v0.1.0 版本说明
发布日期: 2025-12-07 版本类型: 首发版本 稳定性: 稳定
版本概述
CueMate v0.1.0 是首个正式发布版本,标志着项目从测试阶段进入生产就绪状态。本版本包含完整的核心功能,支持实时语音识别、多模型 AI 回答、知识库增强等功能。
新增功能
1. feat(install): 提供 macOS DMG 一键安装包,通过简单便捷的安装面板快速部署应用
CueMate 提供标准的 macOS DMG 安装包,支持 Apple Silicon(M1/M2/M3)和 Intel 双架构。内置安装向导会自动引导完成环境检测、Docker 配置、服务部署等全部流程,用户无需任何技术背景即可完成安装。
下载并打开安装包
根据 Mac 芯片类型选择对应的安装包:
- Apple Silicon (M1/M2/M3):
CueMate-v0.1.0-macos-arm64-offline.dmg - Intel 芯片:
CueMate-v0.1.0-macos-x64-offline.dmg
双击下载的 DMG 文件,macOS 会自动挂载磁盘镜像,弹出安装窗口。
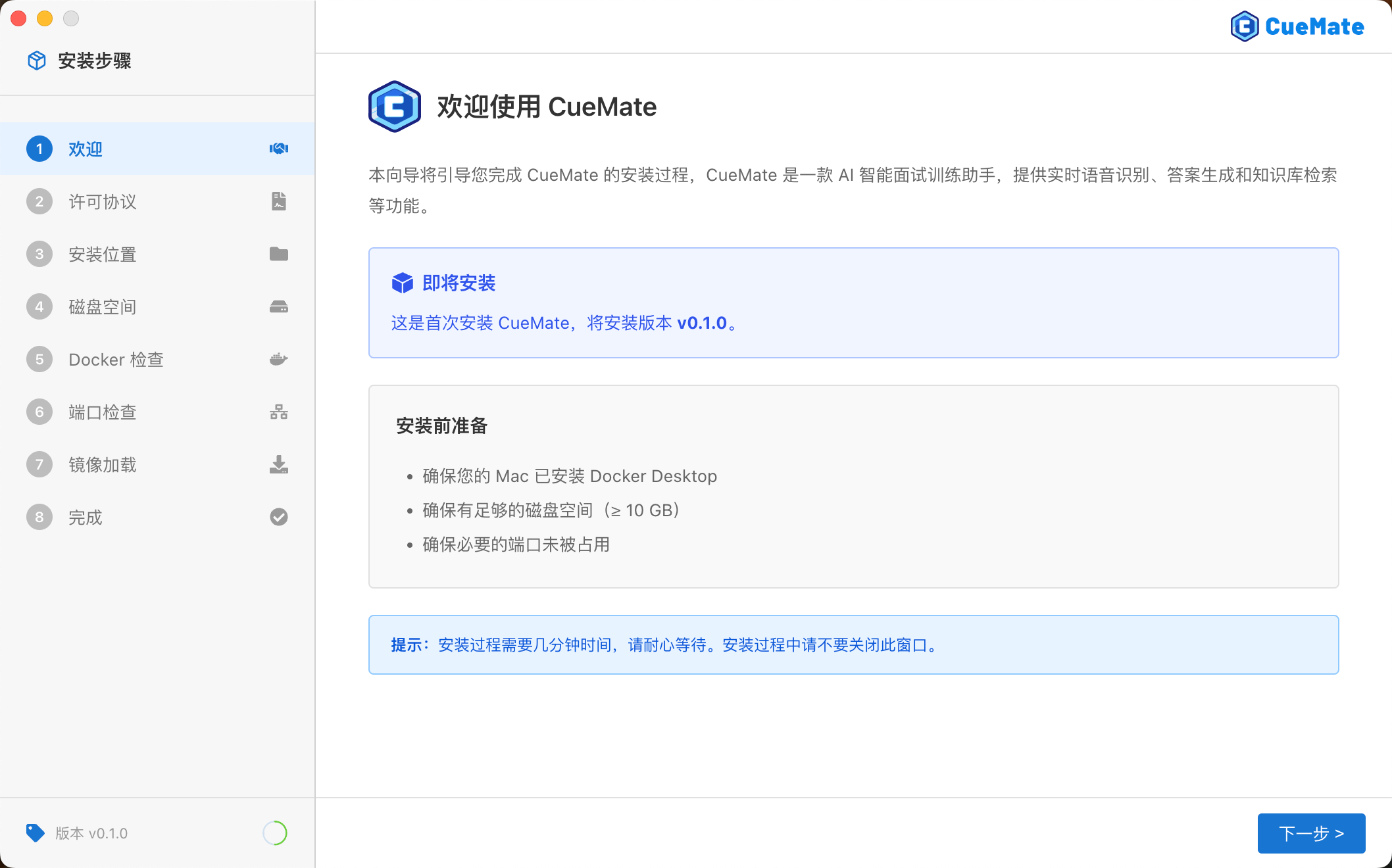
安装向导引导
安装向导包含 8 个步骤,会自动引导完成整个安装过程:
- 欢迎:介绍 CueMate 功能
- 许可协议:阅读并同意软件许可协议
- 安装位置:选择安装目录(默认
/Applications) - 磁盘检测:确认至少 10GB 可用空间
- Docker 检查:检测并自动配置 Docker Desktop
- 端口检查:检测 80、3001、3002、3003、8000、10095 端口占用
- 镜像加载:加载后端服务镜像并启动服务
- 完成:自动启动 CueMate 桌面应用
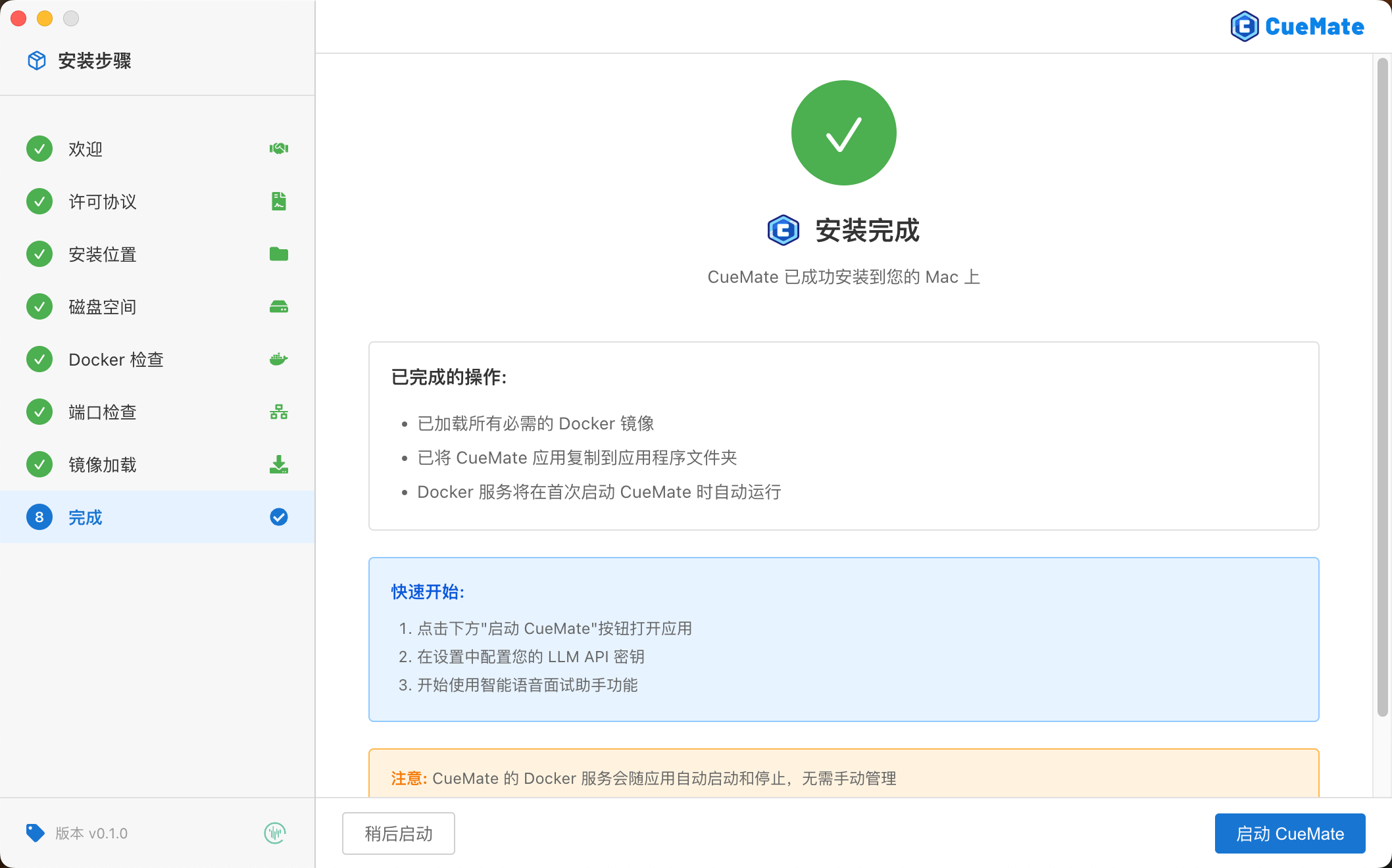
首次使用授权
安装完成后首次使用时,系统会弹出权限请求:
- 麦克风权限:用于识别您的语音输入
- 录屏与系统录音权限:用于捕获系统音频(识别面试官语音),仅捕获音频不录制画面
点击「允许」即可完成授权。授权后使用内置账号登录(用户名:admin,密码:cuemate)即可开始使用。
总结
macOS DMG 安装包集成了完整的安装向导,自动处理环境检测、依赖安装、服务部署等复杂流程。用户从下载到开始使用,整个过程约 5 分钟。双架构支持确保在所有主流 Mac 设备上的兼容性,支持 macOS 13.0 (Ventura) 及以上版本。
2. feat(desktop): 桌面应用提供便捷的操作界面,一键启停服务、快速开启面试
CueMate 桌面应用采用悬浮控制栏 + 主应用窗口的双层界面设计,既不遮挡其他应用,又能快速访问所有功能。
悬浮控制栏
启动 CueMate 后,屏幕顶部会显示悬浮控制栏,提供常用功能的快捷入口:
- CueMate 图标:点击打开官方网站
- 语音识别:启动语音识别,打开面试功能窗口
- 提问 AI:快速向 AI 提问
- 交互模式:切换窗口点击穿透模式
- 主应用窗口:打开后台管理界面
- 显示/隐藏:隐藏或显示控制栏及所有窗口
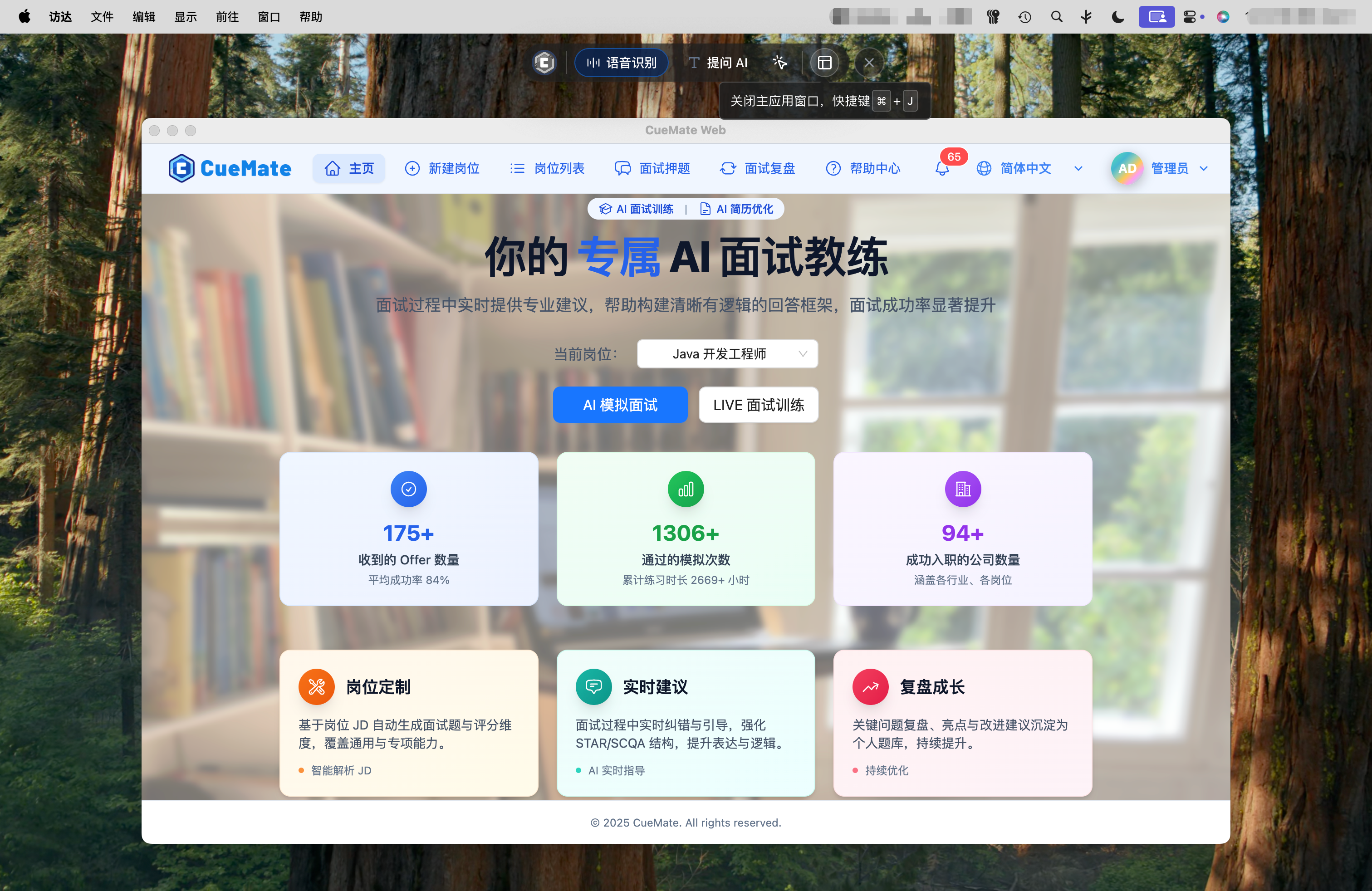
主应用窗口
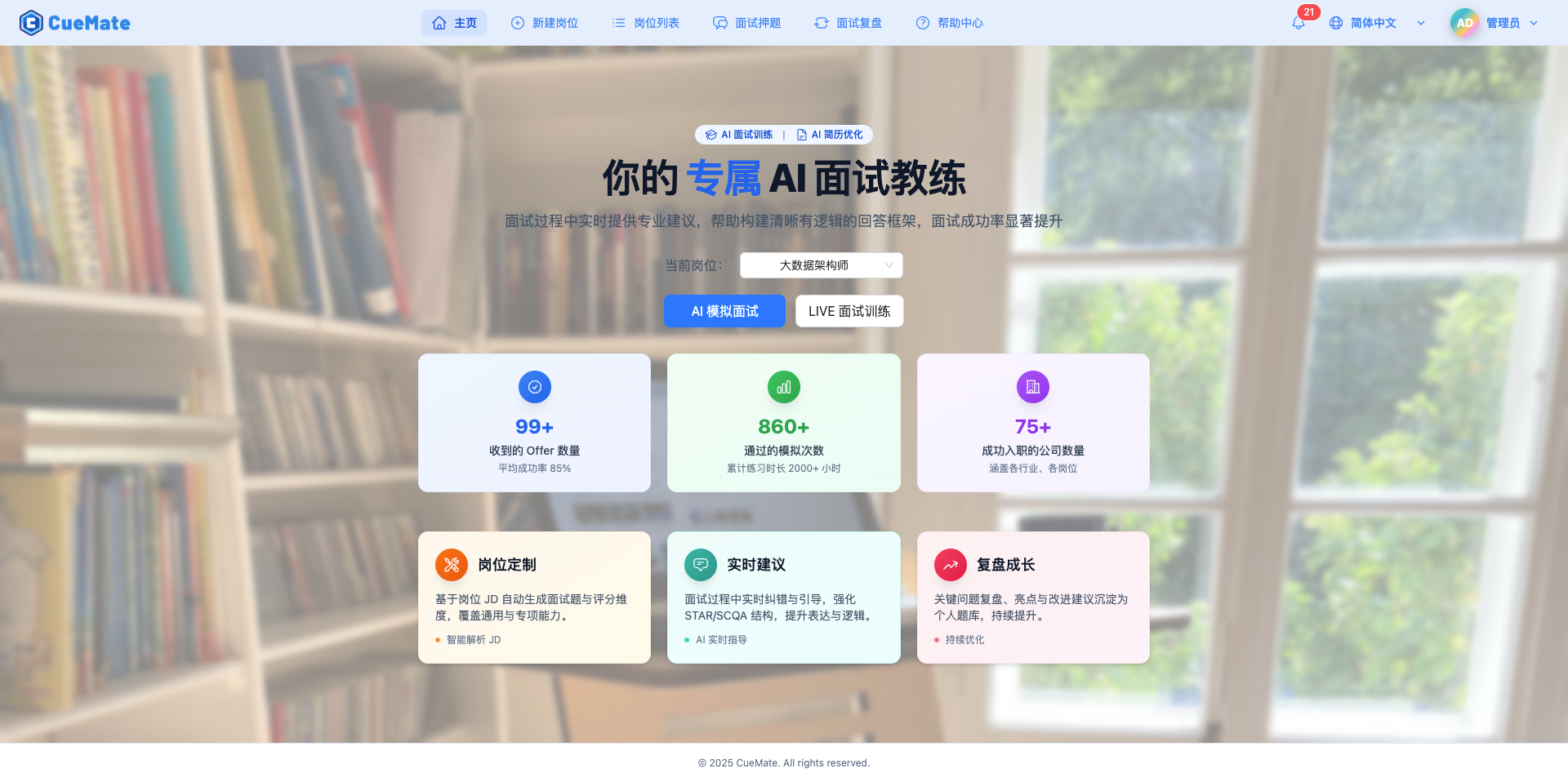
点击控制栏最右侧按钮打开主应用窗口。主页提供面试训练的快速入口,选择已创建的岗位后可启动两种训练模式:
- AI 模拟面试:AI 扮演面试官角色,自动提问,实时评估回答质量
- LIVE 面试训练:真人(朋友)提问,CueMate 实时识别问题并提供答案建议
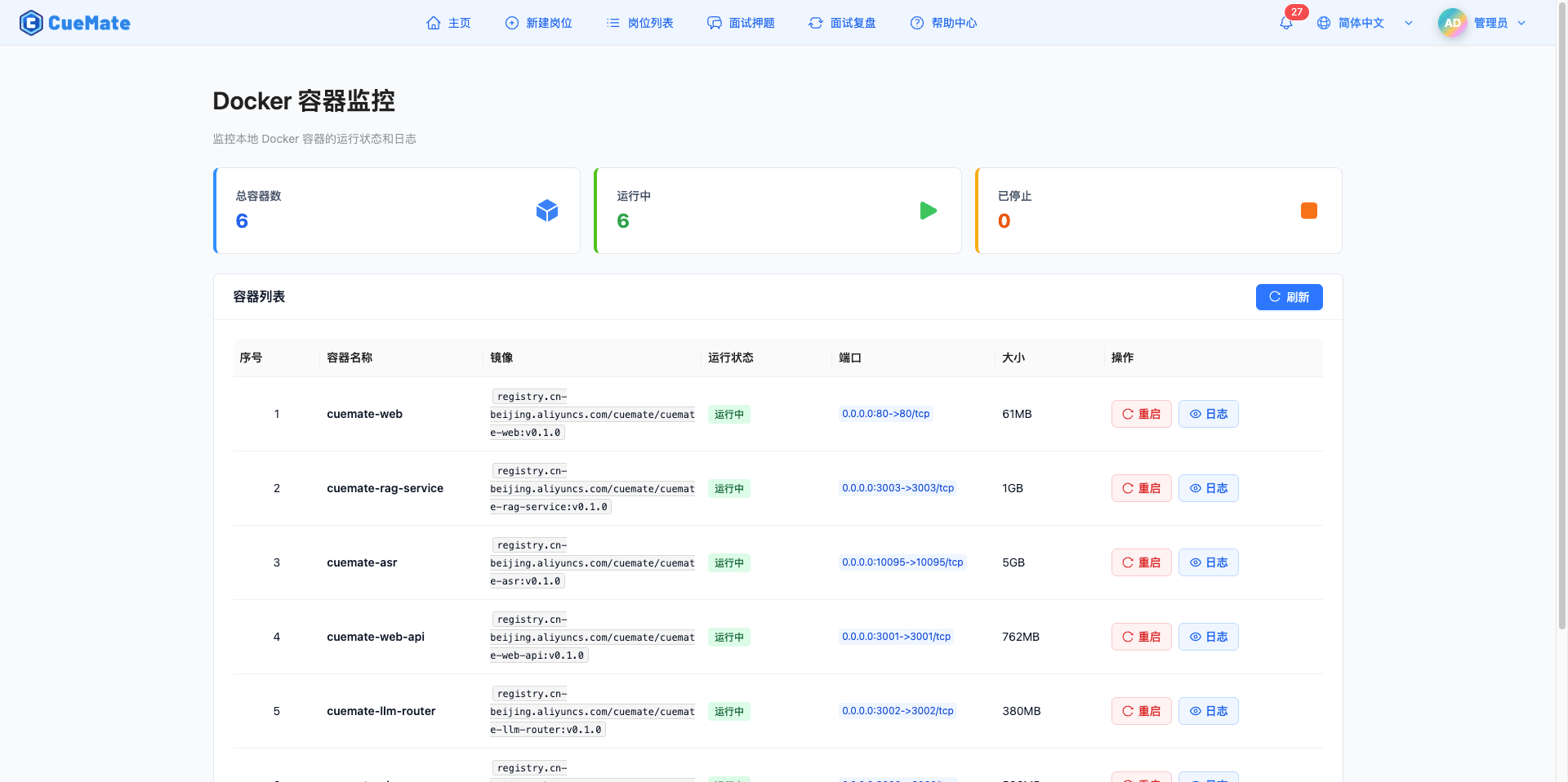
容器监控
通过顶部菜单进入容器监控页面,实时监控所有后端 Docker 容器:
- 统计卡片显示总容器数、运行中、已停止的数量
- 列表展示每个容器的名称、镜像、状态、端口、大小
- 支持重启容器、查看容器日志
- 每 30 秒自动刷新状态
总结
桌面应用将复杂的微服务架构隐藏在简洁的界面之下。悬浮控制栏常驻屏幕顶部,随时可用;主应用窗口提供完整的后台管理功能;容器监控让用户随时了解系统运行状态。
3. feat(system): 支持系统设置与管理,包含用户账号、语音配置、语言偏好、默认模型、Prompt 管理等功能
CueMate 提供完善的系统设置功能,用户可以根据个人需求自定义各项配置。
系统设置
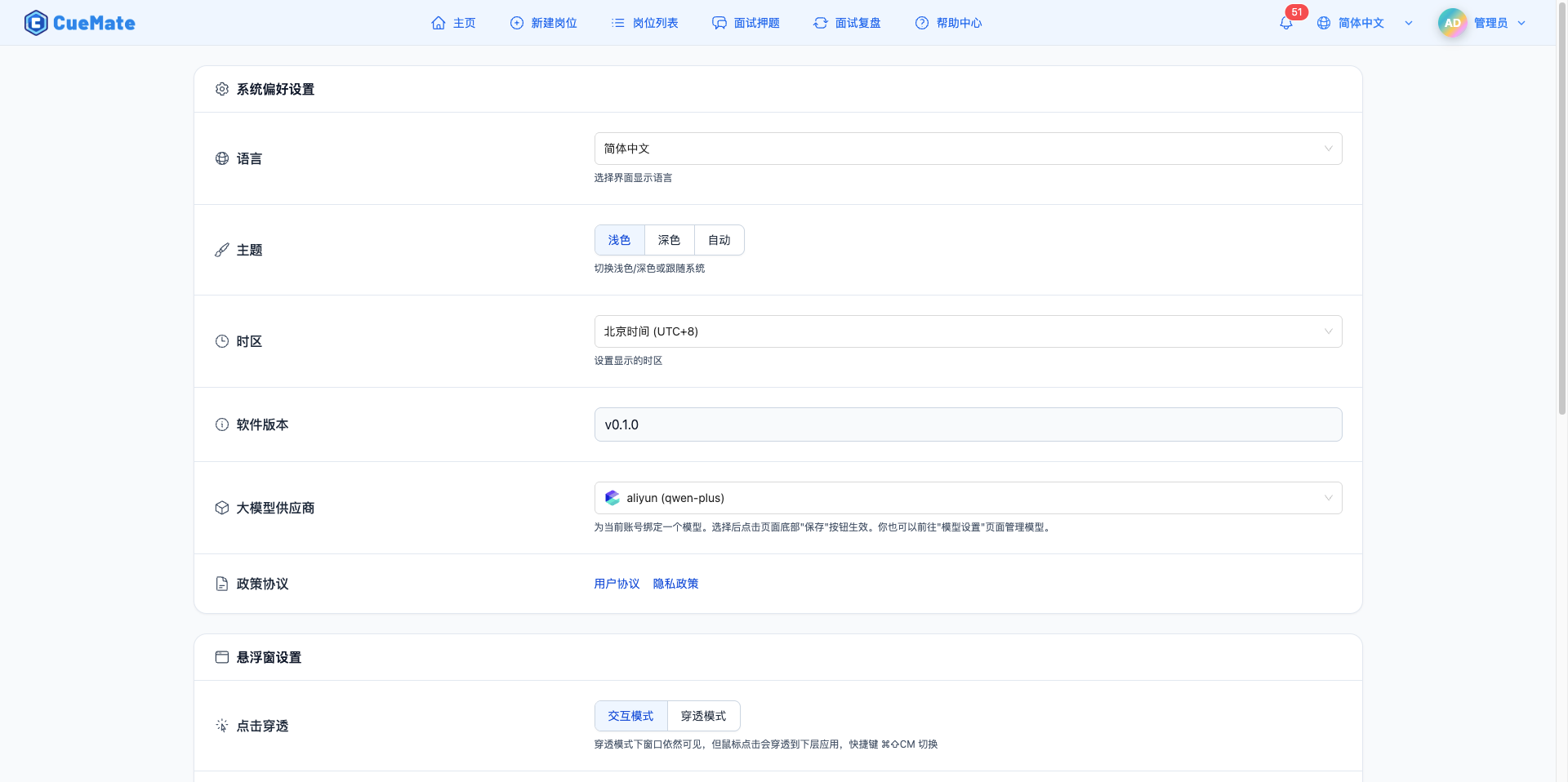
通过顶部菜单进入系统设置页面,分为三个区块:
系统偏好设置:
- 语言选择:简体中文、繁體中文、English
- 主题切换:浅色、深色、自动(跟随系统)
- 时区设置:支持北京、香港、日本、太平洋、伦敦时间
- 大模型服务商:选择默认使用的 LLM 模型
悬浮窗设置:
- 点击穿透模式:切换交互模式和穿透模式(快捷键 ⌘⇧CM)
- 窗口高度:50% / 75% / 100% 屏幕高度
账户信息:用户名、邮箱、修改密码
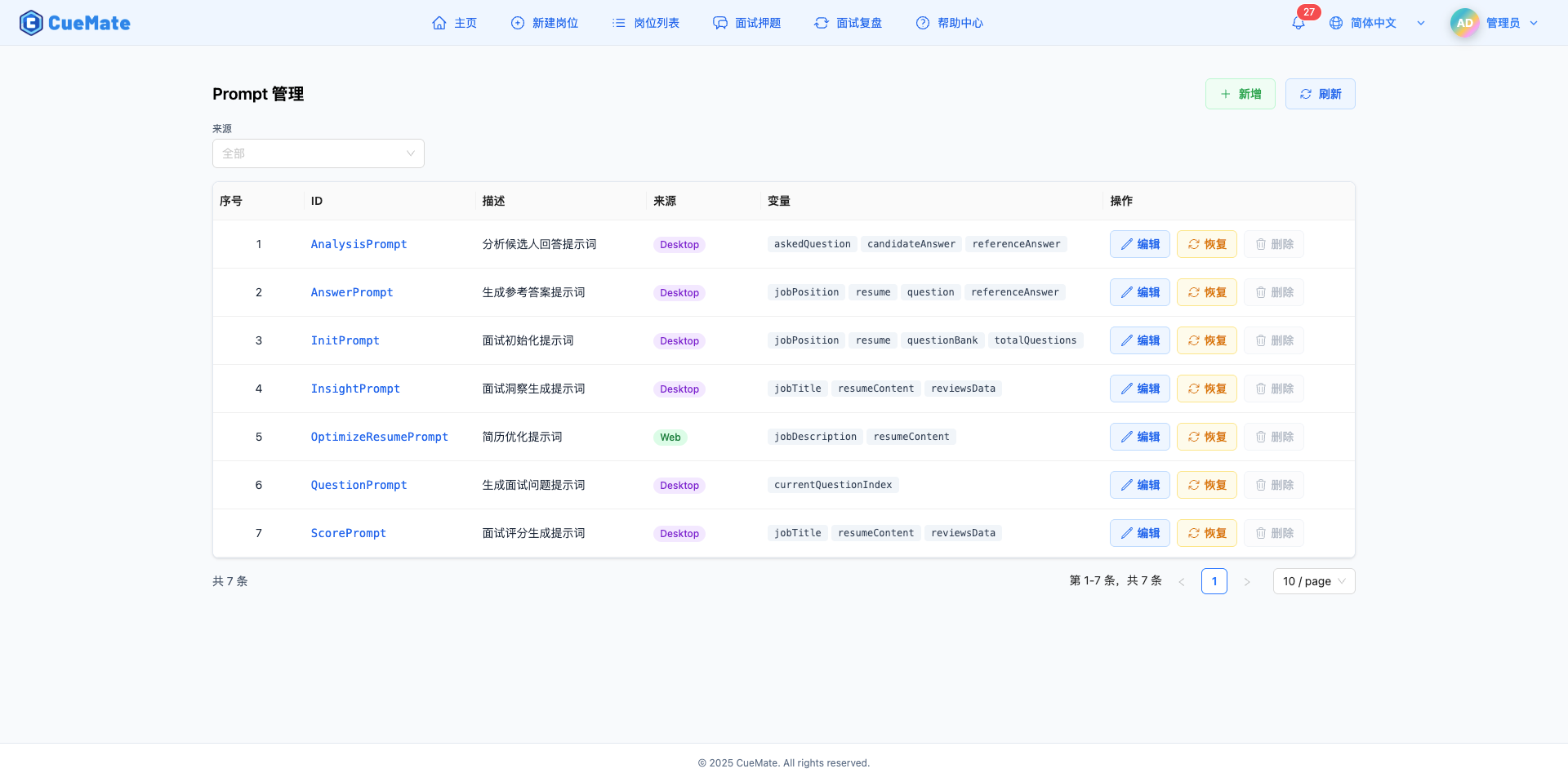
Prompt 管理
Prompt 管理页面用于管理 AI 提示词模板,定义了 AI 的行为和响应方式:
- 查看列表:显示所有 Prompt 的 ID、描述、来源(Desktop/Web)、模板变量
- 编辑 Prompt:修改内容,模板变量自动保护防止误删
- Extra 配置:JSON 格式的额外参数,如
{"totalQuestions": 10},无需修改 Prompt 内容即可调整参数 - 版本恢复:查看历史版本并恢复
模板变量使用 ${variableName} 格式,如 ${jobPosition.title}、${resume.content},运行时自动替换为实际值。
总结
系统设置和 Prompt 管理功能让用户可以灵活自定义 CueMate 的行为。系统偏好和悬浮窗设置优化日常使用体验,Prompt 管理则让高级用户能够调整 AI 的回答风格和评分标准。
4. feat(logs): 完整的日志管理系统,支持按时间和级别查看桌面客户端及各服务的运行日志、操作日志和容器监控信息
CueMate 提供完整的日志管理系统,记录桌面客户端和所有后端服务的运行日志。
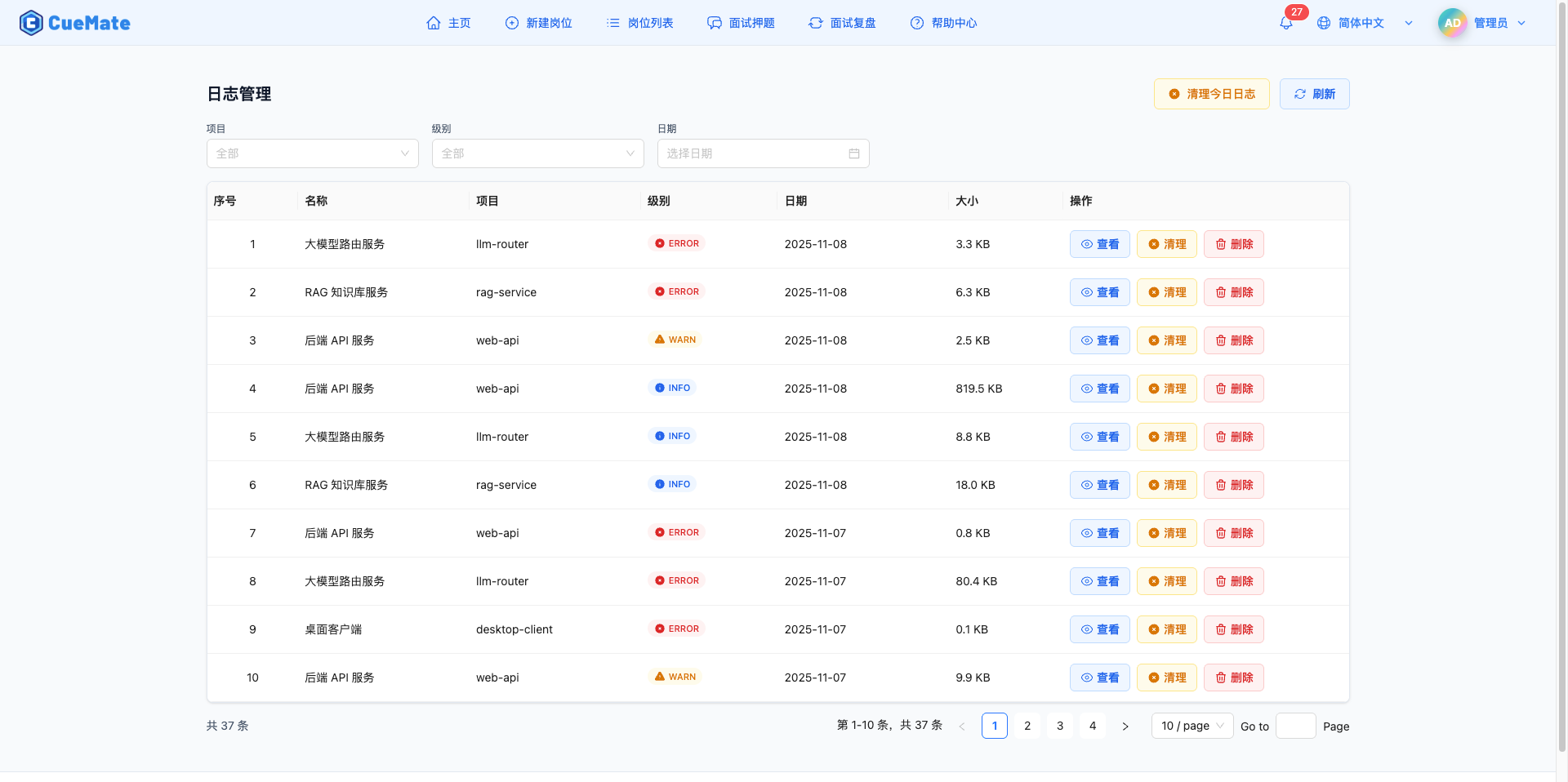
日志筛选与列表
通过顶部菜单进入日志管理页面,支持三维度筛选:
- 按项目(服务):web-api、llm-router、rag-service、desktop-client
- 按级别:DEBUG(灰色)、INFO(蓝色)、WARN(黄色)、ERROR(红色)
- 按日期:选择具体日期查看当天日志
日志列表显示每个日志文件的服务名称、级别、日期、文件大小,支持查看、清理、删除操作。
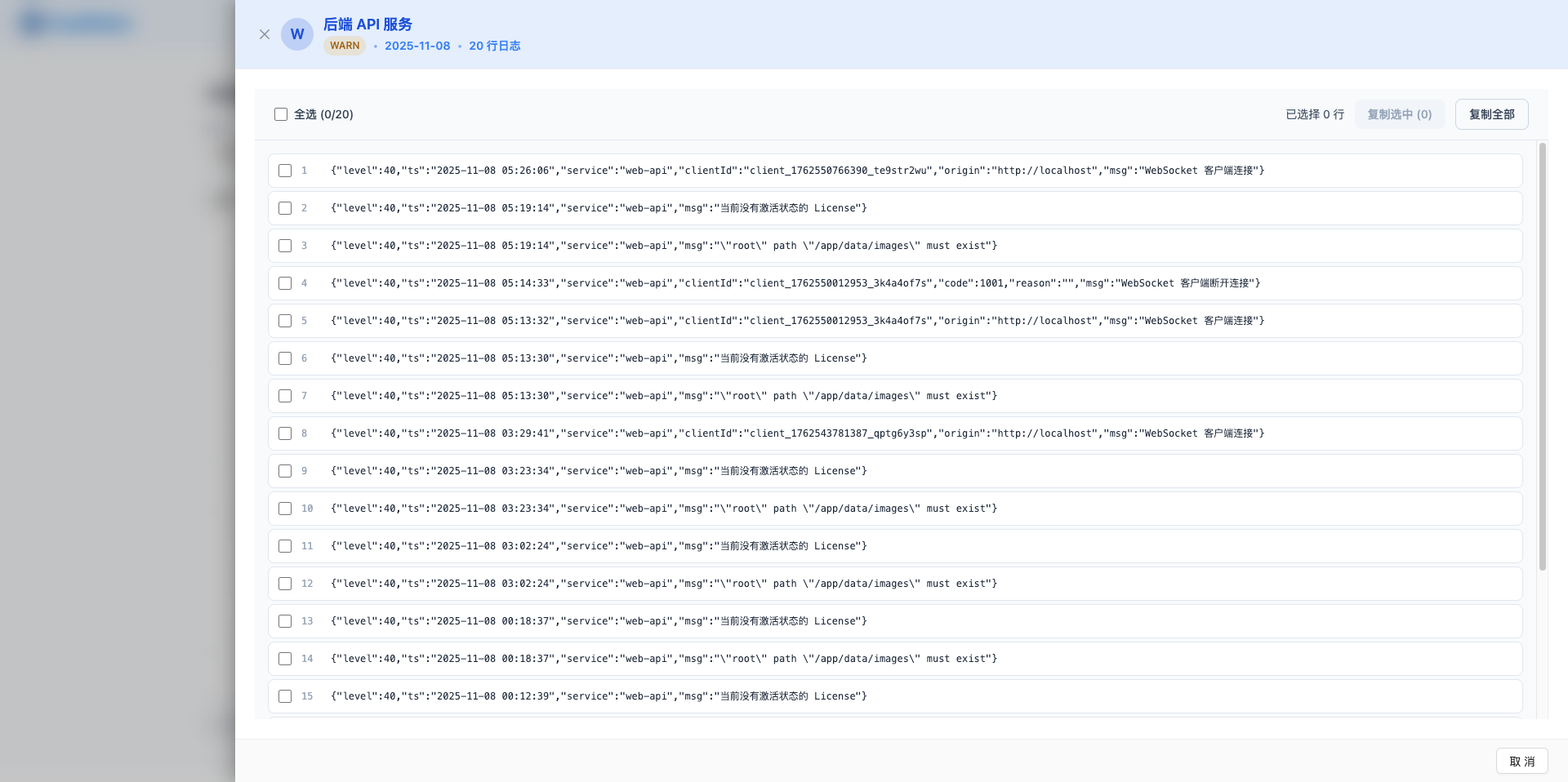
日志查看器
点击「查看」按钮打开侧拉弹框,可查看完整日志内容:
- 日志按行显示,每行可单独选择
- 支持全选、复制选中、复制全部
- JSON 格式日志自动语法高亮
- 显示总行数统计
日志清理
- 清理单个文件:清空内容但保留文件
- 清理今日日志:批量清空所有今日日志
- 删除文件:彻底删除日志文件
所有日志按服务和日期分类存储在 ~/Library/Application Support/cuemate-desktop-client/data/logs/{service}/{date}/ 目录,默认保留 30 天。
总结
日志管理系统为用户提供了完整的系统运行可视化能力。多维度筛选让用户能够快速定位问题日志,查看器支持选择和复制便于问题排查和反馈。
5. feat(llm): LLM 模型配置,支持 24+ 种主流大语言模型服务商的统一管理,用户自定义选择模型
CueMate 支持公有云模型和私有部署模型的统一管理,通过直观的配置界面添加、编辑和测试 LLM 模型。
支持的服务商
- 公有云模型(16 个):OpenAI、Anthropic (Claude)、Google Gemini、DeepSeek、Moonshot (Kimi)、智谱 AI、通义千问(阿里云百炼)、腾讯混元、讯飞星火、火山引擎(豆包)、百度千帆、商汤日日新、百川智能、MiniMax、阶跃星辰、SiliconFlow
- 云平台服务(3 个):Azure OpenAI、Amazon Bedrock、腾讯云
- 私有部署(5 个):Ollama、vLLM、Xinference、本地模型、Regolo
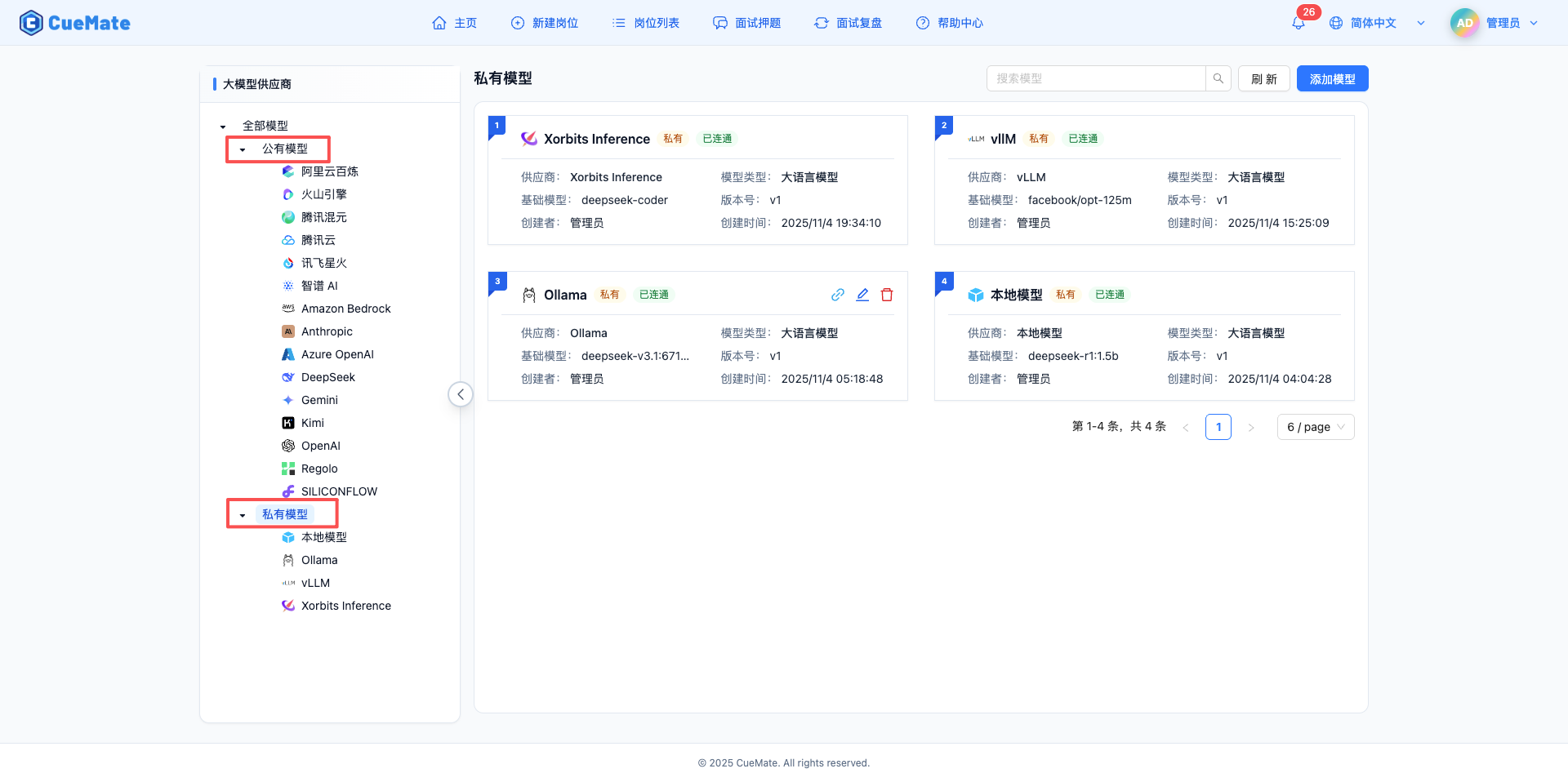
页面布局
左右分栏设计:
- 左侧导航树:全部模型 / 公有模型 / 私有模型,支持按服务商筛选
- 右侧模型列表:卡片式展示,显示模型名称、服务商图标、连通状态(已连通/不可用)
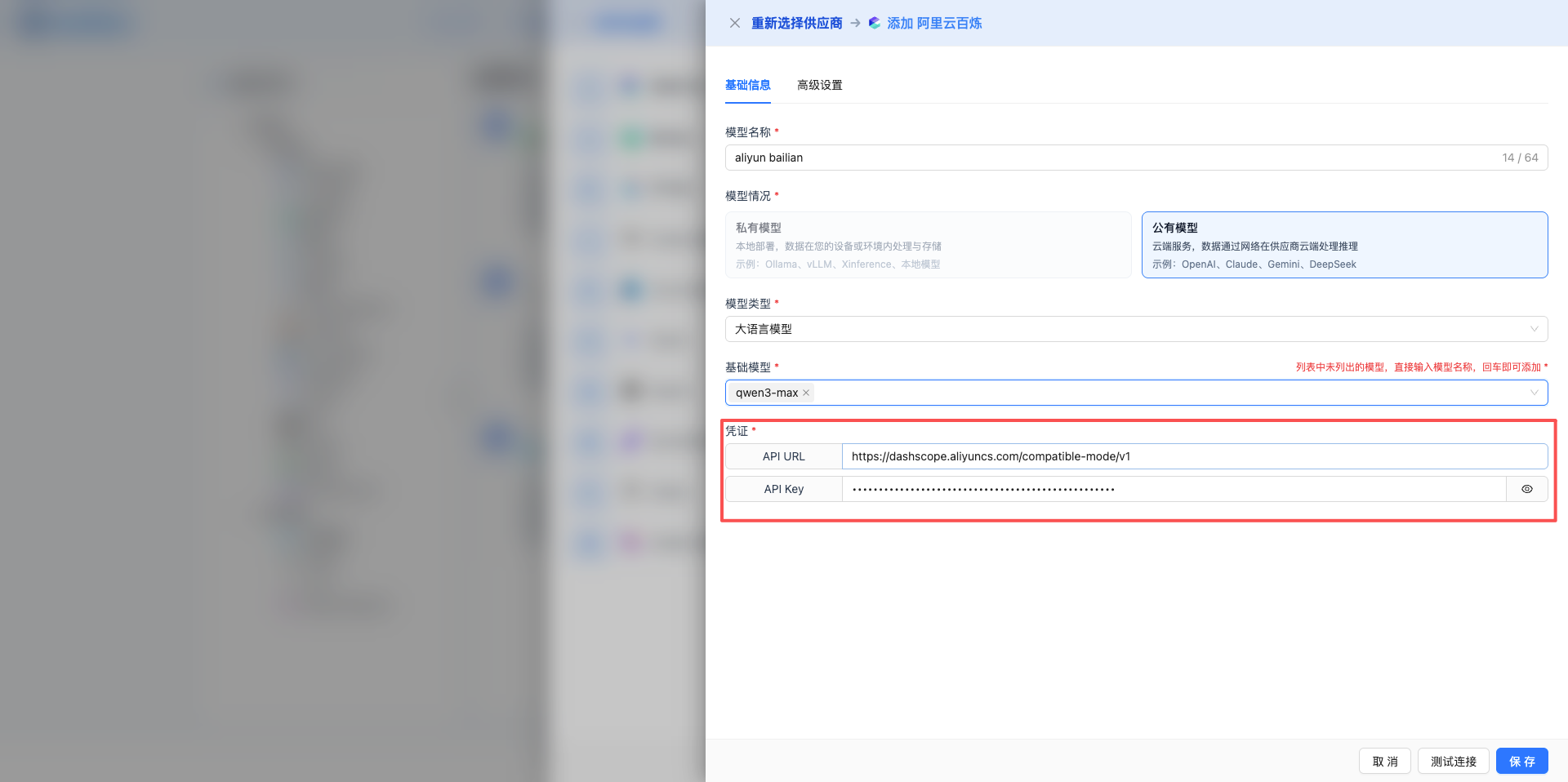
添加和配置模型
- 点击「添加模型」选择服务商
- 填写模型名称、选择基础模型(如 gpt-5、claude-sonnet-4-5)
- 配置凭证:API Key、Base URL
- 高级参数:temperature、max_tokens、top_p 等
- 点击「测试连接」验证配置
每个服务商都提供「查看配置文档」链接,点击跳转到对应的配置说明。
总结
LLM 模型配置功能将复杂的多服务商管理简化为直观的界面操作。支持 24+ 种服务商,涵盖国际主流和国产大模型,以及私有部署方案。统一的配置界面和测试连接功能确保每个模型都能正常工作。
6. feat(job): 岗位管理,创建面试岗位并填写详细 JD 描述,AI 模拟面试时根据岗位智能生成提问与答案
岗位管理是 CueMate 面试准备流程的第一步。用户可以创建目标岗位、填写职位描述(JD)、上传简历,后续的 AI 模拟面试、面试训练都会基于这些信息生成针对性内容。
新建岗位向导
新建岗位采用 3 步向导流程:
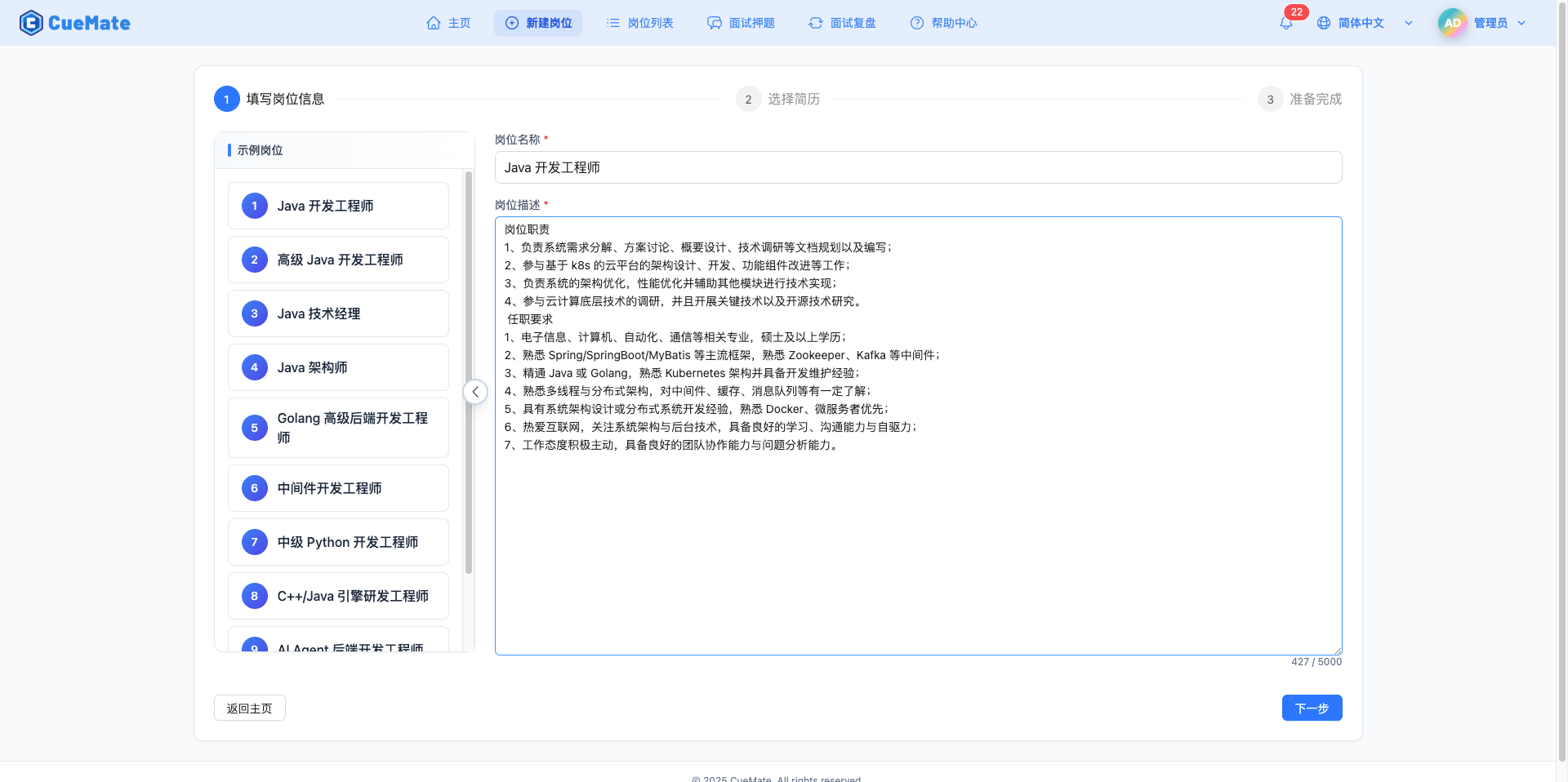
第 1 步 - 填写岗位信息:输入岗位标题和详细的岗位描述(JD)。右侧提供示例岗位参考,点击可快速带出默认值。JD 内容是 AI 生成针对性面试题目的重要依据,建议包含岗位职责、技术栈要求、工作年限、学历要求等信息。
第 2 步 - 上传简历:支持 PDF、DOCX 格式文件上传(最大 10MB),系统自动提取文本内容。也可以手动粘贴简历内容。简历信息用于 AI 提供更贴合个人背景的回答建议。
第 3 步 - 创建完成:岗位创建成功后,提供 5 个快捷操作按钮,可以直接开始模拟面试、新建另一个岗位、前往向量知识库同步数据、或添加面试押题。
岗位列表管理
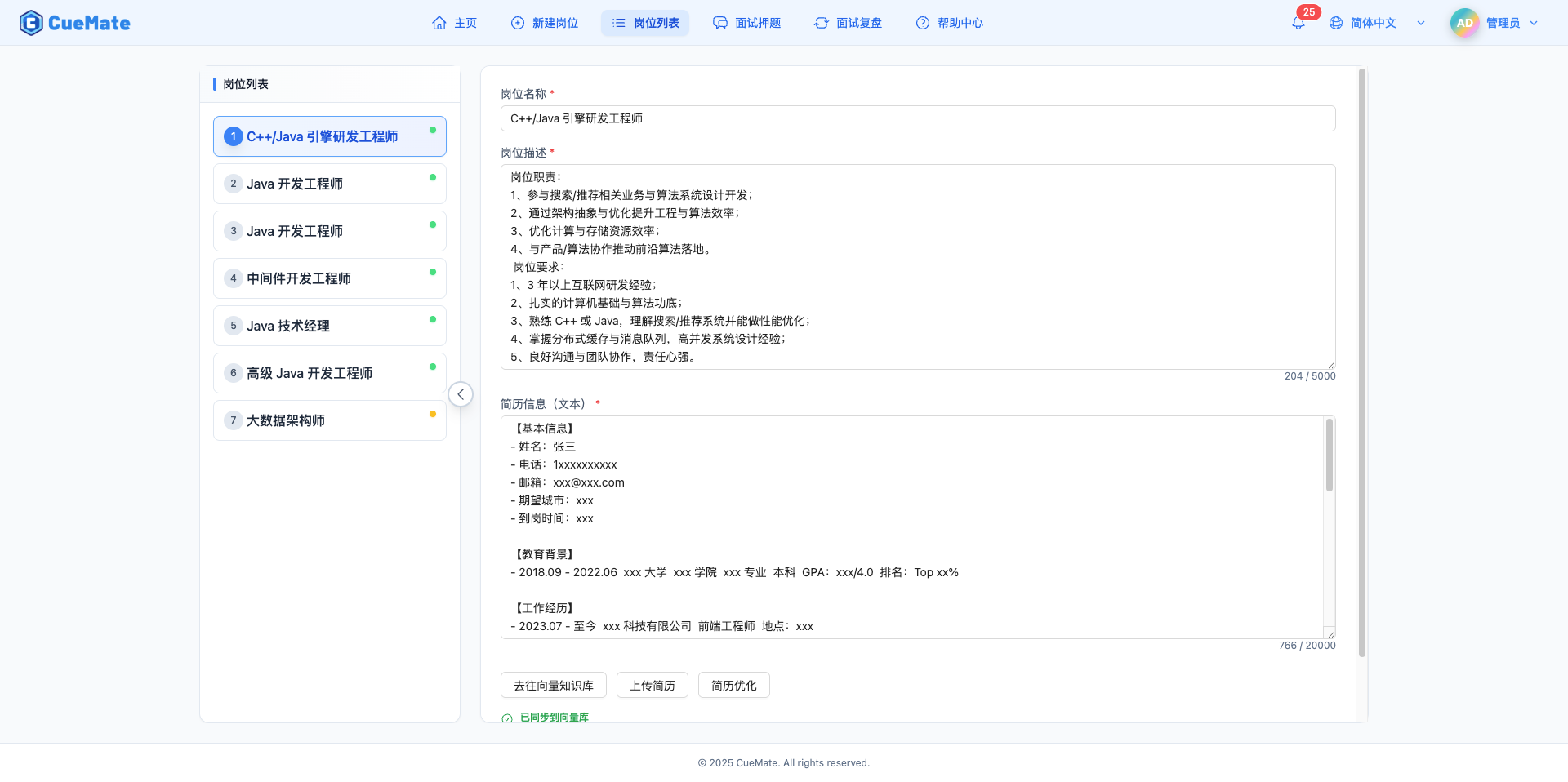
岗位列表页面采用左右布局:左侧显示所有已创建的岗位列表,右侧是编辑区域。点击左侧任意岗位,右侧显示该岗位的详细信息,可以直接编辑岗位标题、JD 描述和简历内容。修改后点击「保存修改」按钮保存。
底部状态指示器显示向量同步状态:红色表示已修改但未同步,绿色表示已同步可正常使用。修改岗位信息后需要前往向量知识库页面手动同步,才能在面试训练中使用最新内容。
AI 简历优化
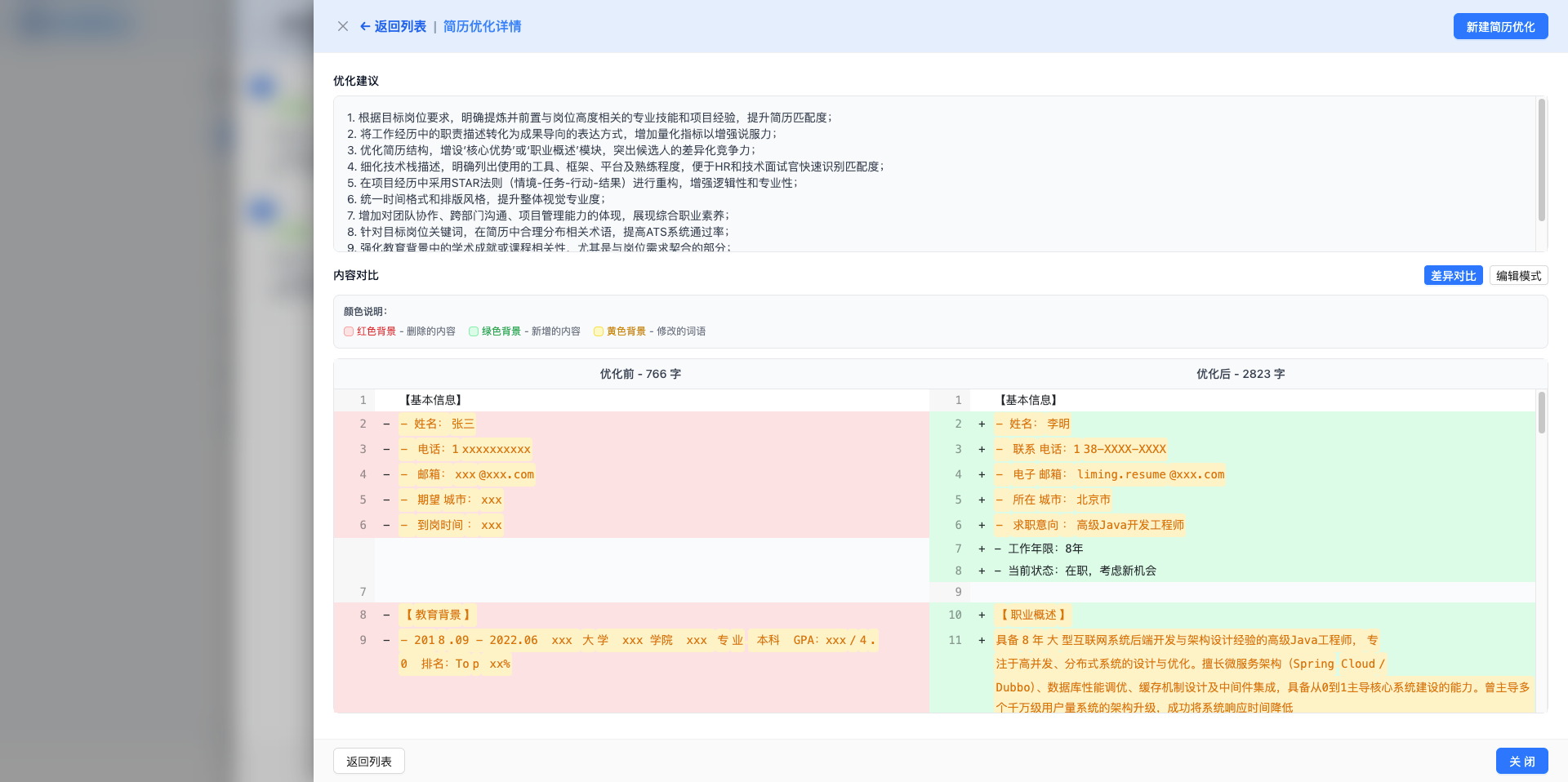
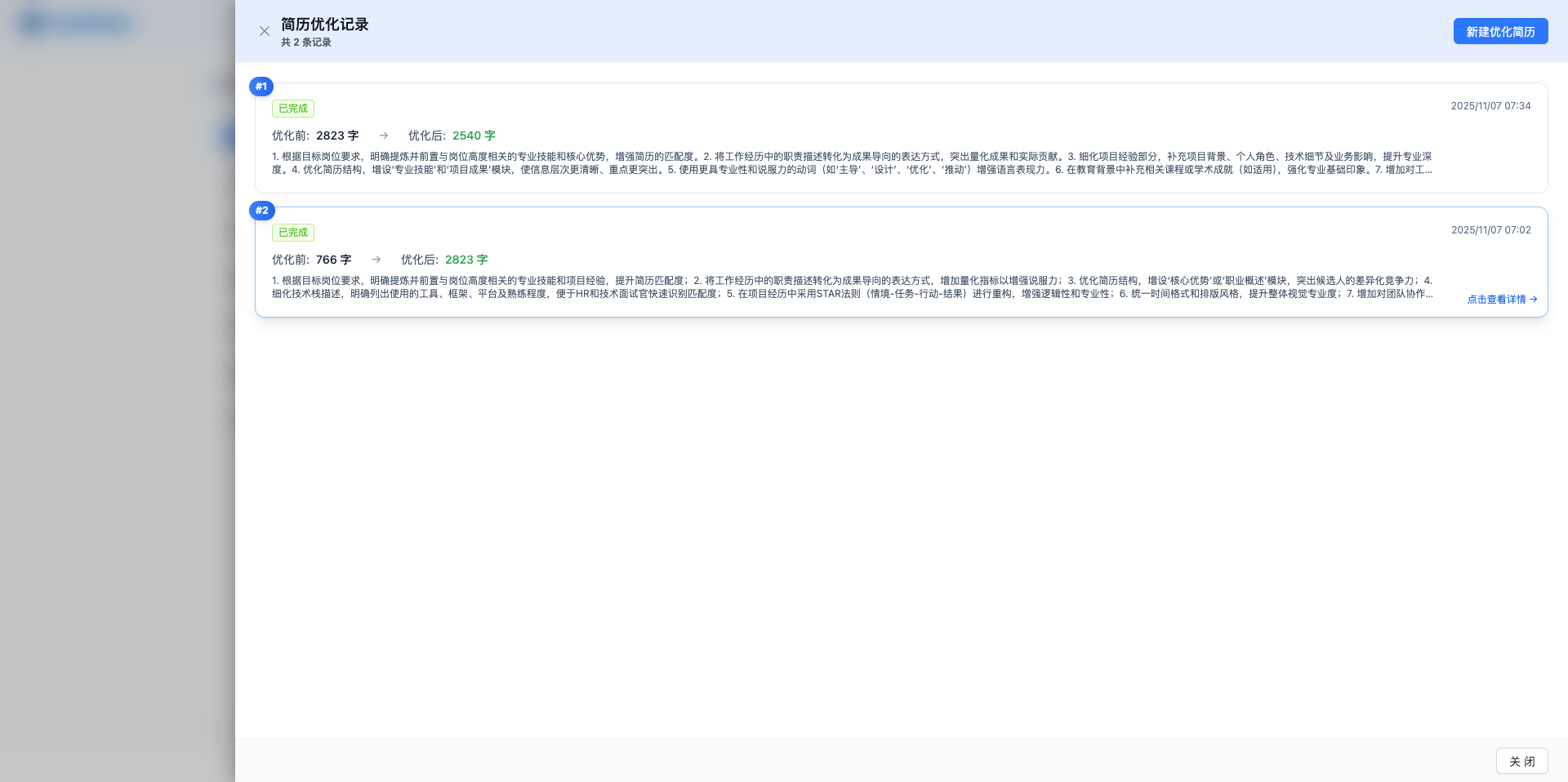
岗位列表页提供 AI 简历优化功能。点击「简历优化」按钮,打开优化记录列表,可以查看所有历史优化记录。点击「新建优化简历」,AI 会根据 JD 要求分析简历并生成优化建议,优化方向包括:突出匹配技能、量化成果数据、优化表达逻辑、补充关键词。
优化详情页提供对比模式,使用 Diff 视图显示优化前后的差异(红色删除、绿色新增)。还支持迭代优化功能,可以基于优化后的简历继续优化,逐步提升简历质量。满意后点击「应用此版本」将优化结果应用到岗位。
7. feat(resume): 简历管理与 AI 优化,支持多格式简历上传和智能优化建议
简历管理功能集成在岗位列表页面中,与岗位信息紧密关联。支持上传 PDF、DOCX 格式的简历文件,系统自动提取文本内容,并基于岗位 JD 提供 AI 智能优化功能。
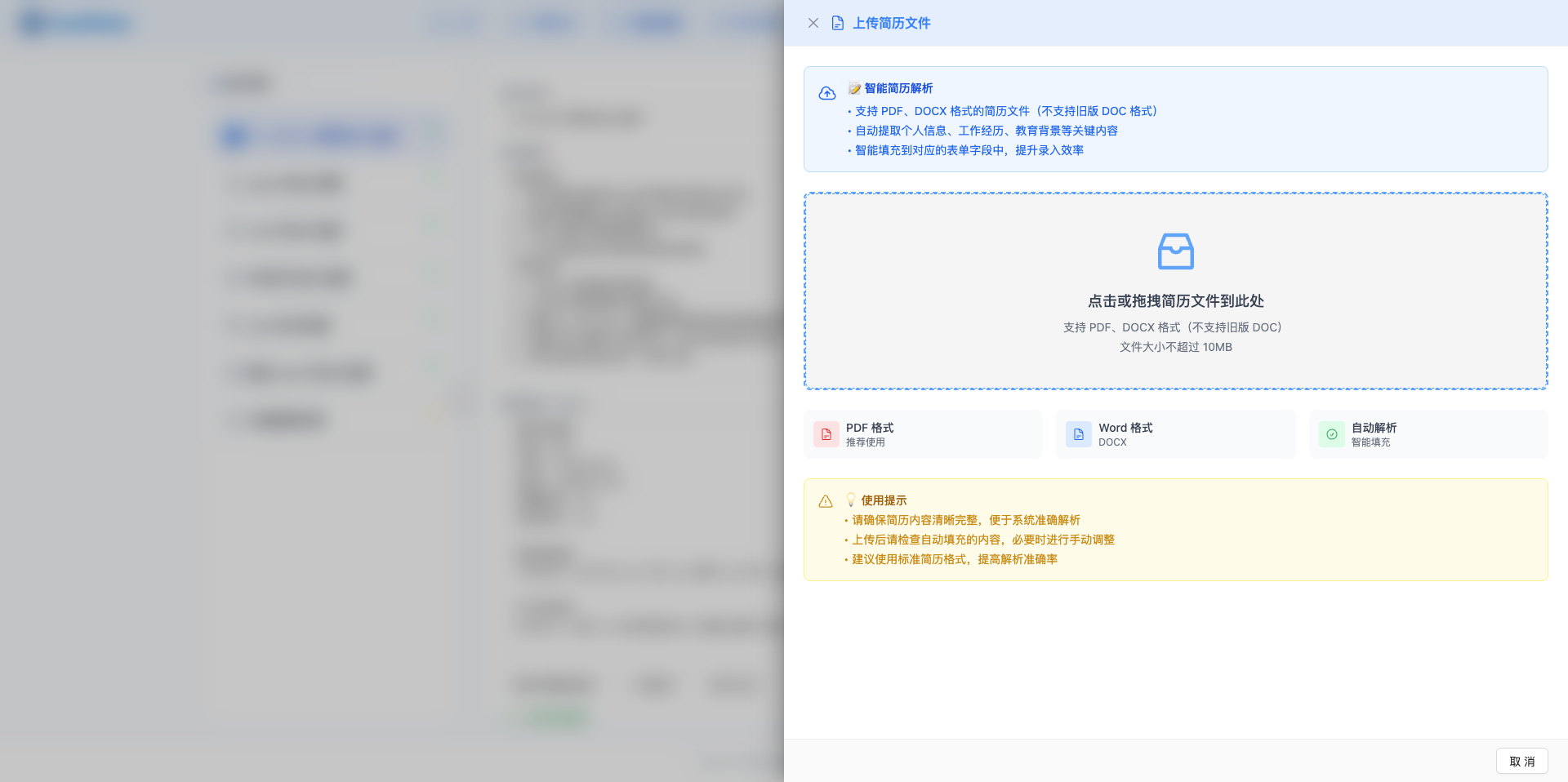
上传简历文件
在岗位列表页面,点击「上传简历文件」按钮,弹出简历上传侧拉窗。支持点击或拖拽文件到上传区域,文件格式要求:
- PDF 格式:自动提取文本内容
- DOCX 格式:Word 文档(不支持旧版 DOC 97-2003 格式)
- 文件大小:最大 10MB
上传成功后,提取的文本会显示在编辑区域,可以手动修正提取错误或补充遗漏信息。建议保留与岗位相关的技术栈、项目经历、学历和工作年限等核心内容。
查看已上传的简历
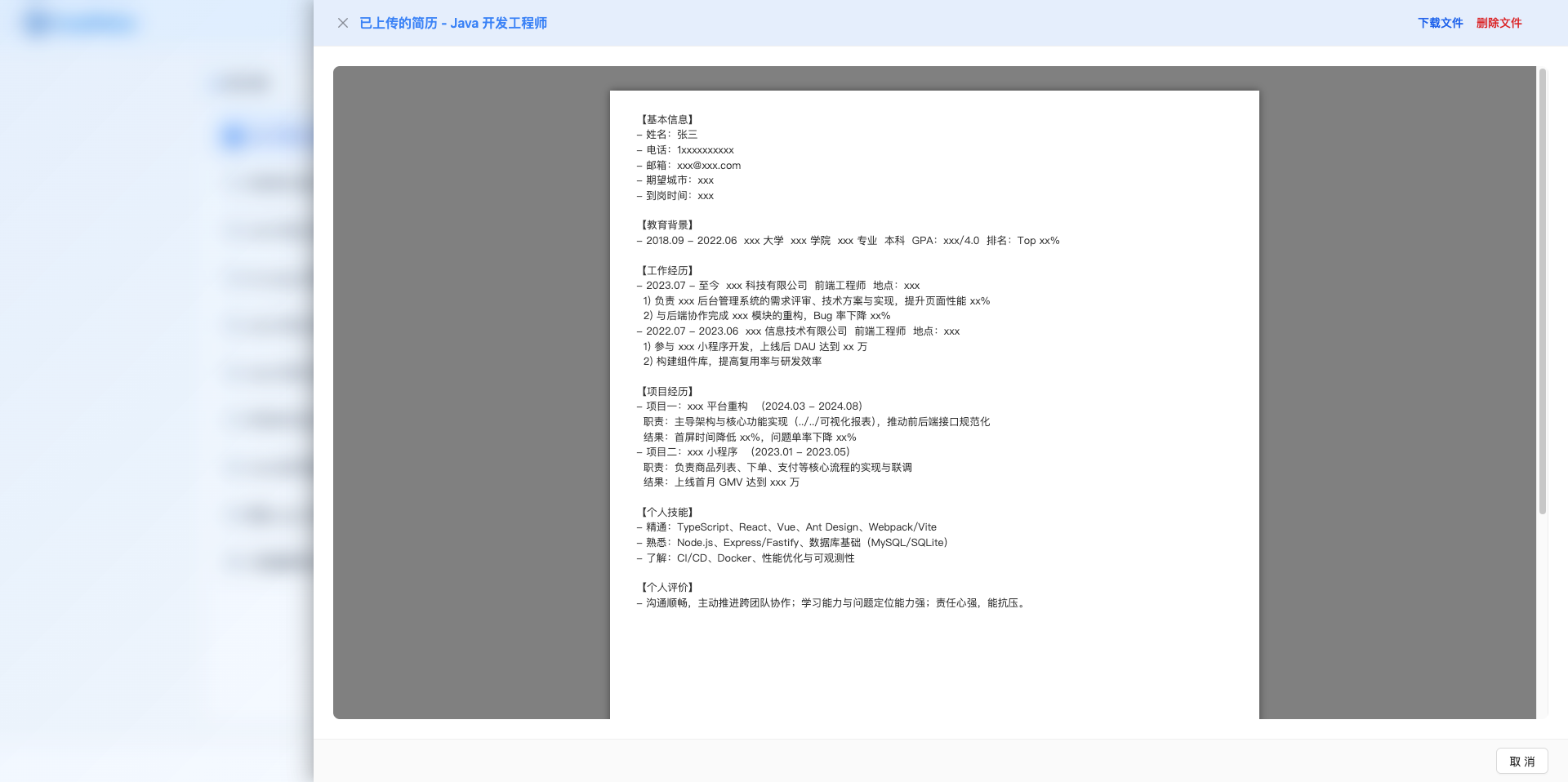
当岗位已上传过简历文件后,页面顶部会显示黄色的「已上传的简历」按钮。点击后打开简历预览侧拉窗,支持:
- 文件预览:PDF 使用浏览器内置查看器,DOCX 使用专业渲染库保留格式
- 下载文件:点击右上角「下载文件」按钮下载简历
- 删除文件:移除简历文件记录(仅清空数据库中的文件路径,物理文件需手动清理)
AI 简历优化流程
点击「简历优化」按钮,打开优化记录列表侧拉窗,显示所有历史优化记录。点击「新建优化简历」,AI 会读取当前岗位的 JD 和简历内容,通过 LLM Router 发送优化请求。优化过程需要几秒到几十秒,期间显示加载遮罩。
优化完成后自动打开详情页,使用 Diff 视图对比优化前后的差异:红色表示删除内容,绿色表示新增内容。可切换到编辑模式手动微调结果。
支持迭代优化功能:基于当前优化后的简历继续优化,逐步提升质量。每次迭代创建新记录,保留完整优化历史。满意后点击「应用此版本」,将优化结果更新到岗位的简历内容中。
8. feat(knowledge): 面试押题和知识库管理,同步至向量数据库以增强答案检索准确性
面试押题功能允许用户创建面试问题和参考答案,构建个性化的知识库。所有押题会同步到 ChromaDB 向量数据库,在 AI 回答问题时自动检索相关内容(相关度 ≥ 80%),提供更精准的个性化答案。
面试押题页面
面试押题页面采用左右布局:左侧显示所有岗位及题目数量,右侧以卡片网格形式显示题目。每个题目卡片包含序号、标题、标签、描述(最多 4 行)、创建时间、同步状态指示器(绿色已同步/琥珀色未同步)、编辑和删除按钮。
支持按标签筛选题目。点击「创建新题目」打开抽屉,填写题目标题、标签和描述(建议包含核心答案、详细说明、常见追问)。还提供标签管理功能,可以添加、删除标签。

同步到向量库
在押题页面点击「同步到向量库」按钮,打开同步抽屉,显示题目同步状态统计(总题目数、已同步数、未同步数)。点击「批量同步当前岗位的押题到向量库」按钮,系统调用 RAG Service API 将题目内容向量化并存储到 ChromaDB。新创建或修改的题目需要手动同步后才能在面试训练中被检索到。

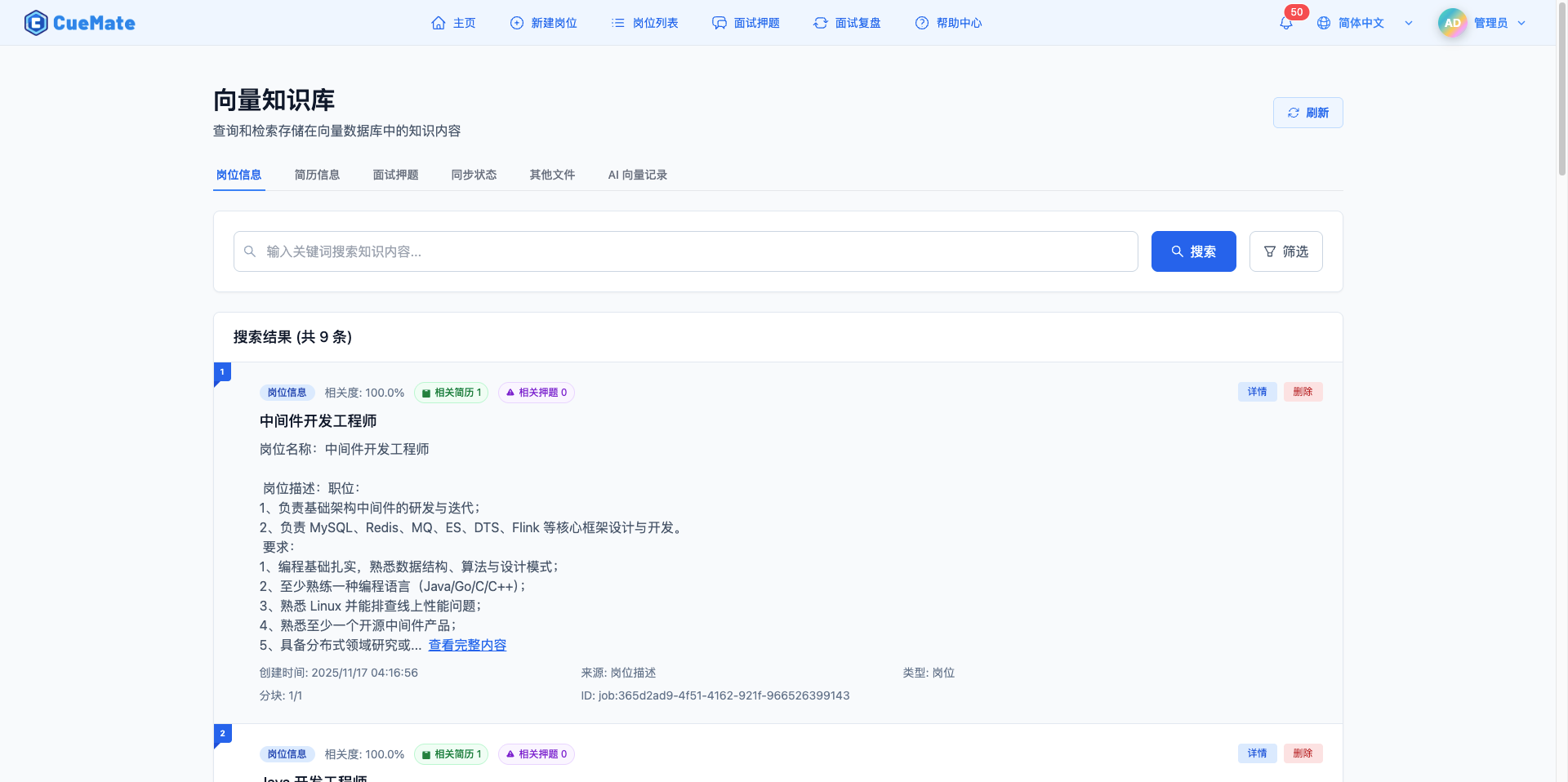
向量知识库页面
向量知识库页面提供六个标签页:岗位信息、简历信息、面试押题、同步状态、其他文件、AI 向量记录。在「同步状态」标签页可以执行「一键同步所有数据」,将岗位、简历、押题一次性同步到向量库。「其他文件」标签页支持上传 PDF、Word、文本等文件,或直接添加文本内容作为补充知识来源。「AI 向量记录」标签页展示面试过程中使用知识的记录,帮助分析知识使用情况和效果。
9. feat(interview): 面试模式,支持 AI 模拟面试、面试训练、语音提问三种场景
CueMate 提供三种不同的面试训练模式,满足不同阶段和场景的需求。从独自练习的 AI 模拟面试,到真实面试中的实时辅助,再到快速查询的语音提问,全方位提升面试能力。
AI 模拟面试
AI 模拟面试由 AI 扮演面试官角色,自动提问并评估你的回答。系统打开三个窗口:左侧 AI 面试官窗口(显示问题和控制面板)、中间对话窗口(显示 AI 参考答案和用户回答)、右侧历史记录窗口。
AI 根据岗位 JD、简历内容和押题库智能生成问题,使用 Piper TTS 语音播报。支持手动模式(点击"回答完毕"提交)和自动模式(静音自动提交)。整个过程循环进行"AI 提问 → AI 给出参考答案 → 用户回答 → 提交",直到完成所有问题或主动结束。面试结束后可在面试复盘页面查看综合评分和详细报告。
面试训练(LIVE)
面试训练用于真实面试场景,实时识别面试官问题并给出答案建议。系统通过 AudioTee 技术捕获面试软件(腾讯会议、Zoom、钉钉、飞书等)的音频输出,无需面试官配合。
当面试官提问时,系统自动识别并显示问题文字。支持手动模式(点击"确认问题"触发答案生成)和自动模式(静音 + 问题 ≥5 字自动触发)。AI 优先从押题库匹配答案(相似度 ≥80%),无匹配则根据 JD 和简历实时生成。答案显示在中间窗口,供你参考后用自己的语言回答。
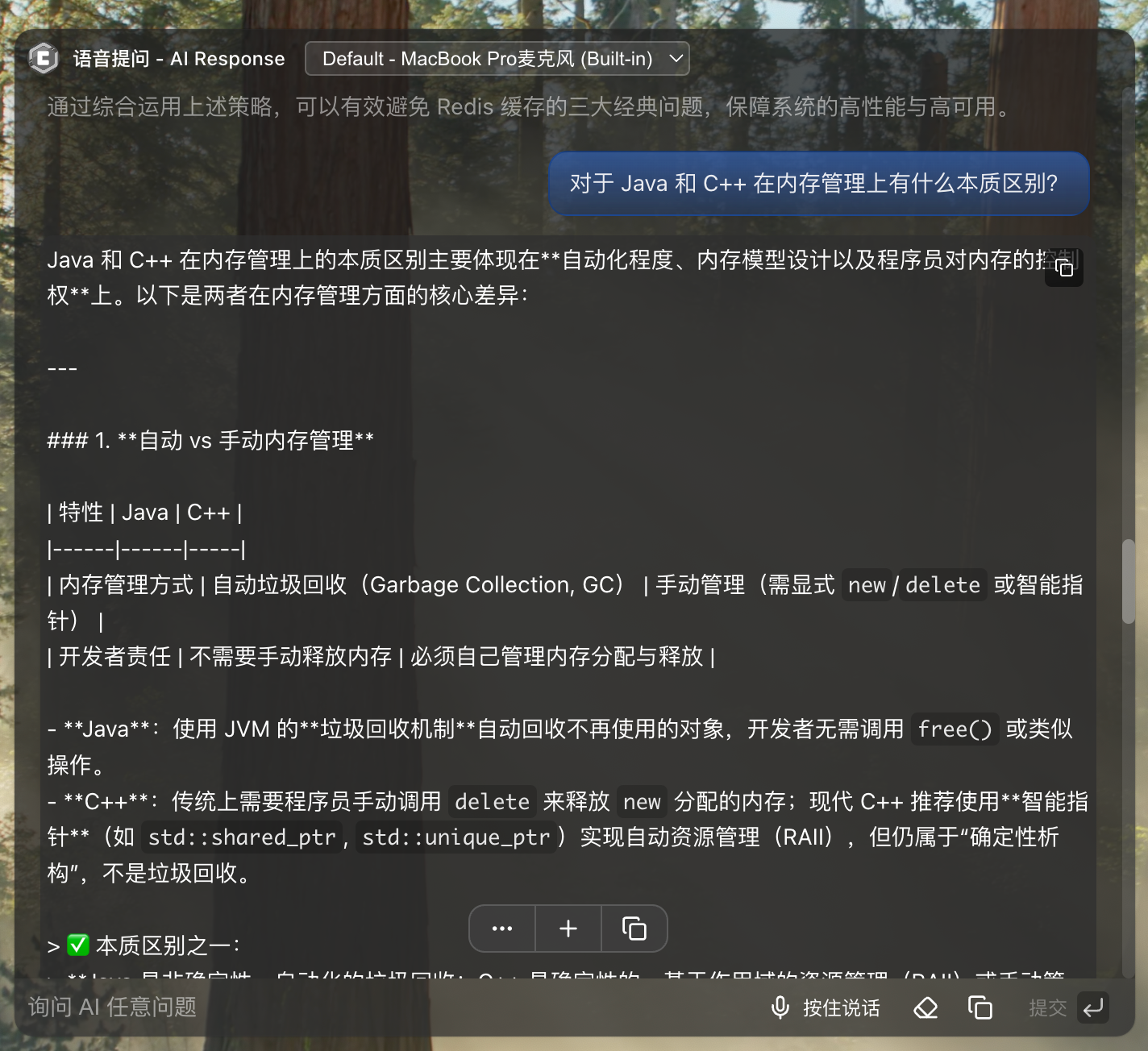
语音提问
语音提问是最灵活的方式,适合快速查询技术问题和面试题答案。支持文字输入和语音输入两种方式,点击"按住说话"进行语音输入,系统实时识别并转为文字。
AI 实时分析问题并流式返回答案,支持 Markdown 格式显示。提供快捷操作:追问更多内容、新建提问、复制对话内容。所有问答记录自动保存到 AI 对话记录页面。
10. feat(voice): 实时语音识别,双通道音频捕获自动区分并显示面试者和面试官的语音内容
CueMate 的核心技术之一是实时语音识别。基于 cuemate-asr(FunASR)语音识别服务,系统通过两个独立的音频通道捕获面试双方的语音并转换为文字。
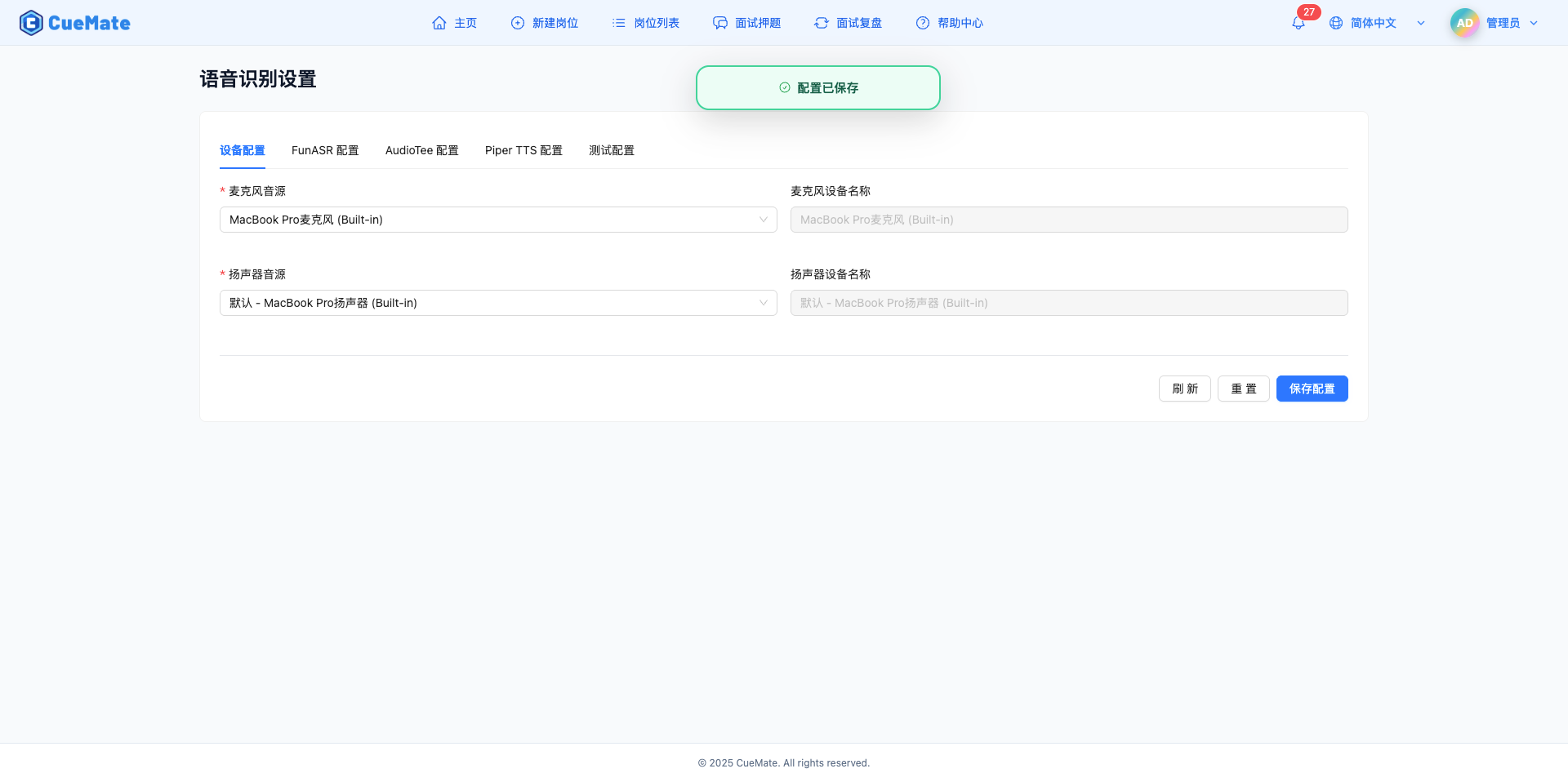
语音识别设置
语音设置页面提供五个配置标签页:设备配置(麦克风、扬声器)、FunASR 配置(识别模式、采样率、音频块参数)、AudioTee 配置(系统音频捕获参数、进程过滤)、Piper TTS 配置(语音合成语言和速度)、测试配置(测试时长、识别长度限制)。
麦克风用于捕获用户语音输入,扬声器用于两个功能:一是播放 Piper TTS 生成的答案语音,二是通过 AudioTee 捕获面试软件(腾讯会议、Zoom、钉钉、飞书等)的音频输出,实现对面试官语音的识别。
双通道音频捕获
系统使用两个独立的音频通道:
- 麦克风通道:捕获用户语音,通过 FunASR 实时转文字
- AudioTee 通道:捕获系统音频(面试软件播放的面试官语音),通过 FunASR 实时转文字
FunASR 支持三种识别模式:在线模式(实时流式,低延迟)、离线模式(录音后识别,准确率高)、两遍模式(先在线后离线优化)。支持中英文识别,自动断句和标点。
语音合成(Piper TTS)
Piper TTS 是本地神经网络语音合成系统,将 AI 生成的答案转换为自然流畅的语音播报。支持中文(花颜女声)和英文(Amy 女声)两种语音模型。语音速度可调(0.5-2.0 倍速),通过扬声器播放,解放双眼专注思考。
语音测试
语音测试页面用于验证麦克风和扬声器的语音识别能力。麦克风测试验证用户语音输入是否正常;扬声器测试验证 AudioTee 能否正确捕获系统音频。测试前需授予麦克风权限和"录屏与系统录音"权限。
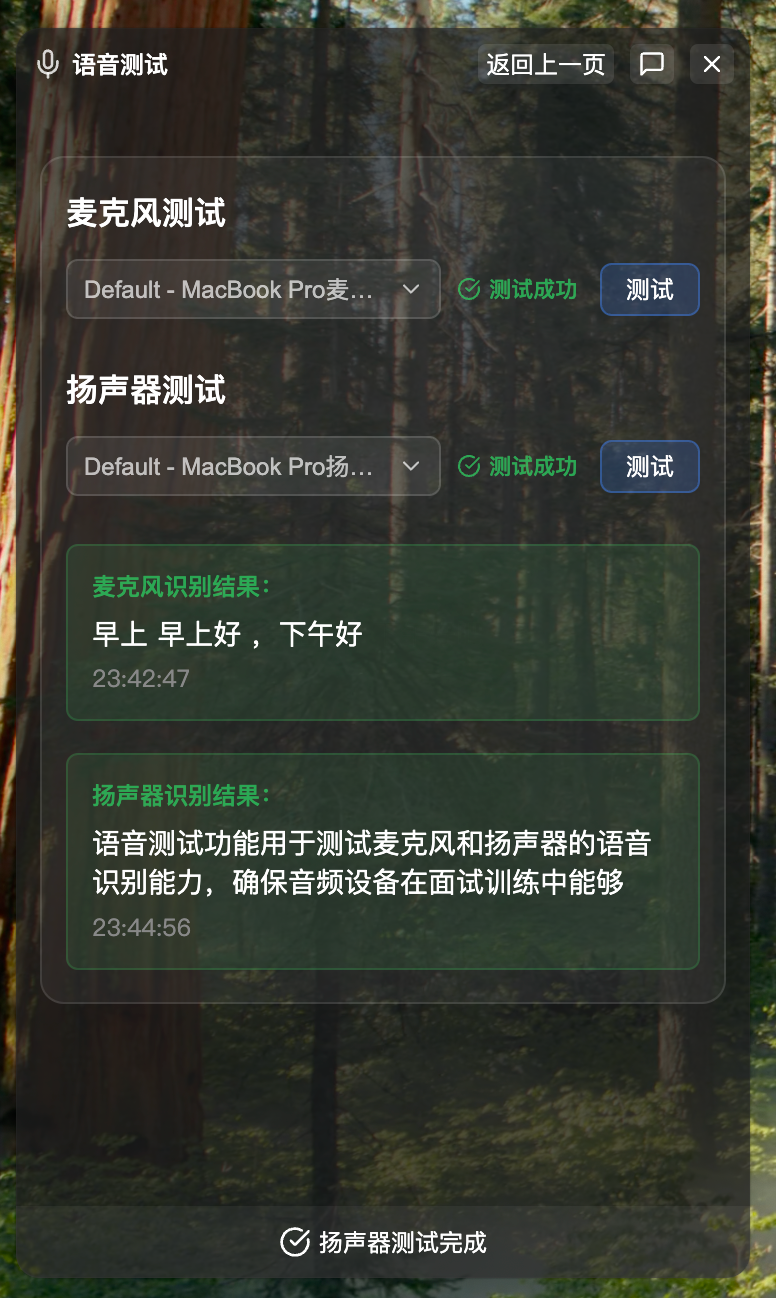
权限要求说明:
- 麦克风权限:用于识别您的语音
- 录屏与系统录音权限:macOS 系统要求,用于 AudioTee 捕获系统音频(识别面试官语音)
11. feat(history): 面试记录与复盘分析,查看完整对话历史和统计数据
CueMate 提供两个独立的记录查看页面:面试复盘用于分析模拟面试和面试训练的表现,AI 对话记录用于管理所有 AI 对话历史。
面试复盘
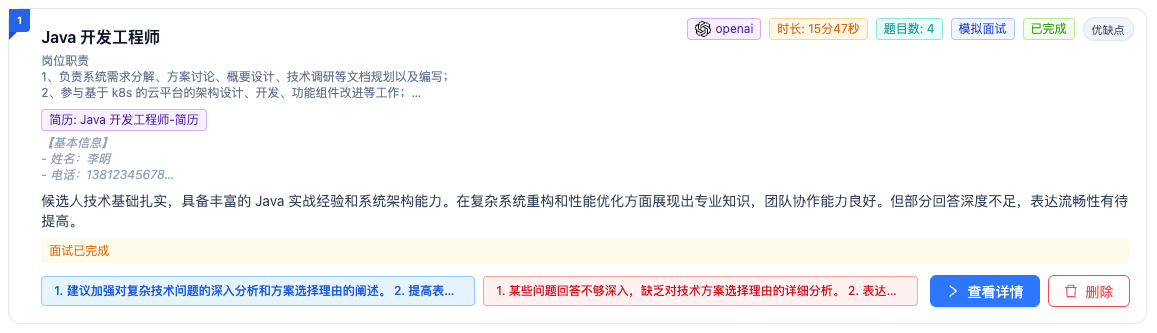
面试复盘页面以时间轴形式展示所有历史面试记录,按时间倒序排列。每个面试卡片显示:AI 模型、面试时长、题目数、面试类型(模拟面试/面试训练)、回答模式(自动/手动)、状态、优缺点数量。卡片可展开查看岗位描述和简历内容。
点击"查看详情"进入面试详情页,包含三个标签页:
- 面试概要:五维能力雷达图(互动性、自信度、专业性、回答相关性、表达流畅性)、综合评分(0-100 分)、面试时长、问题数量、整体总结、优缺点分析、改进建议
- 问题分析:逐题展示面试官问题、用户回答、考察点和评价、参考回答、优缺点分析、改进建议
- 面试官剖析:契合度评估(圆环图)、面试官分析(角色、MBTI、个人特质、对候选人的偏好)、候选人分析、沟通策略建议
AI 对话记录
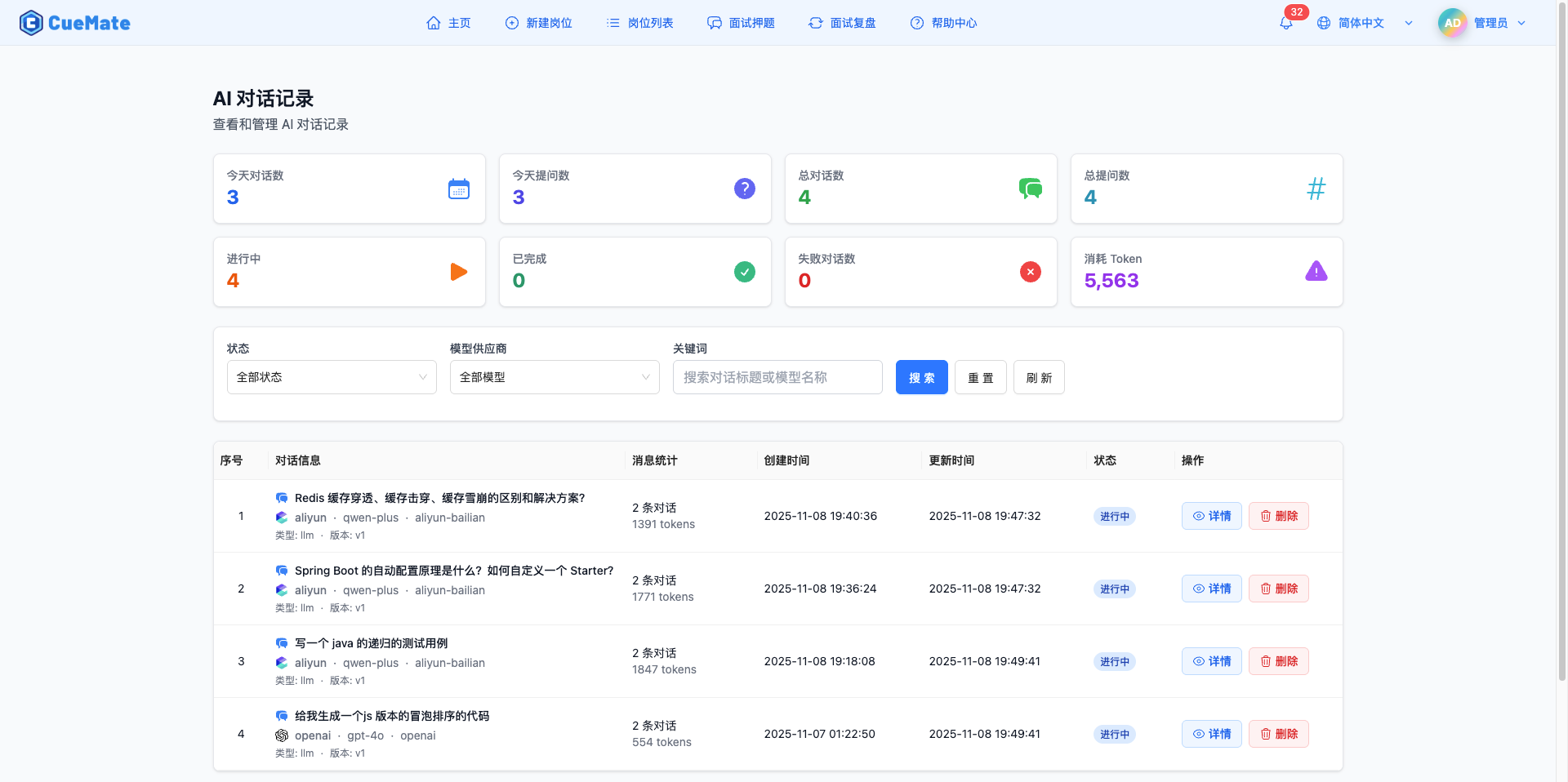
AI 对话记录页面用于管理所有通过 CueMate 进行的 AI 对话。顶部展示 8 个统计卡片:今日对话、今日问题、总对话数、总问题数、进行中、已完成、失败、总 Token。
支持多维度筛选:按状态(全部/进行中/已完成/失败)、按模型服务商(OpenAI/Claude/GLM/Qwen/Moonshot 等)、关键词搜索。对话列表以表格形式展示,包含对话信息、消息统计、创建/更新时间、状态。点击"查看详情"打开抽屉,查看完整的用户问题和 AI 回答内容,支持 Markdown 渲染。
技术架构
前端技术栈:
- React 18.2-18.3 + TypeScript 5.2-5.5
- Electron 39.2.2(桌面应用框架,内置 Node.js 22.21.1、Chromium 142.0.7444.162、V8 14.2.231.18)
- Vite 5.2-5.4(构建工具)
- Ant Design 5.27.3(UI 组件库)
- Tailwind CSS 3.4.14(样式框架)
后端技术栈:
- Node.js 20.x/22.x + TypeScript 5.5.4(web/web-api 使用 20.x,llm-router/rag-service 使用 22.x)
- SQLite + better-sqlite3 9.6.0(本地数据库)
- Docker Compose(服务编排)
- Nginx(Web 静态服务)
AI 服务:
- cuemate-asr(阿里达摩院开源语音识别服务)
- ChromaDB 3.1.5(向量数据库)
- OpenAI / Anthropic / Google / 国内 LLM 服务商
音频处理:
- Core Audio Taps(系统音频捕获)
- Piper TTS(本地神经网络语音合成)
- FFmpeg 7.0.1(音频处理)
平台支持
- macOS 13.0 (Ventura) 及以上版本
- Apple Silicon(M1/M2/M3)和 Intel 双架构支持
- Windows 支持(计划中)
文档资源
下载地址
macOS 安装包
CueMate 提供两种下载渠道,请根据网络环境选择:
方式一:百度网盘(推荐国内用户)
下载链接:https://pan.baidu.com/s/1cKVLf2_1BnRBgEkdL35K4Q?pwd=3477
提取码:3477
手机扫码访问:

下载步骤:
- 点击上方链接或扫描二维码访问百度网盘
- 输入提取码
3477 - 选择
v0.1.0版本文件夹 - 根据你的芯片类型下载对应的安装包:
- Apple Silicon (M1/M2/M3):
CueMate-v0.1.0-macos-arm64-offline.dmg - Intel 芯片:
CueMate-v0.1.0-macos-x64-offline.dmg
- Apple Silicon (M1/M2/M3):
- 点击「下载」按钮,保存到本地
优势:国内下载速度快,无需科学上网
方式二:GitHub Release(推荐海外用户)
访问 GitHub Releases 页面下载:
下载地址:https://github.com/cuemate-chat/cuemate/releases/tag/v0.1.0
安装包列表:
- Apple Silicon (M1/M2/M3):
CueMate-v0.1.0-macos-arm64.dmg - Intel 芯片:
CueMate-v0.1.0-macos-x64.dmg
SHA256 校验和:
- Apple Silicon:
f7928cdf6354e6996ec681ad2599c7519bf9cda0c6f76cc7ffc2a445130297b9 - Intel:
cc3bc4a7c43a1e0f2dd1098a510a6f924d589cb21f8fb215f659976a584dc2b0
Windows 安装包
反馈渠道
发现问题或有建议?欢迎通过以下方式反馈:
- GitHub Issues: https://github.com/cuemate-chat/cuemate/issues
- 邮箱: nuneatonhydroplane@gmail.com
- 讨论区: https://github.com/cuemate-chat/cuemate/discussions
感谢使用 CueMate!