
配置 Ollama
Ollama 是一个轻量级本地大模型运行框架,支持在个人电脑上快速部署和运行开源大语言模型。提供简单的命令行工具和 API 接口,让本地 AI 部署变得简单高效。
1. 安装 Ollama
1.1 下载 Ollama
访问 Ollama 官网下载对应系统的安装包:https://ollama.com/
1.2 安装 Ollama
下载对应系统的安装包并运行安装程序:
- macOS:下载 .dmg 文件,拖拽到 Applications 文件夹
- Windows:下载 .exe 安装包,双击运行安装
- Linux:下载对应发行版的安装包(.deb / .rpm)或使用包管理器安装
1.3 验证安装
打开终端,运行以下命令验证安装:
ollama --version
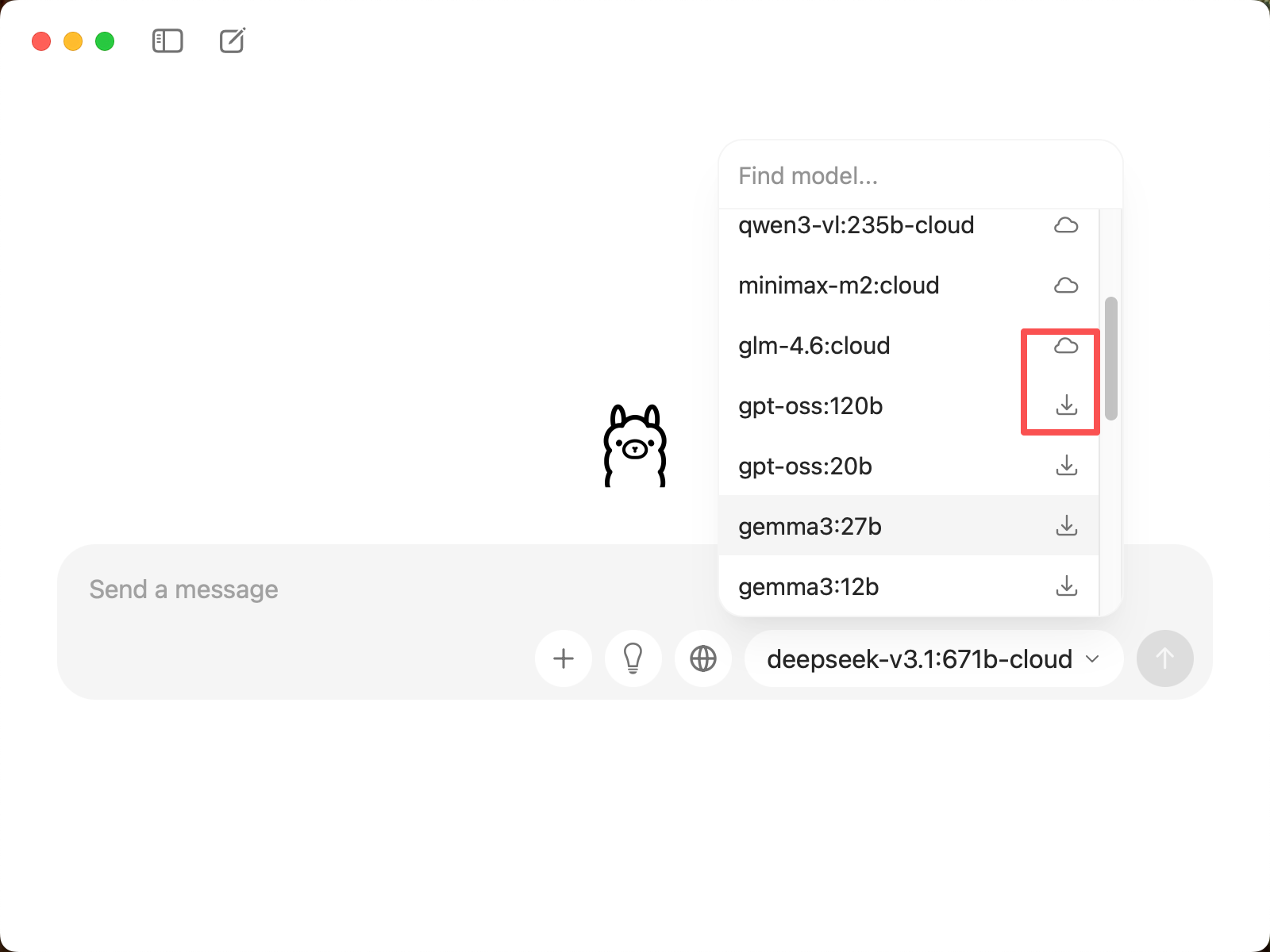
1.4 选择模型
在 CueMate 的模型选择界面,你可以看到两种类型的模型:
云端模型(名称包含
-cloud):- 无需下载,直接通过网络调用
- 示例:
deepseek-v3.1:671b-cloud、qwen3-coder:480b-cloud、glm-4.6:cloud - 优势:无需本地存储空间,支持超大参数模型(如 671B)
本地模型(标记 ↓,无
-cloud后缀):- 首次选择时会自动下载到本地
- 示例:
gpt-oss:120b、gemma3:27b、deepseek-r1:8b、qwen3:8b - 优势:运行速度快,无需网络连接,数据隐私性高
1.5 云端模型配置(使用云端模型必做)
如果你选择使用云端模型(如 deepseek-v3.1:671b-cloud),需要先在 Ollama 官网创建模型:
1.5.1 访问 Ollama 官网
访问 https://ollama.com/ 并登录或注册账号。
1.5.2 创建云端模型
- 登录后,点击 Models 菜单
- 点击 Create a new model 按钮
- 填写模型名称(例如:CueMate)
- 选择 Private(私有)或 Public(公开)
- 点击 Create model 完成创建
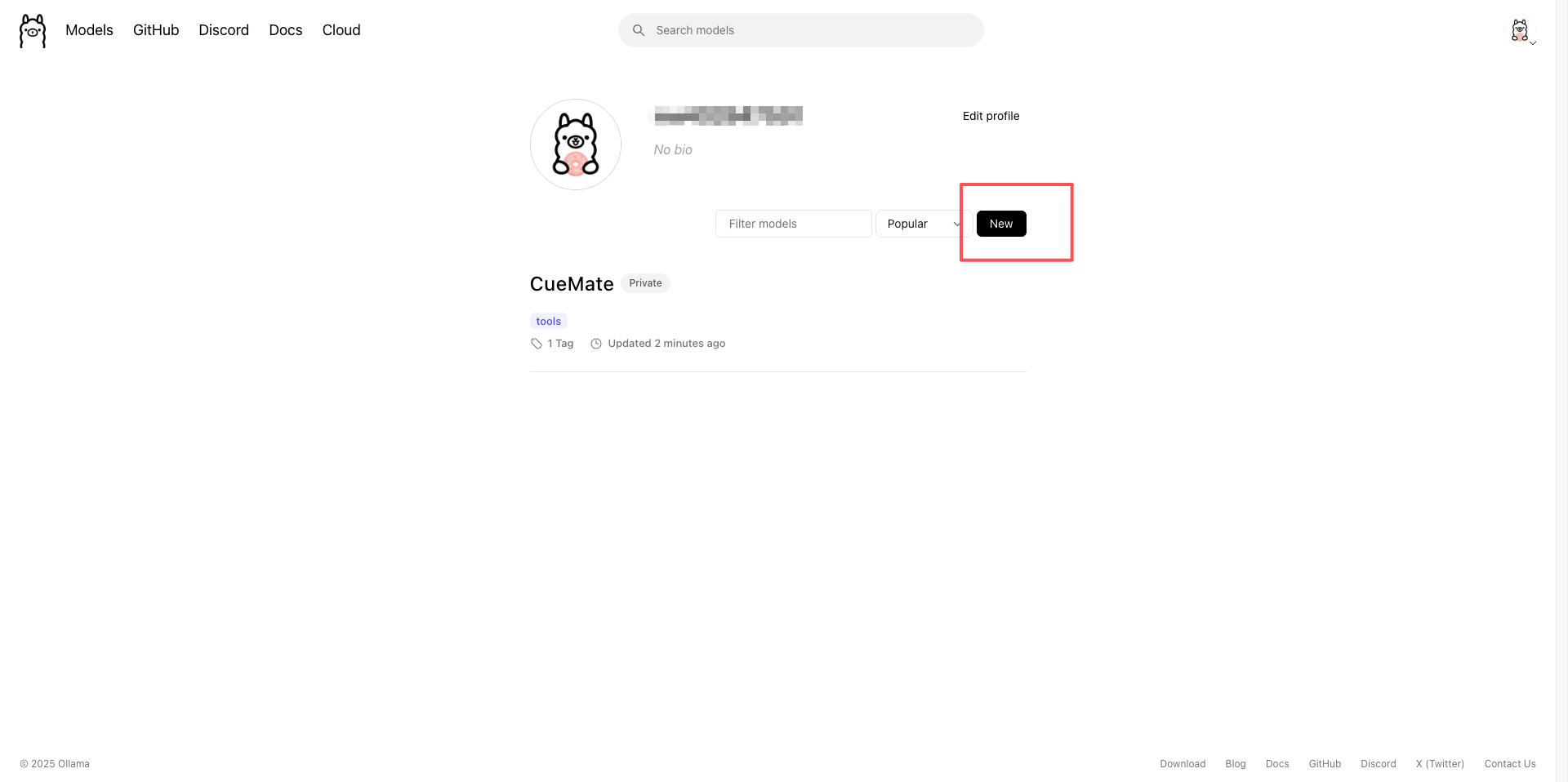
创建后会进入模型详情页:
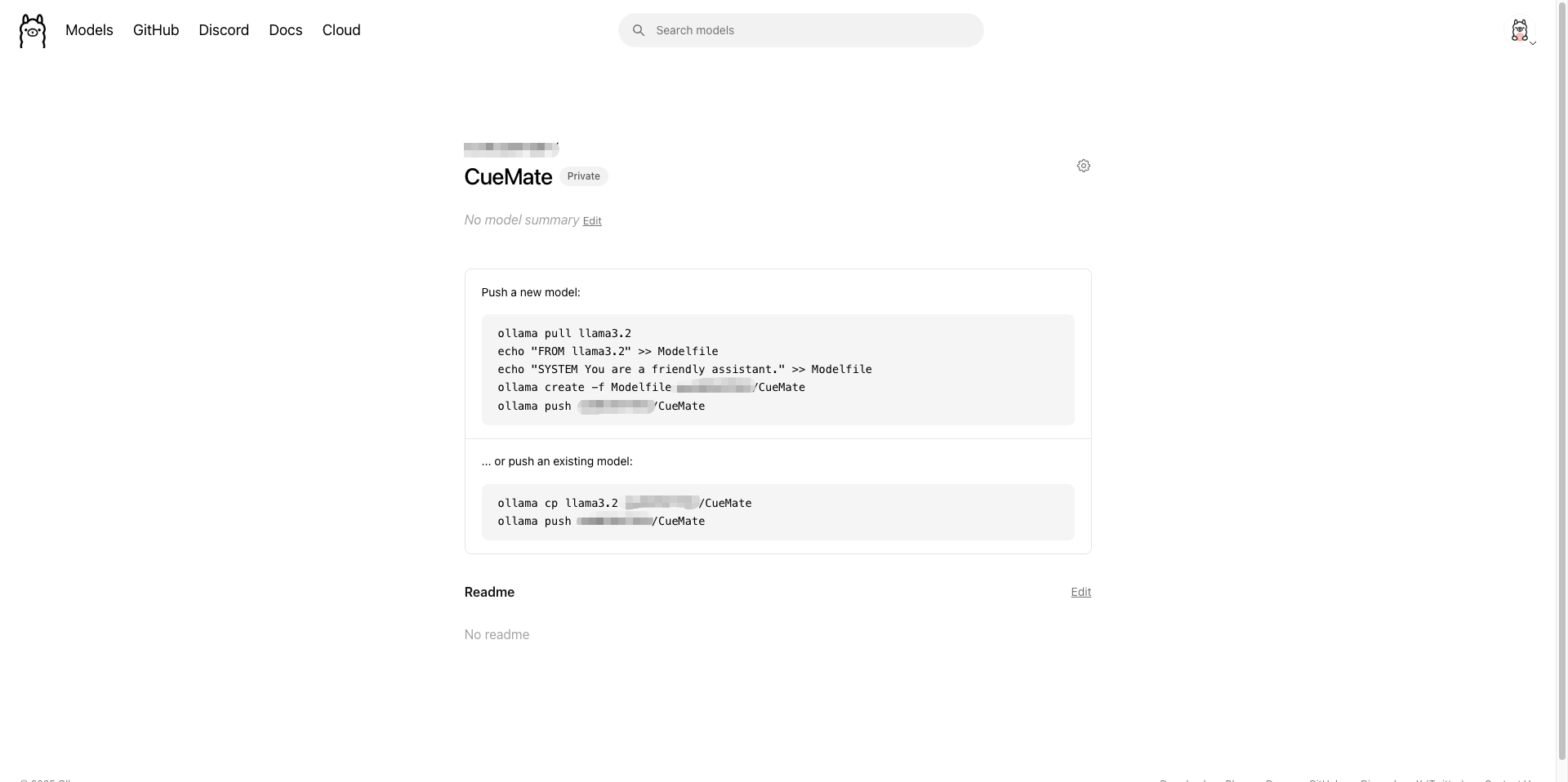
1.5.3 推送模型到云端
创建模型后,页面会显示推送命令。有两种方式:
方式一:基于现有模型创建并推送
# 1. 拉取基础模型
ollama pull llama3.2
# 2. 创建 Modelfile
echo "FROM llama3.2" >> Modelfile
echo "SYSTEM You are a friendly assistant." >> Modelfile
# 3. 创建自定义模型
ollama create -f Modelfile 你的用户名/CueMate
# 4. 推送到云端
ollama push 你的用户名/CueMate方式二:直接复制现有模型并推送
# 复制现有模型
ollama cp llama3.2 你的用户名/CueMate
# 推送到云端
ollama push 你的用户名/CueMate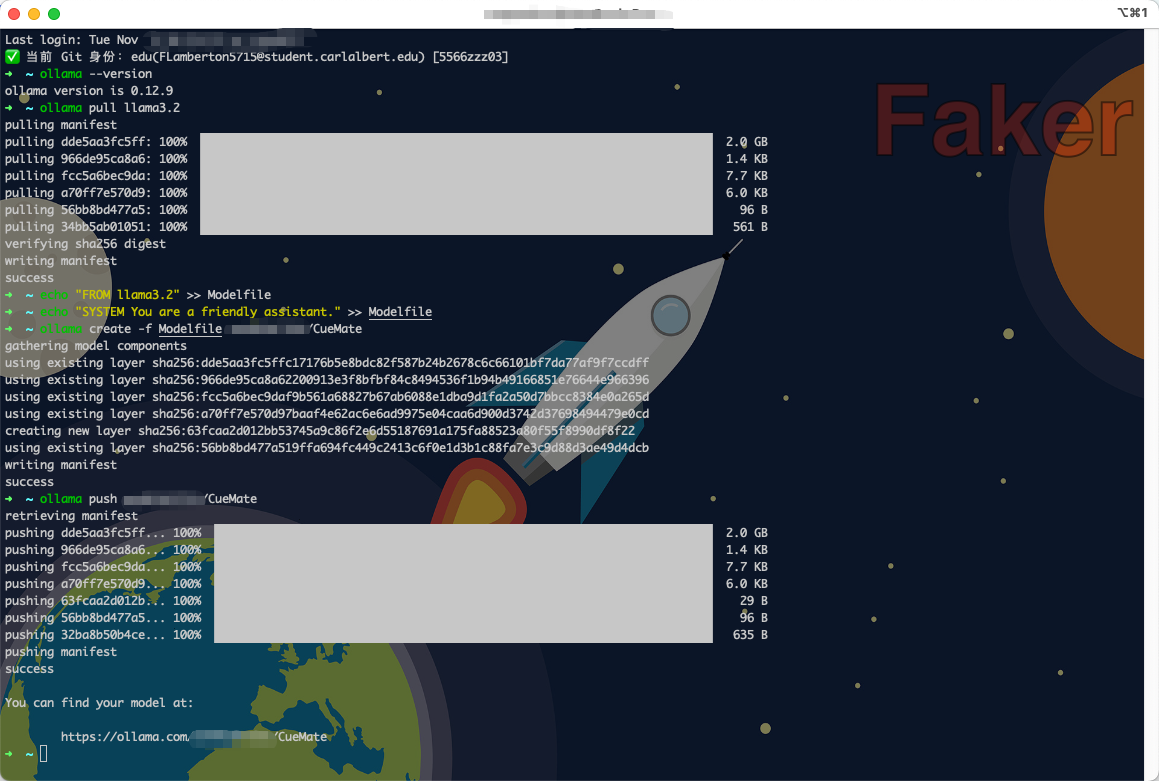
1.5.4 查看云端模型地址
推送成功后,页面会显示你的云端模型访问地址:
You can find your model at:
https://ollama.com/你的用户名/CueMate这个地址就是你的云端模型链接,可以分享给其他人使用。
1.5.5 获取 API Key(在 CueMate 中使用)
在 CueMate 中配置云端模型时需要 API Key:
- 访问 Ollama 官网设置页面:https://ollama.com/settings/keys
- 点击 Create new key 创建新的 API Key
- 复制生成的 API Key 保存备用
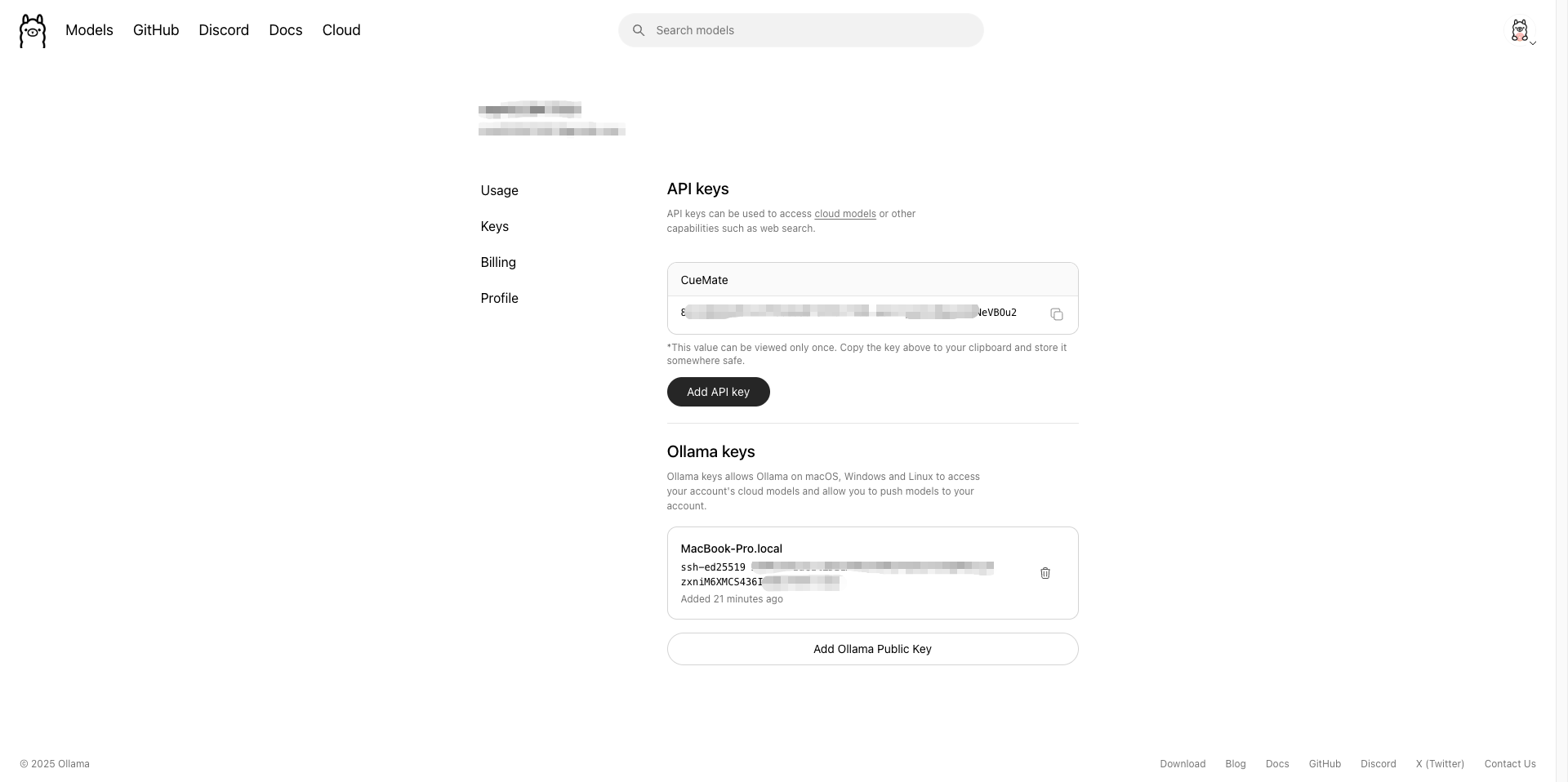
在 CueMate 中配置时填写:
- 模型名称:
你的用户名/CueMate(云端模型无需添加:cloud后缀) - API URL:
https://ollama.com - API Key:刚才创建的 API Key
1.6 本地模型配置(使用本地模型必做)
如果你选择使用本地模型(如 gemma3:12b、deepseek-r1:8b),需要启动本地 Ollama 服务:
- Ollama 安装后会自动启动服务,默认监听
http://localhost:11434 - 验证服务是否运行:bash
curl http://localhost:11434/api/version - 本地模型首次使用时会自动下载
2. 在 CueMate 中配置 Ollama 模型
2.1 进入模型设置页面
登录 CueMate 系统后,点击右上角下拉菜单的 模型设置。
2.2 添加新模型
点击右上角的 添加模型 按钮。

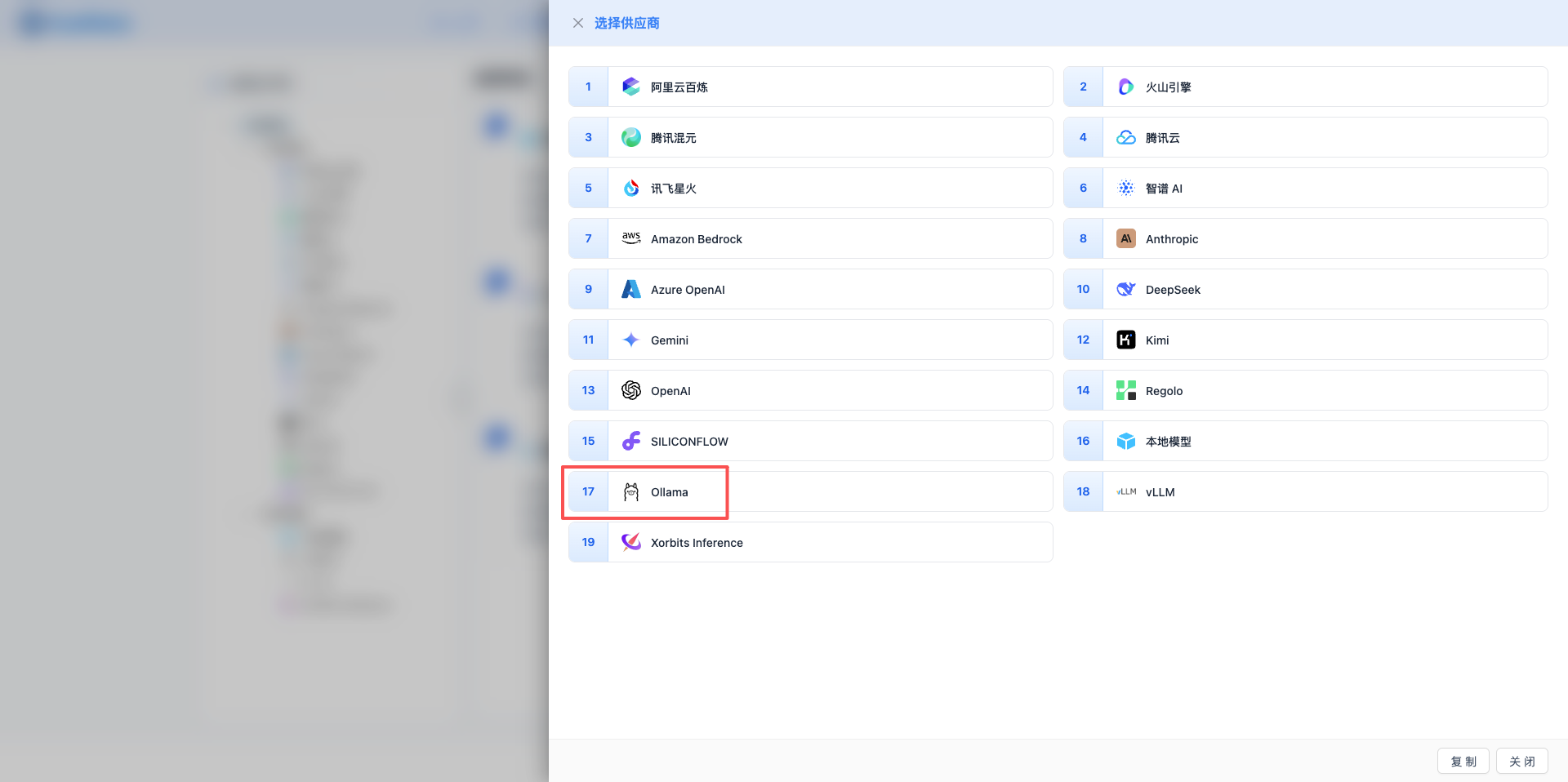
2.3 选择 Ollama 服务商
在弹出的对话框中:
- 服务商类型:选择 Ollama
- 点击后 自动进入下一步
2.4 填写配置信息
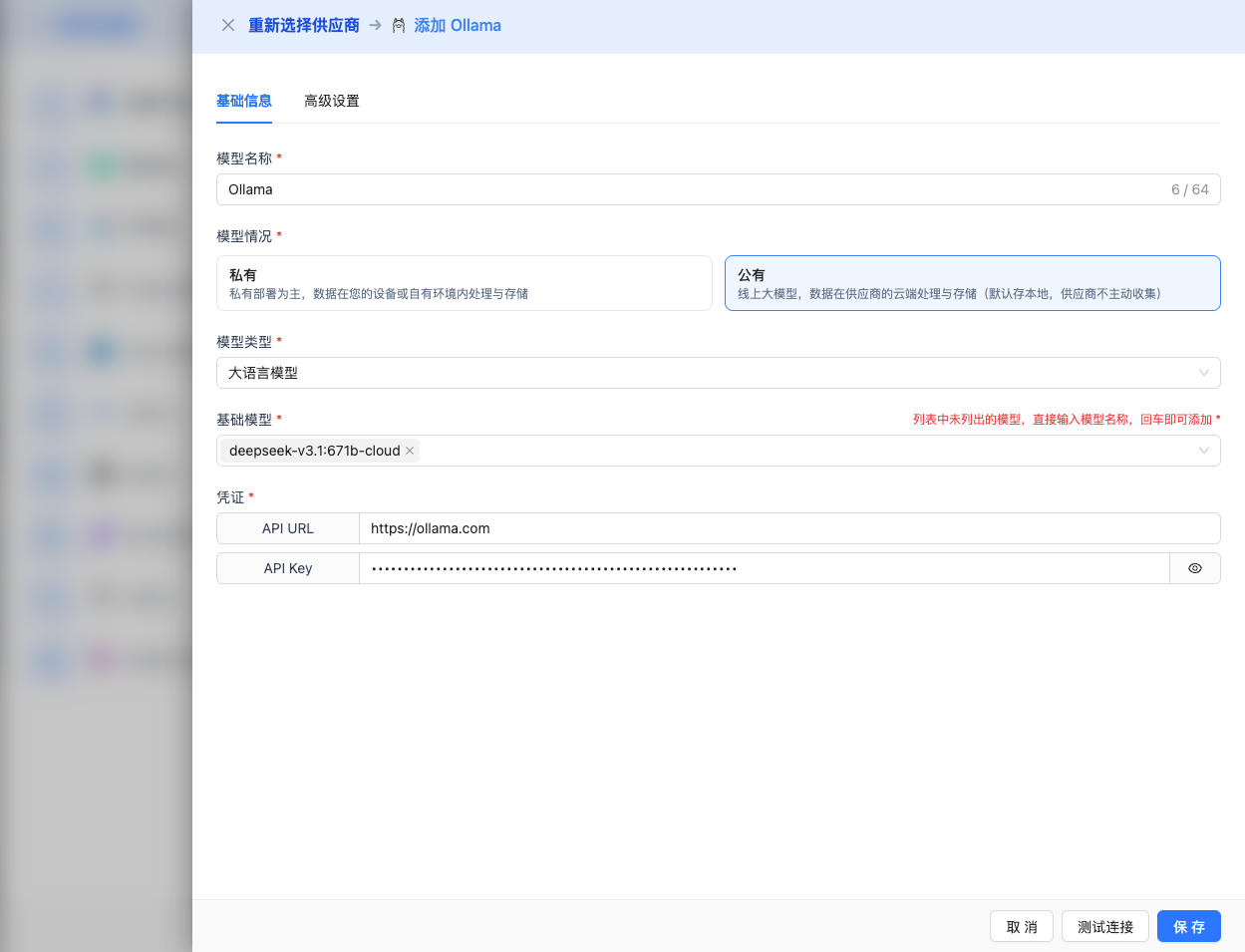
在配置页面填写以下信息:
基础配置
- 模型名称:为这个模型配置起个名字(例如:本地 DeepSeek R1)
- API URL:保持默认
http://localhost:11434(如果 Ollama 运行在其他地址,需修改) - 模型版本:输入已下载的模型名称
2025 推荐模型:
- 云端模型:
deepseek-v3.1:671b-cloud、qwen3-coder:480b-cloud、qwen3-vl:235b-cloud、glm-4.6:cloud、minimax-m2:cloud - 本地模型:
gpt-oss:120b、gemma3:27b、gemma3:12b、deepseek-r1:8b、qwen3-coder:30b、qwen3-vl:30b、qwen3:30b、qwen3:8b
注意:本地模型首次使用时会自动下载,云端模型无需下载。
高级配置(可选)
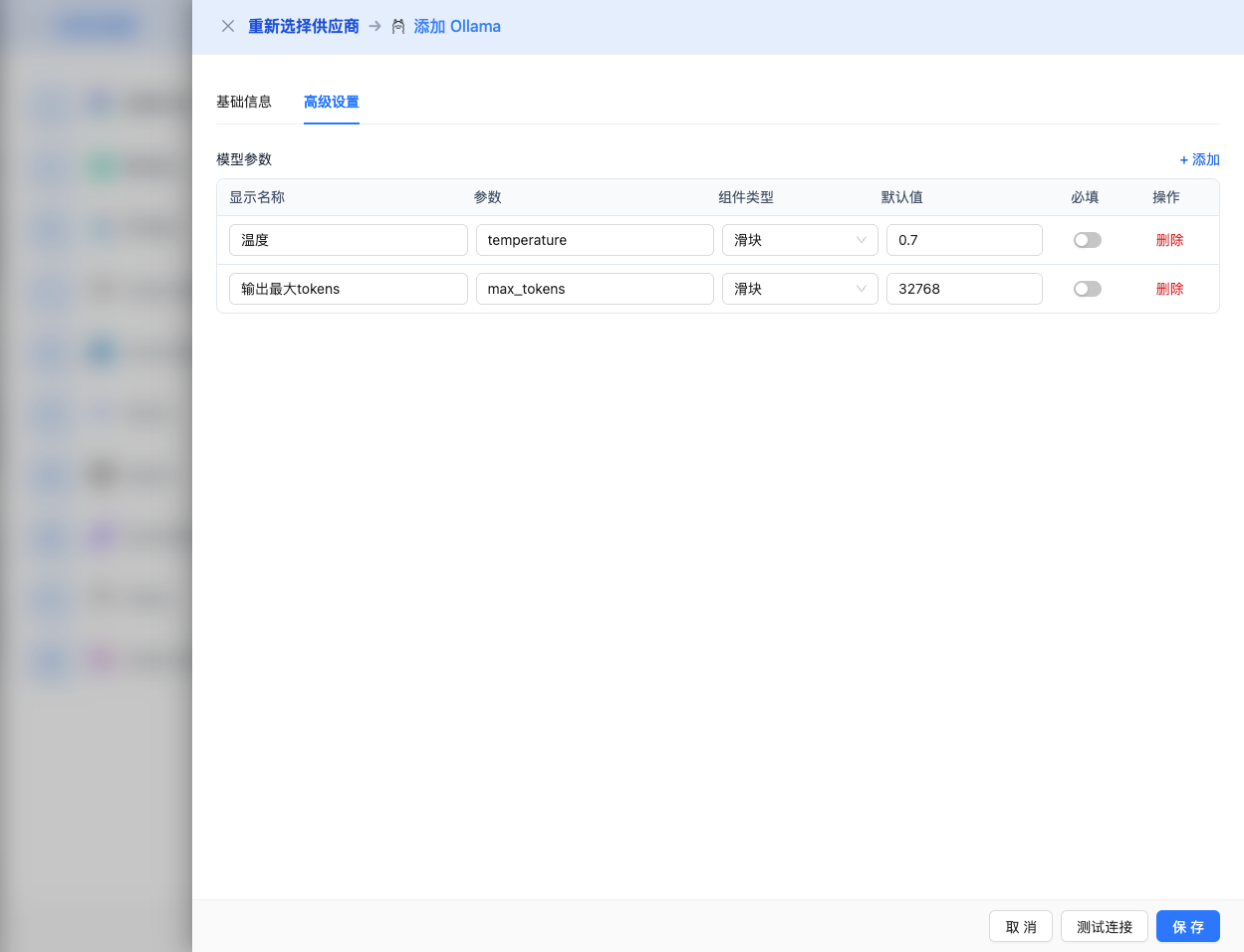
展开 高级配置 面板,可以调整以下参数:
CueMate 界面可调参数:
温度(temperature):控制输出随机性
- 范围:0-2
- 推荐值:0.7
- 作用:值越高输出越随机创新,值越低输出越稳定保守
- 使用建议:
- 创意写作/头脑风暴:1.0-1.5
- 常规对话/问答:0.7-0.9
- 代码生成/精确任务:0.3-0.5
输出最大 tokens(max_tokens):限制单次输出长度
- 范围:256 - 32768(根据模型而定)
- 推荐值:8192
- 作用:控制模型单次响应的最大字数
- 使用建议:
- 简短问答:1024-2048
- 常规对话:4096-8192
- 长文生成:16384-32768
Ollama API 支持的其他高级参数:
虽然 CueMate 界面只提供 temperature 和 max_tokens 调整,但如果你通过 API 直接调用 Ollama,还可以使用以下高级参数(Ollama 采用 OpenAI 兼容的 API 格式):
top_p(nucleus sampling)
- 范围:0-1
- 默认值:1
- 作用:从概率累积达到 p 的最小候选集中采样
- 与 temperature 的关系:通常只调整其中一个
- 使用建议:
- 保持多样性但避免离谱:0.9-0.95
- 更保守的输出:0.7-0.8
top_k
- 范围:0-100
- 默认值:40
- 作用:从概率最高的 k 个候选词中采样
- 使用建议:
- 更多样化:50-100
- 更保守:10-30
frequency_penalty(频率惩罚)
- 范围:-2.0 到 2.0
- 默认值:0
- 作用:降低重复相同词汇的概率(基于词频)
- 使用建议:
- 减少重复:0.3-0.8
- 允许重复:0(默认)
presence_penalty(存在惩罚)
- 范围:-2.0 到 2.0
- 默认值:0
- 作用:降低已出现过的词汇再次出现的概率(基于是否出现)
- 使用建议:
- 鼓励新话题:0.3-0.8
- 允许重复话题:0(默认)
stop(停止序列)
- 类型:字符串或数组
- 默认值:null
- 作用:当生成内容包含指定字符串时停止
- 示例:
["###", "用户:", "\n\n"] - 使用场景:
- 结构化输出:使用分隔符控制格式
- 对话系统:防止模型代替用户说话
stream(流式输出)
- 类型:布尔值
- 默认值:false
- 作用:启用 SSE 流式返回,边生成边返回
- CueMate 中:自动处理,无需手动设置
seed(随机种子)
- 类型:整数
- 默认值:null
- 作用:固定随机种子,相同输入产生相同输出
- 使用场景:
- 可复现的测试
- 对比实验
| 序号 | 场景 | temperature | max_tokens | top_p | top_k | frequency_penalty | presence_penalty |
|---|---|---|---|---|---|---|---|
| 1 | 创意写作 | 1.0-1.2 | 4096-8192 | 0.95 | 50 | 0.5 | 0.5 |
| 2 | 代码生成 | 0.2-0.5 | 2048-4096 | 0.9 | 40 | 0.0 | 0.0 |
| 3 | 问答系统 | 0.7 | 1024-2048 | 0.9 | 40 | 0.0 | 0.0 |
| 4 | 摘要总结 | 0.3-0.5 | 512-1024 | 0.9 | 30 | 0.0 | 0.0 |
| 5 | 头脑风暴 | 1.2-1.5 | 2048-4096 | 0.95 | 60 | 0.8 | 0.8 |
2.5 测试连接
填写完配置后,点击 测试连接 按钮,验证配置是否正确。
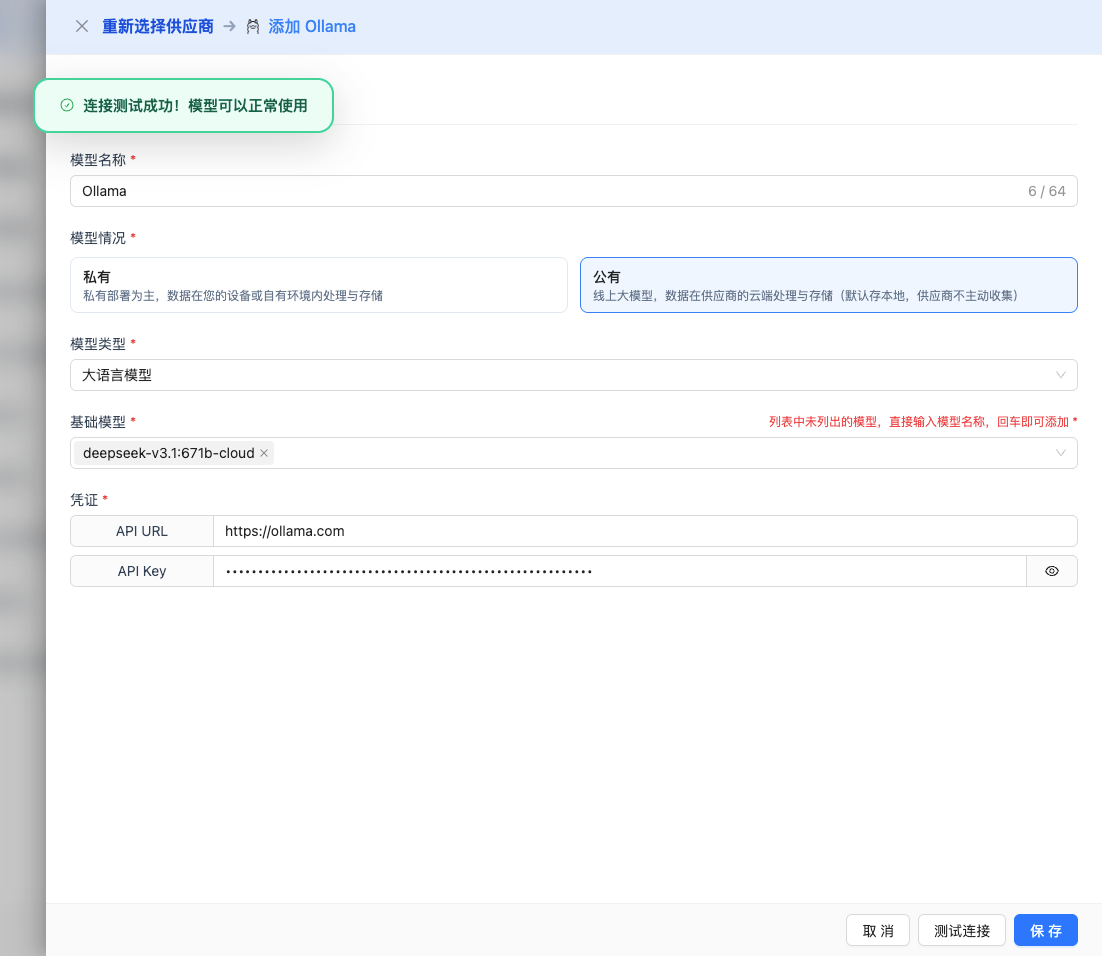
如果配置正确,会显示测试成功的提示,并返回模型的响应示例。
如果配置错误,会显示测试错误的日志,并且可以通过日志管理,查看具体报错信息。
2.6 保存配置
测试成功后,点击 保存 按钮,完成模型配置。
3. 使用模型
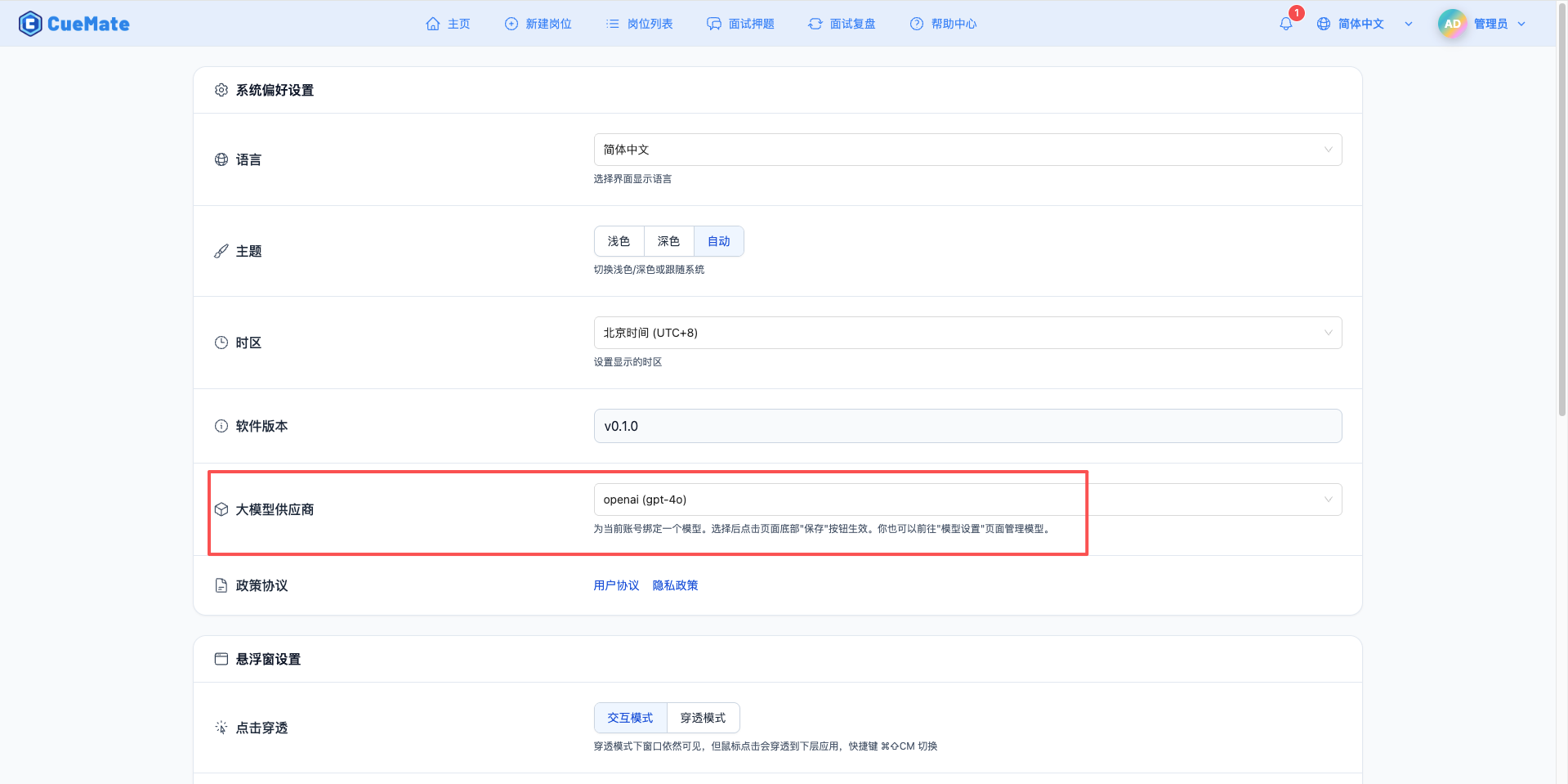
通过右上角下拉菜单,进入系统设置界面,在大模型服务商栏目选择想要使用的模型配置。
配置完成后,可以在面试训练、问题生成等功能中选择使用此模型, 当然也可以在面试的选项中单此选择此次面试的模型配置。
4. 支持的模型列表
4.1 云端模型(Cloud Models)
| 序号 | 模型名称 | 模型 ID | 参数量 | 特点 |
|---|---|---|---|---|
| 1 | GPT-OSS 120B Cloud | gpt-oss:120b-cloud | 120B | 开源 GPT 云端版 |
| 2 | GPT-OSS 20B Cloud | gpt-oss:20b-cloud | 20B | 开源 GPT 云端版 |
| 3 | DeepSeek V3.1 | deepseek-v3.1:671b-cloud | 671B | 超大规模推理模型 |
| 4 | Qwen3 Coder | qwen3-coder:480b-cloud | 480B | 代码生成专用 |
| 5 | Qwen3 VL | qwen3-vl:235b-cloud | 235B | 视觉语言模型 |
| 6 | MiniMax M2 | minimax-m2:cloud | - | MiniMax 云端模型 |
| 7 | GLM-4.6 | glm-4.6:cloud | - | 智谱 GLM 最新版 |
4.2 本地模型(Local Models)
GPT-OSS 系列
| 序号 | 模型名称 | 模型 ID | 参数量 | 适用场景 |
|---|---|---|---|---|
| 1 | GPT-OSS 120B | gpt-oss:120b | 120B | 开源 GPT 超大模型 |
| 2 | GPT-OSS 20B | gpt-oss:20b | 20B | 开源 GPT 中型模型 |
Gemma 3 系列(Google)
| 序号 | 模型名称 | 模型 ID | 参数量 | 适用场景 |
|---|---|---|---|---|
| 1 | Gemma3 27B | gemma3:27b | 27B | Google 最新旗舰模型 |
| 2 | Gemma3 12B | gemma3:12b | 12B | 中等规模任务 |
| 3 | Gemma3 4B | gemma3:4b | 4B | 轻量级任务 |
| 4 | Gemma3 1B | gemma3:1b | 1B | 超轻量级 |
DeepSeek R1 系列
| 序号 | 模型名称 | 模型 ID | 参数量 | 适用场景 |
|---|---|---|---|---|
| 1 | DeepSeek R1 8B | deepseek-r1:8b | 8B | 推理增强 |
Qwen 3 系列
| 序号 | 模型名称 | 模型 ID | 参数量 | 适用场景 |
|---|---|---|---|---|
| 1 | Qwen3 Coder 30B | qwen3-coder:30b | 30B | 代码生成 |
| 2 | Qwen3 VL 30B | qwen3-vl:30b | 30B | 视觉语言 |
| 3 | Qwen3 VL 8B | qwen3-vl:8b | 8B | 视觉语言 |
| 4 | Qwen3 VL 4B | qwen3-vl:4b | 4B | 视觉语言 |
| 5 | Qwen3 30B | qwen3:30b | 30B | 通用对话 |
| 6 | Qwen3 8B | qwen3:8b | 8B | 通用对话 |
| 7 | Qwen3 4B | qwen3:4b | 4B | 轻量级任务 |
5. 常见问题
5.1 Ollama 服务未启动
现象:测试连接时提示连接失败
解决方案:
- 确认 Ollama 服务是否运行:
ollama list - 重启 Ollama 服务
- 检查端口 11434 是否被占用:
lsof -i :11434
5.2 模型未下载
现象:提示模型不存在
解决方案:
- 使用
ollama list查看已下载的模型 - 使用
ollama pull <model-name>下载模型 - 确认模型名称拼写正确
5.3 性能问题
现象:模型响应速度慢
解决方案:
- 选择参数量较小的模型(如 7B 而非 70B)
- 确保有足够的 GPU 内存或系统内存
- 检查系统资源使用情况
5.4 API URL 错误
现象:无法连接到 Ollama 服务
解决方案:
- 确认 API URL 配置正确(默认 http://localhost:11434)
- 如果 Ollama 运行在 Docker 中,使用容器的内部地址
- 检查防火墙设置
5.5 模型选择
- 开发测试:使用 7B-14B 参数的模型,响应快,资源消耗低
- 生产环境:根据性能需求选择 14B-32B 参数的模型
- 资源受限:使用 0.5B-3B 参数的轻量级模型
5.6 硬件要求
| 模型参数 | 最小内存 | 推荐内存 | GPU |
|---|---|---|---|
| 0.5B-3B | 4GB | 8GB | 可选 |
| 7B-14B | 8GB | 16GB | 推荐 |
| 32B-70B | 32GB | 64GB | 必需 |