完配置后,点击 测试连接 按钮,验证配置是否正确。
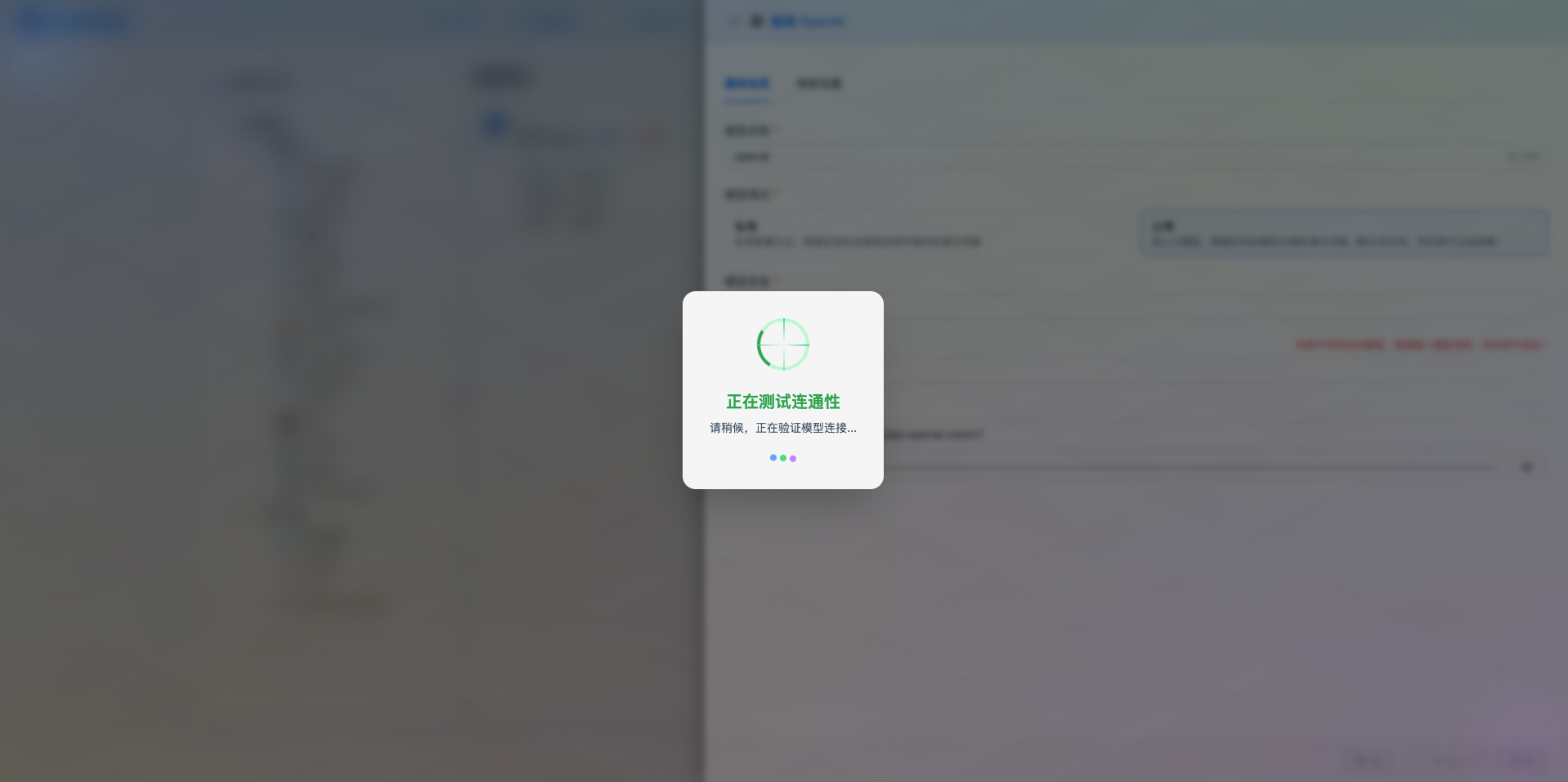
如果配置正确,会显示测试成功的提示,并返回模型的响应示例。
如果配置错误,会显示测试错误的日志,并且可以通过日志管理,查看具体报错信息。
2.6 保存配置
测试成功后,点击 保存 按钮,完成模型配置。
3. 使用模型
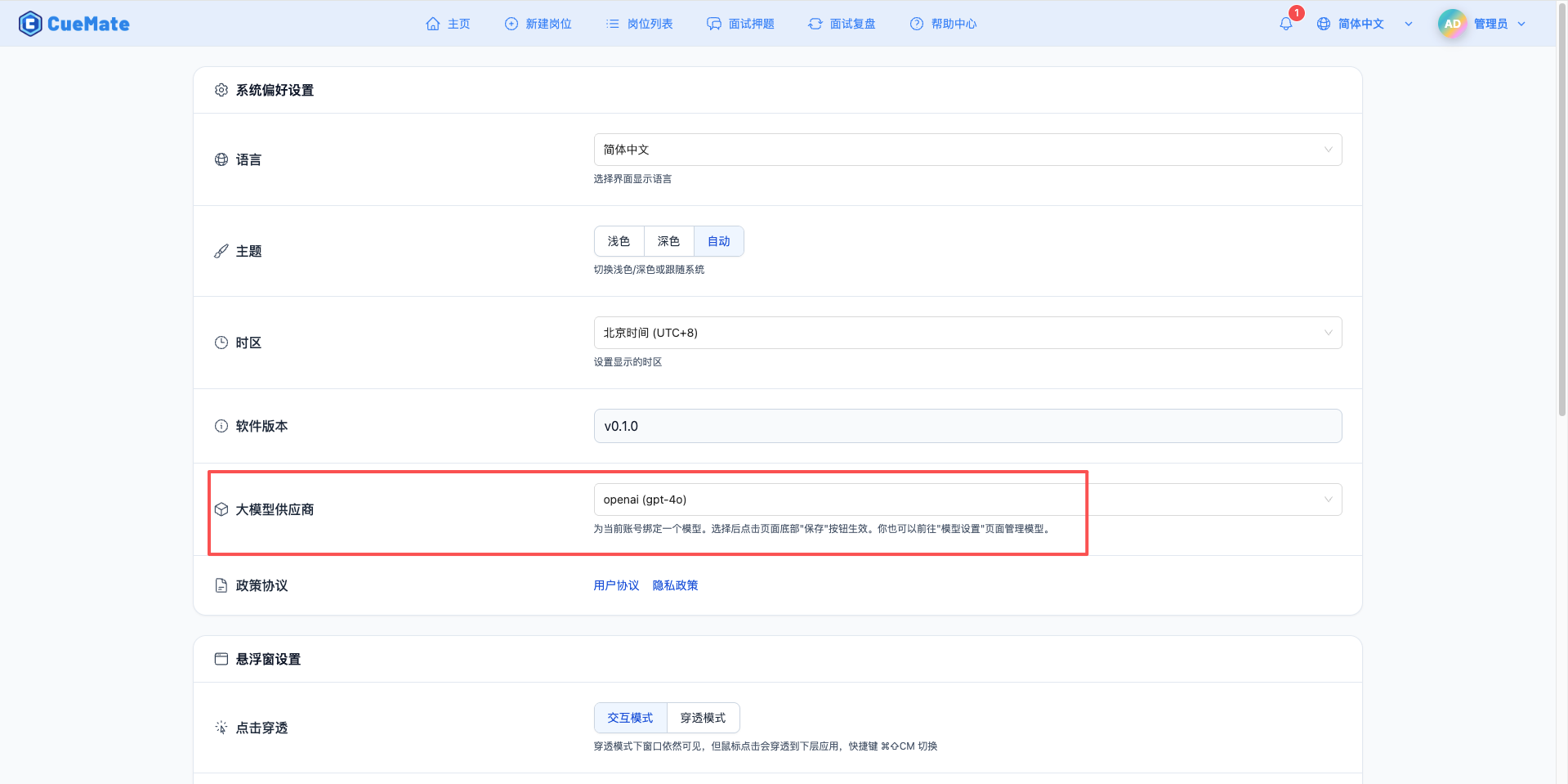
通过右上角下拉菜单,进入系统设置界面,在大模型服务商栏目选择想要使用的模型配置。
配置完成后,可以在面试训练、问题生成等功能中选择使用此模型, 当然也可以在面试的选项中单此选择此次面试的模型配置。
4. 支持的模型系列
DeepSeek R1 系列
| 模型名称 | 模型 ID | 参数量 | 最大输出 | 适用场景 |
|---|---|---|---|---|
| DeepSeek R1 1.5B | deepseek-r1:1.5b | 1.5B | 8K tokens | 轻量级推理 |
| DeepSeek R1 7B | deepseek-r1:7b | 7B | 8K tokens | 推理增强、技术面试 |
| DeepSeek R1 14B | deepseek-r1:14b | 14B | 8K tokens | 高性能推理 |
| DeepSeek R1 32B | deepseek-r1:32b | 32B | 8K tokens | 超强推理能力 |
Llama 3 系列
| 模型名称 | 模型 ID | 参数量 | 最大输出 | 适用场景 |
|---|---|---|---|---|
| Llama 3.3 70B | llama3.3:70b | 70B | 8K tokens | 最新版本、高性能 |
| Llama 3.2 90B | llama3.2:90b | 90B | 8K tokens | 超大规模推理 |
| Llama 3.2 11B | llama3.2:11b | 11B | 8K tokens | 中等规模任务 |
| Llama 3.2 3B | llama3.2:3b | 3B | 8K tokens | 小规模任务 |
| Llama 3.2 1B | llama3.2:1b | 1B | 8K tokens | 超轻量级 |
| Llama 3.1 405B | llama3.1:405b | 405B | 8K tokens | 超大规模推理 |
| Llama 3.1 70B | llama3.1:70b | 70B | 8K tokens | 大规模任务 |
| Llama 3.1 8B | llama3.1:8b | 8B | 8K tokens | 标准任务 |
Qwen 2.5 系列
| 模型名称 | 模型 ID | 参数量 | 最大输出 | 适用场景 |
|---|---|---|---|---|
| Qwen 2.5 72B | qwen2.5:72b | 72B | 8K tokens | 超大规模任务 |
| Qwen 2.5 32B | qwen2.5:32b | 32B | 8K tokens | 大规模任务 |
| Qwen 2.5 14B | qwen2.5:14b | 14B | 8K tokens | 中等规模任务 |
| Qwen 2.5 7B | qwen2.5:7b | 7B | 8K tokens | 通用场景、性价比高 |
| Qwen 2.5 3B | qwen2.5:3b | 3B | 8K tokens | 小规模任务 |
| Qwen 2.5 1.5B | qwen2.5:1.5b | 1.5B | 8K tokens | 轻量级任务 |
| Qwen 2.5 0.5B | qwen2.5:0.5b | 0.5B | 8K tokens | 超轻量级 |
5. 常见问题
服务连接失败
现象:测试连接时提示无法连接
解决方案:
- 确认本地推理服务是否运行
- 检查 API URL 配置是否正确
- 验证端口是否被占用
- 检查防火墙设置
模型未部署
现象:提示模型不存在
解决方案:
- 确认模型已在本地服务中部署
- 检查模型名称拼写是否正确
- 查看推理服务的模型列表
性能问题
现象:模型响应速度慢
解决方案:
- 选择参数量较小的模型
- 确保有足够的 GPU 内存或系统内存
- 优化推理框架配置
- 考虑使用量化模型
内存不足
现象:模型加载失败或系统卡顿
解决方案:
- 选择更小参数量的模型
- 使用量化版本(如 4-bit、8-bit)
- 增加系统内存或使用 GPU
- 调整推理框架的内存配置
最低配置
| 模型参数 | CPU | 内存 | GPU |
|---|---|---|---|
| 0.5B-3B | 4 核 | 8GB | 可选 |
| 7B-14B | 8 核 | 16GB | 推荐 |
| 32B-70B | 16 核 | 64GB | 必需 |
推荐配置
| 模型参数 | CPU | 内存 | GPU |
|---|---|---|---|
| 0.5B-3B | 8 核 | 16GB | GTX 1660 |
| 7B-14B | 16 核 | 32GB | RTX 3060 |
| 32B-70B | 32 核 | 128GB | RTX 4090 |
数据隐私
- 所有数据处理在本地完成
- 不依赖外部 API 服务
- 完全掌控数据安全
成本控制
- 无 API 调用费用
- 一次性硬件投入
- 长期使用成本低
灵活性
- 支持自定义模型
- 可调整推理参数
- 完全控制服务配置
适用场景
- 企业内部部署
- 敏感数据处理
- 离线环境使用
- 开发测试环境