语音识别设置
语音识别设置页面用于配置 FunASR 语音识别服务、AudioTee 系统音频捕获、Piper TTS 语音合成、音频设备和测试参数。所有设置统一保存到服务器,并自动同步到桌面客户端。
注:默认所有配置都有默认值,除了本地的麦克风和扬声器需要额外配置。
1. 进入语音识别设置
点击顶部下拉列表菜单中的"语音设置",进入设置页面。
页面包含五个配置标签页:
- 设备配置:麦克风和扬声器设置
- FunASR 配置:语音识别服务参数
- AudioTee 配置:系统音频捕获配置
- Piper TTS 配置:语音合成参数
- 测试配置:测试参数设置

2. 设备配置
NOTE
设备配置需要桌面客户端正常运行。Web 端会自动从桌面客户端获取设备列表,请确保桌面应用已启动。
2.1 麦克风设置
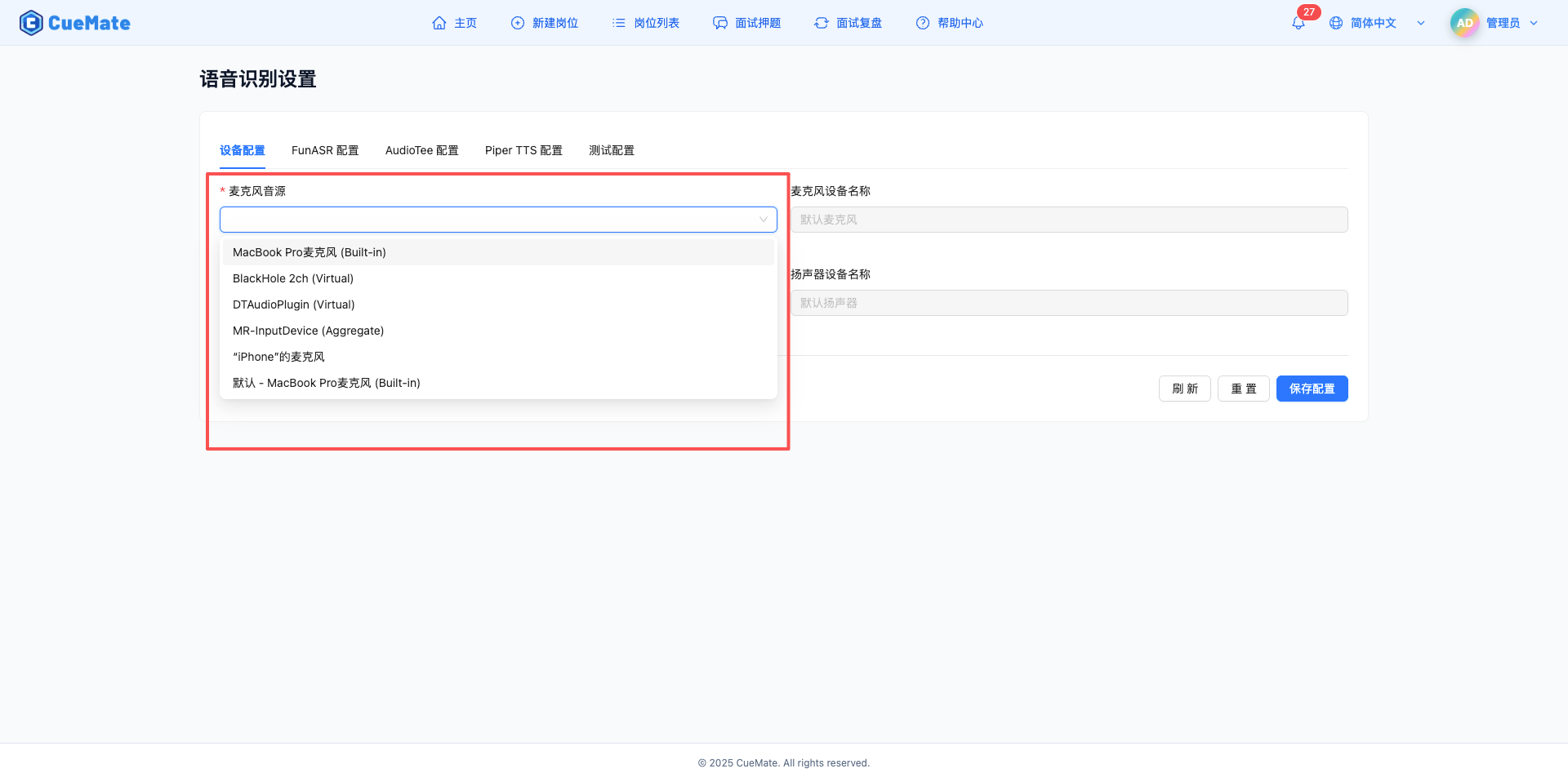
在"设备配置"标签页,配置麦克风音频输入设备。
TIP
推荐设备选择:
- 首选:电脑内置麦克风(简单方便)
- 环境嘈杂时:头戴式耳机麦克风(降噪效果好)
- 追求高质量:专业 USB 麦克风(识别准确率高)
麦克风音源
- 下拉框显示系统中所有可用的麦克风设备
- 桌面客户端会自动检测并上报设备列表到 Web 端
- 选择要使用的麦克风设备
- 首选电脑本身的内置麦克风(如 MacBook 内置麦克风)
- 也支持外接麦克风(如 USB 麦克风、头戴式耳机麦克风)
- 设备格式示例:内置麦克风、USB 麦克风
麦克风设备名称
- 自动显示选中麦克风的完整名称
- 只读字段,不可手动编辑
- 用于确认选择的设备是否正确
使用场景
麦克风是模拟面试和面试训练的核心输入设备,主要用于:
用户语音输入
- 用户在模拟面试中回答问题时,麦克风捕获您的语音
- 语音通过 FunASR 服务实时转换为文字
- 文字内容发送给 LLM 生成智能答案和建议
- 整个过程实现了"说话 → 识别 → AI 回答"的闭环
面试训练场景
- 练习口语表达时,麦克风记录您的回答
- 系统识别您的语音内容,分析回答质量
- 根据识别结果提供针对性反馈
设备选择建议
- 优先使用电脑内置麦克风,简单方便,无需额外设备
- 环境嘈杂时可选择头戴式耳机麦克风,减少背景噪音
- 追求更高识别准确率可使用专业 USB 麦克风
2.2 扬声器设置
在"设备配置"标签页,配置扬声器音频输出设备。
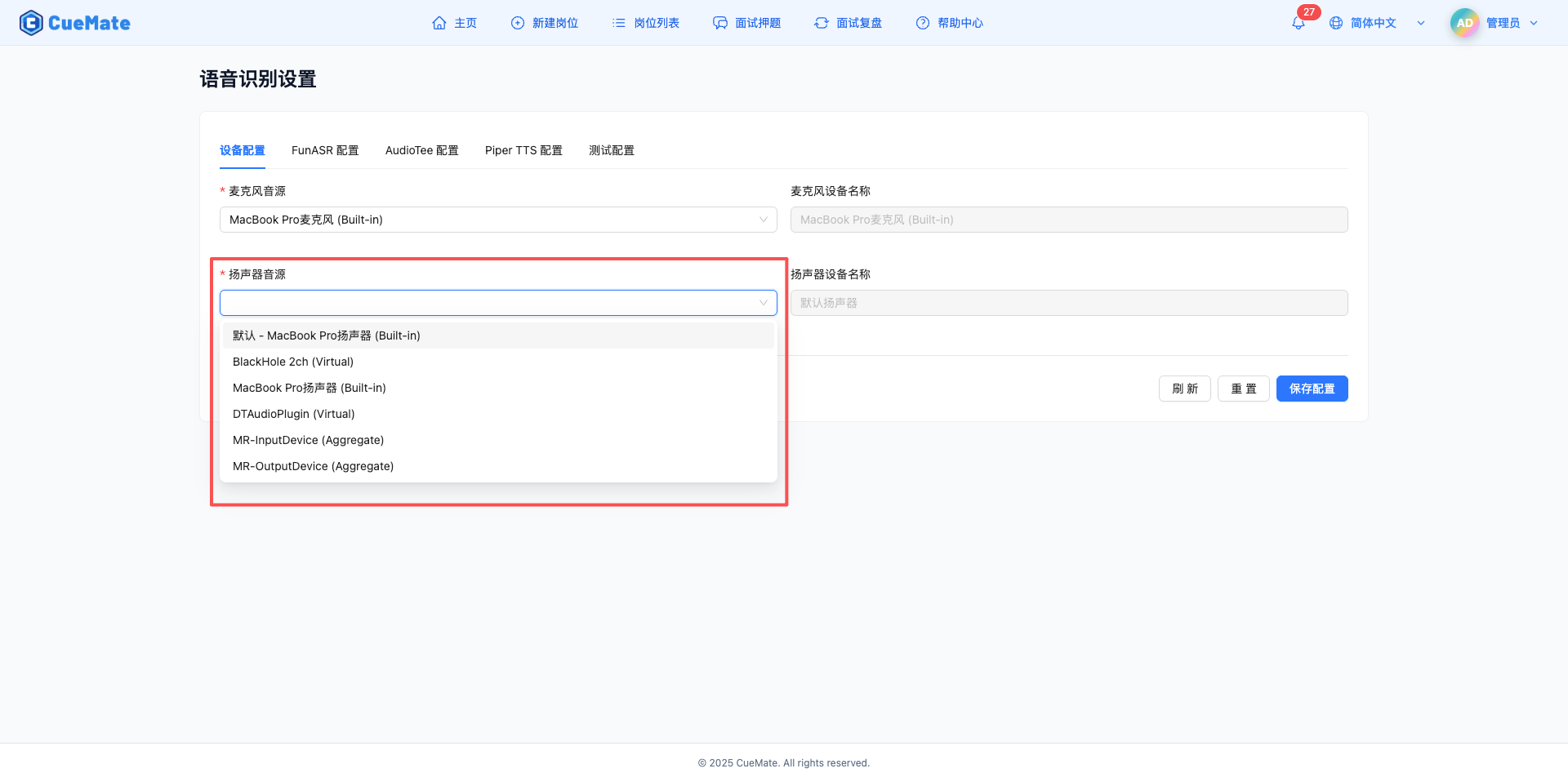
扬声器音源
- 下拉框显示系统中所有可用的扬声器设备
- 桌面客户端会自动检测并上报设备列表
- 选择要使用的扬声器设备
- 首选电脑本身的内置扬声器(如 MacBook 内置扬声器)
- 也支持外接音频设备(如 USB 音箱、蓝牙耳机、有线耳机)
- 设备格式示例:内置扬声器、USB 音箱、蓝牙耳机
扬声器设备名称
- 自动显示选中扬声器的完整名称
- 只读字段,不可手动编辑
- 用于确认选择的设备是否正确
使用场景
扬声器在模拟面试和面试训练中承担两个关键作用:
播放 AI 生成的答案语音(Piper TTS)
- 当您说话后,AI 会生成智能答案和建议
- Piper TTS 将文字答案转换为自然流畅的语音
- 通过扬声器播放出来,您可以听到 AI 的回答
- 这样无需盯着屏幕看文字,解放双眼,专注思考
捕获面试官的语音(AudioTee 系统音频捕获)
- 这是扬声器最重要的功能
- 当您使用腾讯会议、Zoom 等软件进行模拟面试训练时
- 模拟面试官的声音会从扬声器播放出来
- AudioTee 捕获扬声器播放的系统音频流
- 捕获的音频通过 FunASR 识别成文字
- AI 分析问题,实时生成答案提示
- 实现了"语音播放 → 扬声器输出 → AudioTee 捕获 → FunASR 识别 → AI 生成答案"的完整流程
技术原理说明
为什么扬声器对捕获面试官语音至关重要:
- 面试软件(腾讯会议、Zoom)的音频输出到扬声器
- AudioTee 作为系统级音频捕获工具,拦截发送到扬声器的音频流
- 即使您戴着耳机,AudioTee 也能捕获到音频数据
- 这是一种非侵入式的音频捕获方案,不影响面试软件正常运行
设备选择建议
- 优先使用电脑内置扬声器,系统音频捕获最稳定
- 使用耳机时确保 AudioTee 能正确识别音频设备
- 避免使用蓝牙设备,可能存在延迟和兼容性问题
- 面试训练场景建议使用有线耳机,保证音质和捕获稳定性
2.3 刷新设备列表
如果连接了新的音频设备,点击底部"刷新"按钮重新检测设备列表。
刷新操作
- 点击"刷新"按钮
- 向桌面客户端发送设备请求
- 浏览器重新枚举本地音频设备
- 设备列表自动更新
使用场景
- 插入新的 USB 麦克风或音箱后刷新列表
- 连接蓝牙耳机后刷新设备
- 设备列表显示异常时重新加载
3. FunASR 配置
3.1 基本配置
在"FunASR 配置"标签页,配置 FunASR 语音识别服务的连接参数。
注:默认所有配置都有默认值,不需要修改。
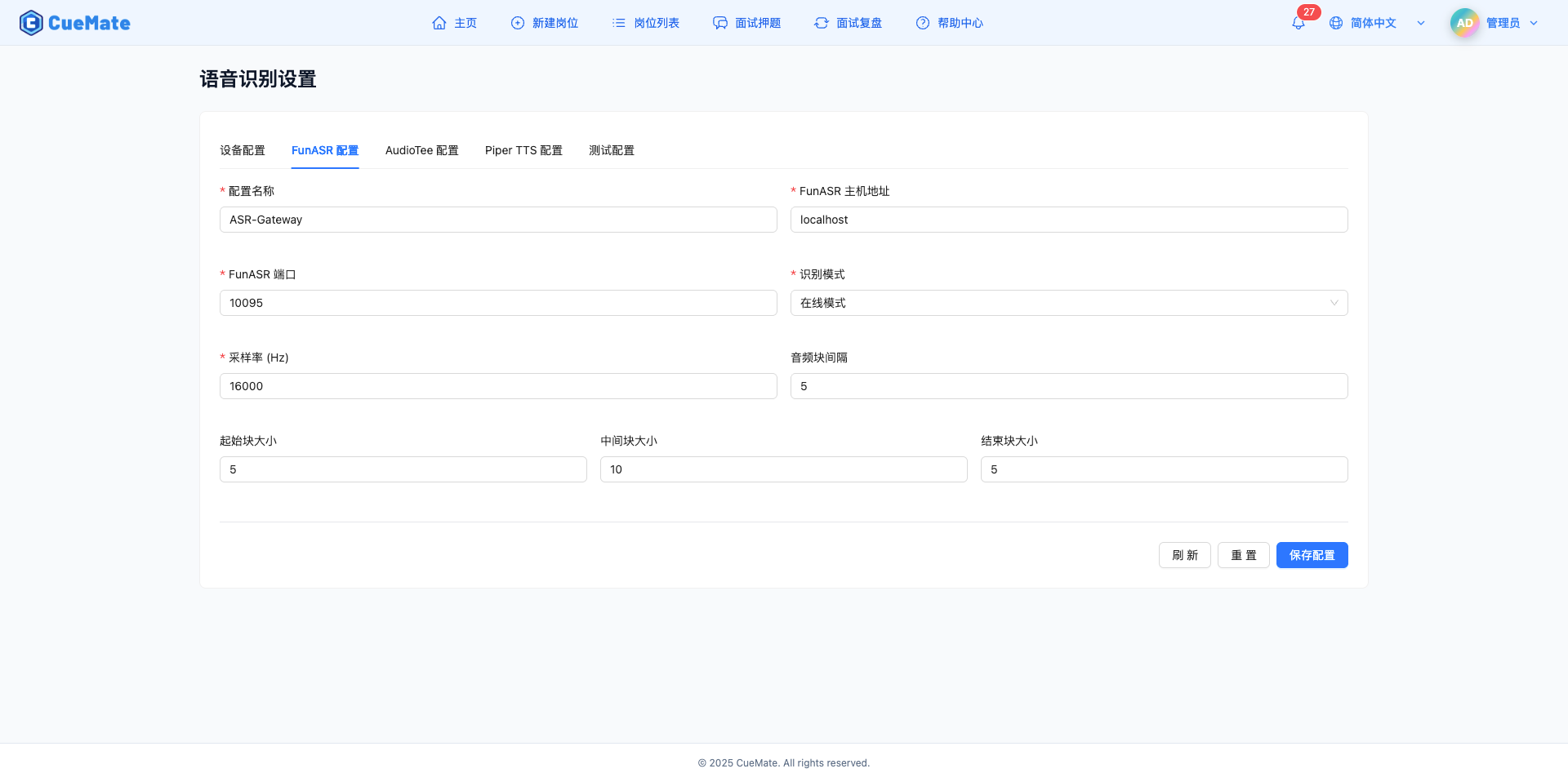
配置名称
- 为当前配置命名
- 默认值:ASR-Gateway
- 便于识别和管理多个配置
FunASR 主机地址
- FunASR 服务的主机地址
- 默认值:localhost
- 本地部署填写 localhost 或 127.0.0.1
- 远程部署填写服务器 IP 地址
FunASR 端口
- FunASR 服务的 WebSocket 端口
- 默认值:10095
- 取值范围:1-65535
- 确保端口未被其他服务占用
识别模式
- 在线模式(online):实时流式识别,低延迟,边说边转文本
- 离线模式(offline):录音完成后统一识别,准确率高
- 两遍模式(2pass):先在线实时显示,再离线优化结果
使用场景
- 面试场景推荐使用"在线模式",实时看到答案
- 录音转文字推荐使用"离线模式",准确率更高
- 重要会议推荐使用"两遍模式",兼顾实时性和准确性
3.2 音频参数
采样率(Hz)
- 音频采样率,影响识别质量
- 默认值:16000 Hz
- 取值范围:8000-48000 Hz
- 推荐使用 16000 Hz,平衡质量和性能
音频块间隔
- 音频块发送间隔
- 默认值:5
- 取值范围:1-20
- 值越小延迟越低,但网络压力越大
3.3 音频块大小配置
FunASR 使用分块识别策略,将音频流分为起始、中间、结束三个阶段。
起始块大小(chunk_size_start)
- 语音开始阶段的音频块大小
- 默认值:5
- 取值范围:1-20
- 较小的值可以快速触发识别
中间块大小(chunk_size_middle)
- 语音持续阶段的音频块大小
- 默认值:10
- 取值范围:1-20
- 较大的值提高稳定识别
结束块大小(chunk_size_end)
- 语音结束阶段的音频块大小
- 默认值:5
- 取值范围:1-20
- 较小的值可以快速结束识别
调优建议
- 起始块和结束块较小,快速响应
- 中间块较大,稳定识别长句子
- 总体值越小越实时,但识别可能不稳定
- 总体值越大越稳定,但延迟越高
4. AudioTee 配置
4.1 AudioTee 简介
AudioTee 是系统音频捕获工具,用于捕获面试软件(如腾讯会议、Zoom)的音频输出,实现面试官语音识别。
4.2 基本配置
在"AudioTee 配置"标签页,配置系统音频捕获参数。
注:默认所有配置都有默认值,不需要修改。
AudioTee 采样率
- 系统音频捕获的采样率
- 默认值:16000 Hz(推荐)
- 可选值:8000/16000/22050/24000/32000/44100/48000 Hz
- 推荐使用 16000 Hz,与 FunASR 采样率保持一致
音频块时长(秒)
- 每个音频块的时长
- 默认值:0.2 秒
- 取值范围:0.1-2.0 秒
- 值越小延迟越低,但处理频率越高
4.3 进程过滤配置
AudioTee 支持过滤特定进程的音频,实现精确捕获。
包含进程列表(JSON)
- 只捕获指定进程的音频
- 格式:JSON 字符串数组
- 示例:
["1234", "5678"] - 留空表示捕获所有进程音频
排除进程列表(JSON)
- 排除指定进程的音频
- 格式:JSON 字符串数组
- 示例:
["9999"] - 用于过滤不需要的音频源
进程过滤逻辑
- 如果设置了"包含进程列表",只捕获列表中的进程音频
- 如果设置了"排除进程列表",不捕获列表中的进程音频
- 两个列表可以组合使用
使用场景
- 只捕获腾讯会议的音频:包含进程列表填写腾讯会议的进程 ID
- 排除音乐播放器的音频:排除进程列表填写音乐播放器的进程 ID
- 默认捕获所有系统音频:两个列表都留空
[]
获取进程 ID(macOS)
# 查找腾讯会议进程 ID
ps aux | grep "TencentMeeting"
# 查找 Zoom 进程 ID
ps aux | grep "zoom.us"4.4 静音控制
静音被捕获的进程
- 开关控制是否静音被捕获的进程音频
- 开启后,被捕获的音频不会从扬声器播放
- 关闭后,正常播放音频的同时进行捕获
- 默认值:关闭
使用场景
- 面试时想要安静环境,开启静音
- 需要听到面试官声音,关闭静音
- 录制时不想打扰他人,开启静音
5. Piper TTS 配置
5.1 Piper TTS 简介
Piper TTS 是本地神经网络语音合成系统,将文本转换为自然流畅的语音。桌面客户端使用 Piper TTS 朗读 AI 生成的答案。
技术实现
- Piper TTS 已通过 PyInstaller 打包为独立可执行文件
- 内置 Python 运行时和所有必要依赖
- 无需用户单独安装 Python 或配置环境
- 随桌面客户端一起分发,开箱即用
- 支持中文(花颜女声)和英文(Amy 女声)两种语音模型
5.2 语音配置
在"Piper TTS 配置"标签页,配置语音合成参数。
注:默认所有配置都有默认值,不需要修改。
默认语言
- 选择 TTS 语音合成的默认语言
- 中文(zh-CN):使用花颜女声中文模型
- 英文(en-US):使用 Amy 女声英文模型
- 会根据用户设置的界面语言自动选择对应语音
语音速度
- 控制语音朗读的速度
- 默认值:1.0(正常速度)
- 取值范围:0.5-2.0
- 0.5 表示慢速,2.0 表示快速
- 建议使用 0.8-1.2 之间的值
语音速度选择建议
- 0.5-0.7:学习模式,慢速理解
- 0.8-1.0:正常模式,舒适自然
- 1.1-1.5:快速模式,节省时间
- 1.6-2.0:极速模式,快速浏览
使用场景
- 中文面试选择"中文(zh-CN)"
- 英文面试选择"英文(en-US)"
- 答案较长时降低语音速度,便于理解
- 时间紧迫时提高语音速度,快速浏览
配置建议
- 语音语言应与系统设置的界面语言保持一致
- 语音速度建议在 0.9-1.1 之间,过快或过慢都不自然
NOTE
关于 Python 依赖:桌面客户端已内置 Piper TTS 独立可执行文件(使用 PyInstaller 打包),无需单独安装 Python 和 piper-tts 依赖。所有必要组件已随应用一起分发。
6. 测试配置
6.1 测试参数
在"测试配置"标签页,配置音频设备和语音识别的测试参数。
注:默认所有配置都有默认值,不需要修改。
测试持续时间(秒)
- 设备测试的最大持续时间
- 默认值:60 秒
- 取值范围:10-300 秒
- 超过时间后自动停止测试
识别超时时间(秒)
- 语音识别的超时时间
- 默认值:15 秒
- 取值范围:5-60 秒
- 超过时间未识别到语音,认为识别失败
6.2 识别长度限制
最小识别长度
- 识别结果的最小字符数
- 默认值:5
- 取值范围:1-50
- 少于此长度的识别结果可能被过滤
最大识别长度
- 识别结果的最大字符数
- 默认值:30
- 取值范围:10-200
- 超过此长度的识别结果可能被截断
使用场景
- 过滤短语音(如"嗯"、"啊")设置最小识别长度为 5
- 限制长句子识别设置最大识别长度
- 测试时可以调整这些参数观察效果
7. 保存和重置
7.1 保存配置
点击底部"保存配置"按钮,将所有配置保存到服务器。
保存流程
- 点击"保存配置"按钮
- 验证所有必填字段是否填写正确
- 提交配置到服务器
- 服务器保存配置并返回确认
- 显示"配置已保存"成功提示
- 桌面客户端自动同步新配置
保存内容
- 设备配置(麦克风、扬声器)
- FunASR 配置(主机、端口、模式等)
- AudioTee 配置(采样率、进程过滤等)
- Piper TTS 配置(语言、语音速度等)
- 测试配置(测试时间、识别长度等)
重要提示
- 修改配置后必须点击"保存配置"才会生效
- 桌面客户端会自动同步最新配置
- 建议在非面试时间修改配置并测试
7.2 重置配置
点击底部"重置"按钮,恢复所有配置为默认值。
重置操作
- 点击"重置"按钮
- 所有字段恢复为默认值
- 不会自动保存,需要手动点击"保存配置"
默认配置值
配置名称: ASR-Gateway
FunASR 主机: localhost
FunASR 端口: 10095
识别模式: 在线模式
采样率: 16000 Hz
音频块间隔: 5
起始/中间/结束块大小: 5/10/5
AudioTee 采样率: 16000 Hz
音频块时长: 0.2 秒
进程过滤: 空 []
静音进程: 关闭
Piper 默认语言: 中文 (zh-CN)
语音速度: 1.0
测试持续时间: 60 秒
识别超时: 15 秒
最小识别长度: 5
最大识别长度: 30使用场景
- 配置修改出错,恢复默认值
- 不确定如何配置,使用默认配置
- 测试完成后恢复推荐配置
7.3 刷新设备
点击底部"刷新"按钮,重新检测音频设备列表。
刷新功能
- 向桌面客户端请求最新设备列表
- 浏览器重新枚举本地音频设备
- 麦克风和扬声器下拉框自动更新
使用场景
- 插入新的 USB 音频设备后刷新
- 连接蓝牙耳机后刷新
- 设备列表显示异常时刷新
8. 常见问题
8.1 设备列表为空
问题:麦克风或扬声器下拉框没有设备选项。
解决方案
- 点击"刷新"按钮重新检测设备
- 检查桌面客户端是否正常运行
- 确认浏览器已授予麦克风权限
- 检查系统是否连接了音频设备
- 重启浏览器和桌面客户端
8.2 保存配置失败
问题:点击"保存配置"按钮,提示保存失败。
解决方案
- 检查所有必填字段是否填写
- 检查端口号是否在 1-65535 范围内
- 检查 JSON 格式的进程列表是否正确
- 查看浏览器控制台是否有错误信息
- 检查网络连接是否正常
8.3 FunASR 连接失败
问题:配置保存后,桌面客户端无法连接 FunASR 服务。
解决方案
- 检查 FunASR 主机地址和端口是否正确
- 确认 FunASR Docker 容器是否正常运行bash
docker ps | grep FunASR - 测试 FunASR 服务是否可访问bash
curl ws://localhost:10095 - 检查防火墙是否阻止了连接
- 查看 FunASR 容器日志bash
docker logs FunASR
8.4 AudioTee 无法捕获系统音频
问题:设置了 AudioTee 配置,但无法捕获面试软件的音频。
解决方案(macOS)
- 系统偏好设置 > 安全性与隐私 > 屏幕录制
- 允许 CueMate 或桌面客户端访问屏幕录制权限
- 检查进程过滤配置是否正确
- 确认面试软件正在播放音频
- 尝试关闭"静音被捕获的进程"开关
- 查看桌面客户端日志是否有错误信息
8.5 Piper TTS 无声音
问题:配置了 Piper TTS,但播放答案时没有声音。
解决方案
- 检查扬声器设备是否选择正确
- 确认系统音量未静音
- 检查 Piper TTS 语言设置是否与内容匹配(中文内容需选择中文语音)
- 查看桌面客户端日志是否有 TTS 错误
- macOS:
~/Library/Application Support/cuemate-desktop-client/data/logs/
- macOS:
- 确认 Piper TTS 二进制文件是否正常
- 二进制文件位置:
resources/piper-bin/piper - 如果文件丢失或损坏,请重新安装桌面客户端
- 二进制文件位置:
NOTE
Piper TTS 已作为独立可执行文件内置在桌面客户端中,无需单独安装 Python 或 piper-tts 包。如果遇到问题,通常是配置或系统权限问题,而非依赖缺失。
8.6 语音识别准确率低
问题:语音识别经常识别错误或识别不出来。
解决方案
- 检查麦克风设备是否正常工作
- 选择安静的环境,减少背景噪音
- 调整麦克风位置,靠近说话者
- 清晰发音,语速适中,避免快速连读
- 尝试提高 FunASR 采样率到 48000 Hz
- 切换识别模式为"两遍模式"提高准确率
8.7 识别延迟高
问题:说话后很久才显示识别结果。
解决方案
- 降低 FunASR 音频块间隔(如改为 3)
- 减小 FunASR 块大小(如起始/中间/结束改为 3/6/3)
- 降低 AudioTee 音频块时长(如改为 0.1 秒)
- 使用有线麦克风,避免蓝牙延迟
- 检查系统资源占用,关闭不必要的程序
- 确认网络连接正常,延迟较低