
配置腾讯云知识引擎原子能力
腾讯云知识引擎(LKE)是腾讯云推出的企业级 AI 服务平台,提供 DeepSeek-V3 系列模型的 API 接入服务。支持超大规模参数(685B)、混合推理、稀疏注意力等先进技术,适用于复杂推理、代码生成、长文本处理等场景。
1. 开通知识引擎服务并获取 API Key
1.1 访问知识引擎控制台
访问腾讯云知识引擎原子能力控制台并登录:https://console.cloud.tencent.com/lke
1.2 开通智能体开发平台
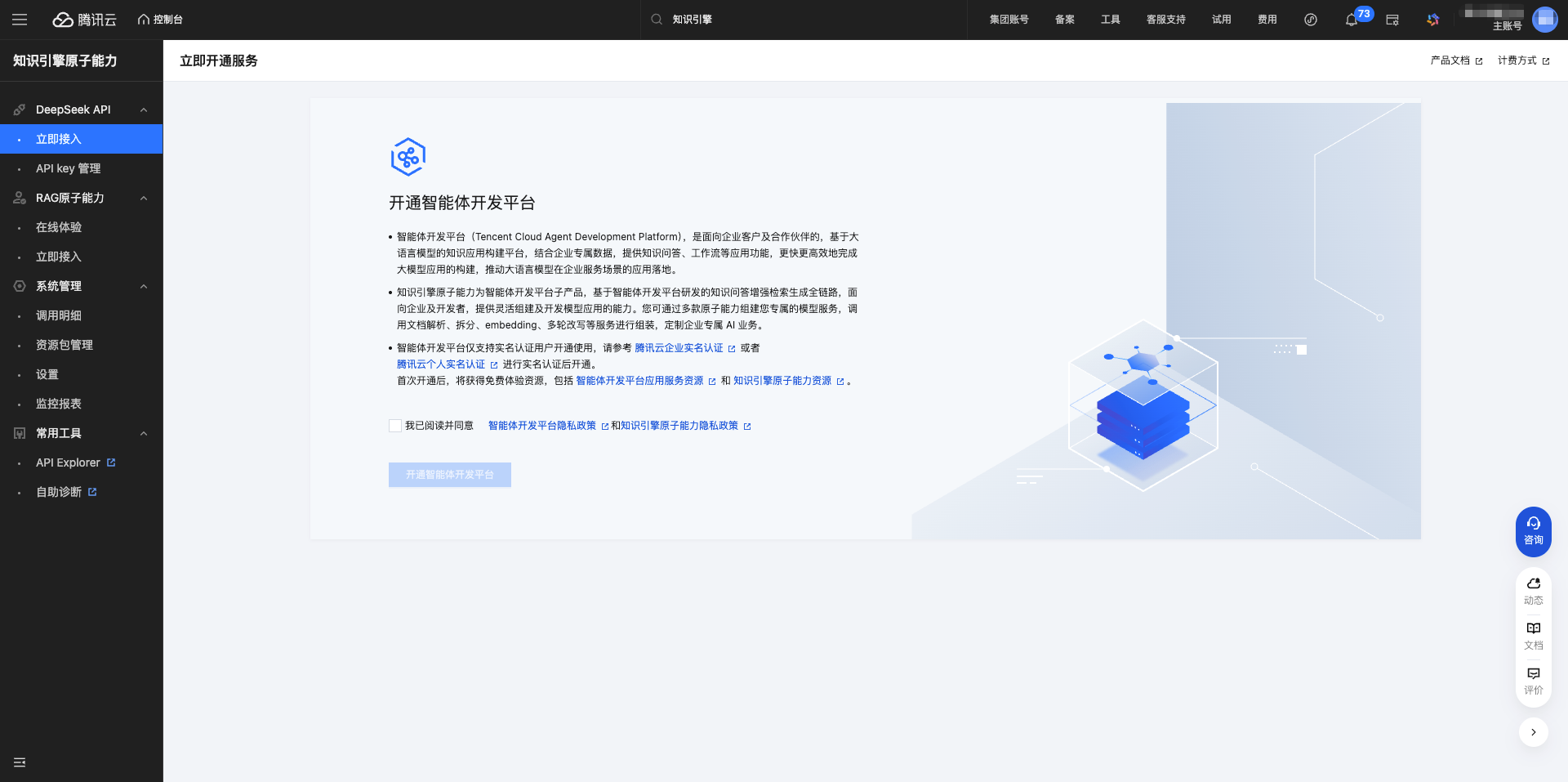
登录后,点击左侧菜单的 DeepSeek API → 立即接入,进入服务开通页面。
点击 开通智能体开发平台 按钮。
1.3 进入 API KEY 管理
服务开通后,点击左侧菜单的 API KEY 管理。
1.4 创建 API Key
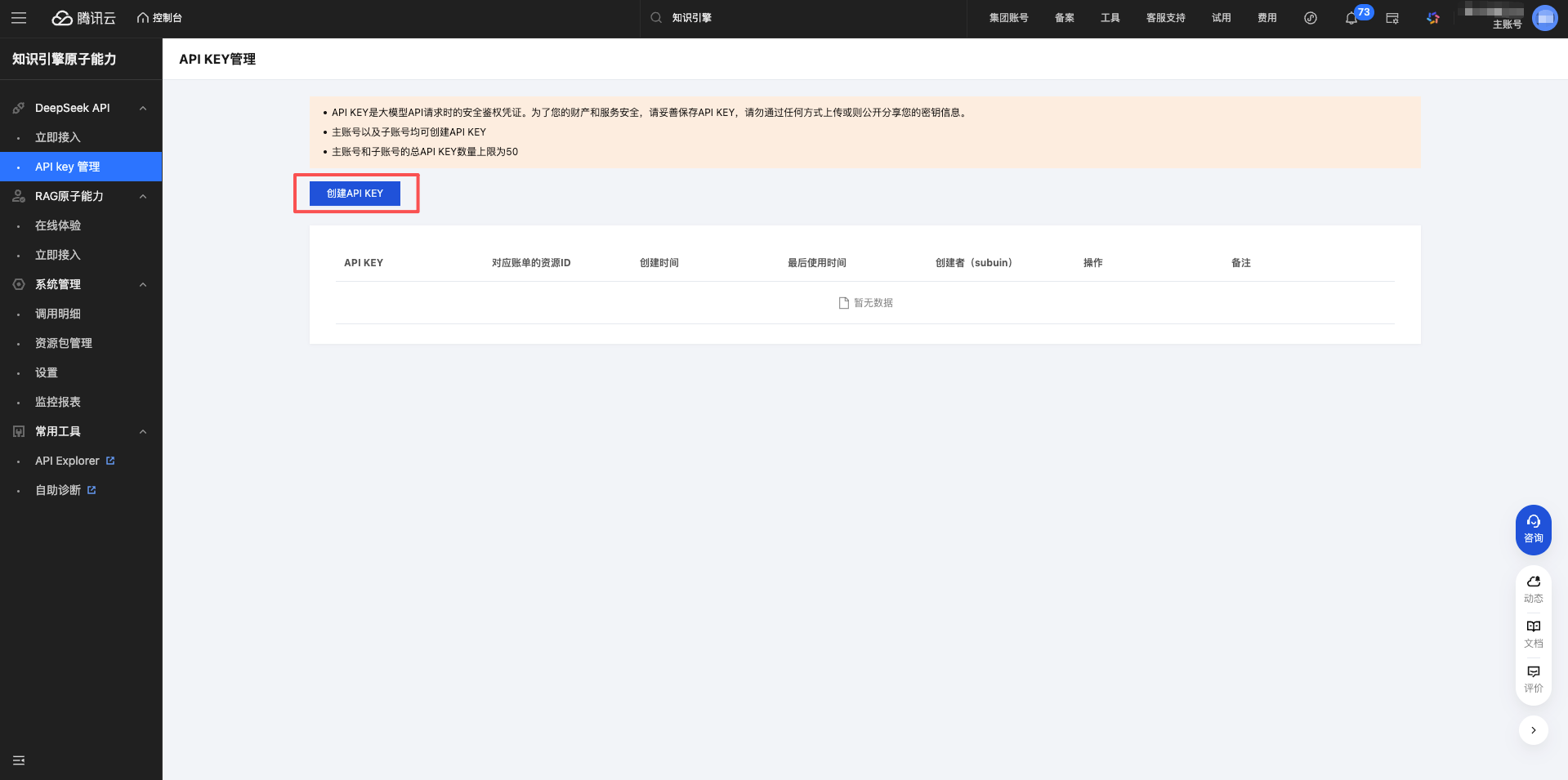
点击 创建 API KEY 按钮。
1.5 复制 API Key
创建成功后,系统会显示 API Key。
重要:请立即复制并妥善保存,API Key 以 sk- 开头。
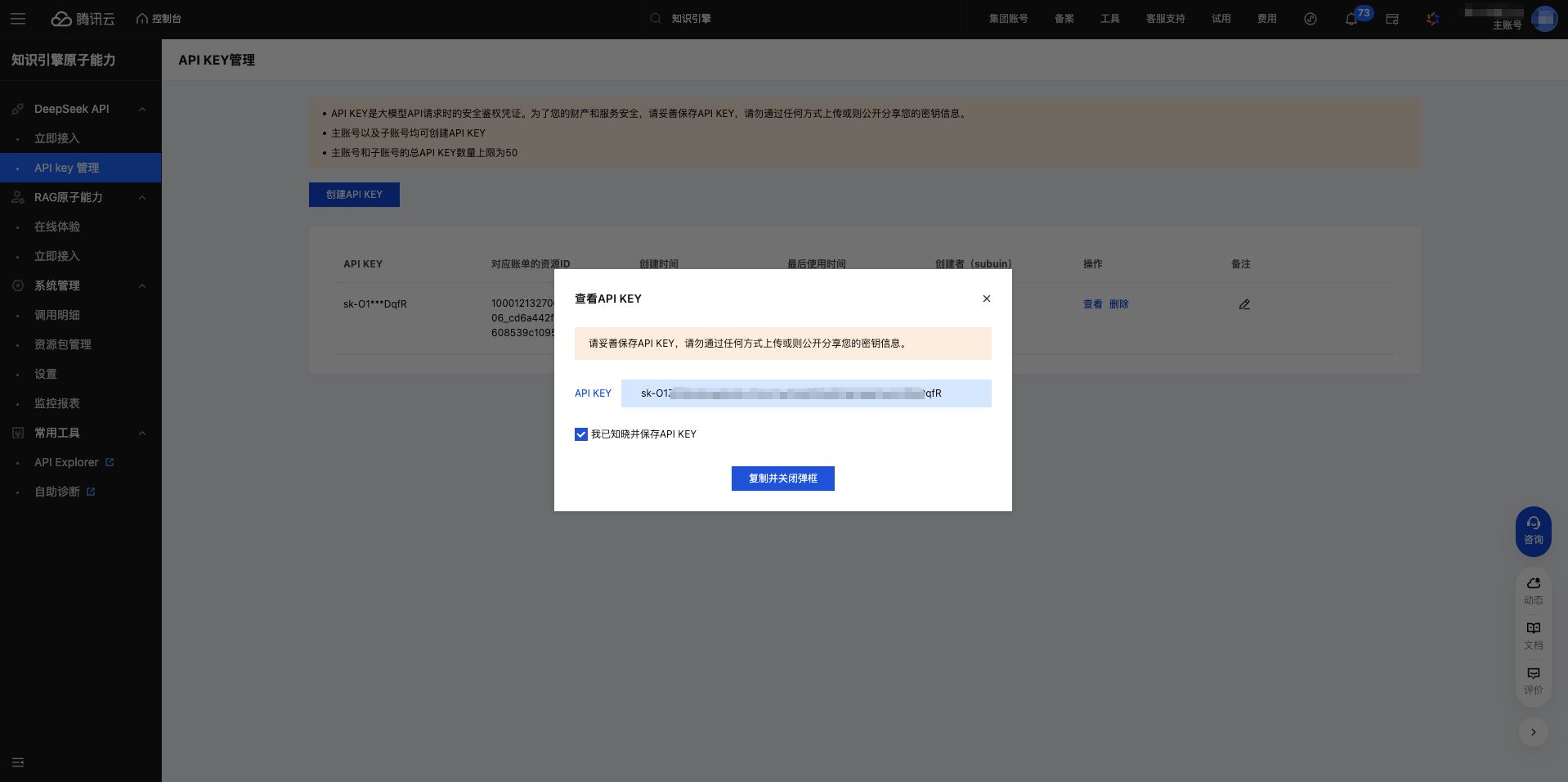
点击复制按钮,API Key 已复制到剪贴板。
2. 在 CueMate 中配置腾讯云知识引擎模型
2.1 进入模型设置页面
登录 CueMate 系统后,点击右上角下拉菜单的 模型设置。
2.2 添加新模型
点击右上角的 添加模型 按钮。

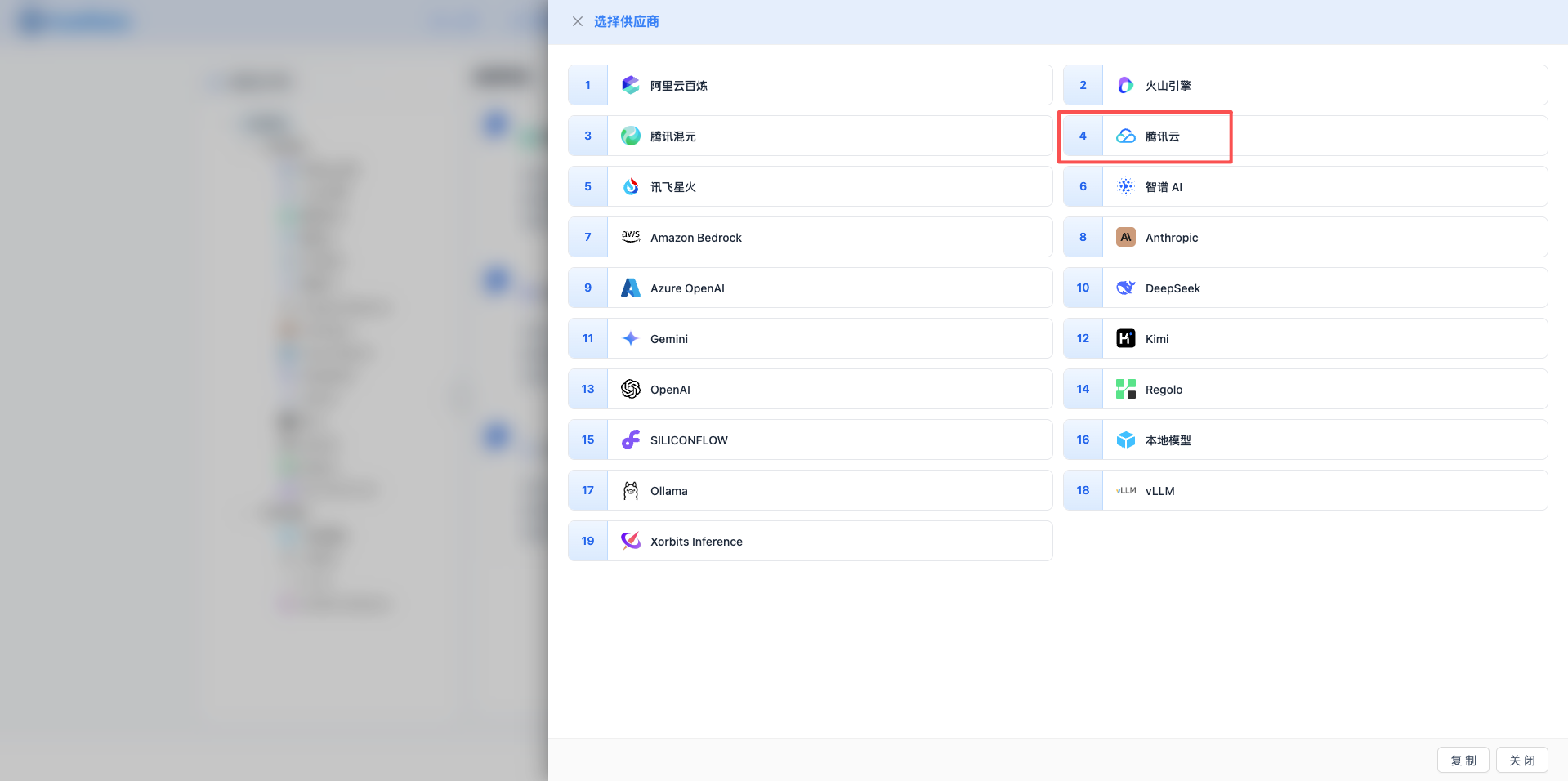
2.3 选择腾讯云知识引擎服务商
在弹出的对话框中:
- 服务商类型:选择 腾讯云知识引擎
- 点击后 自动进入下一步
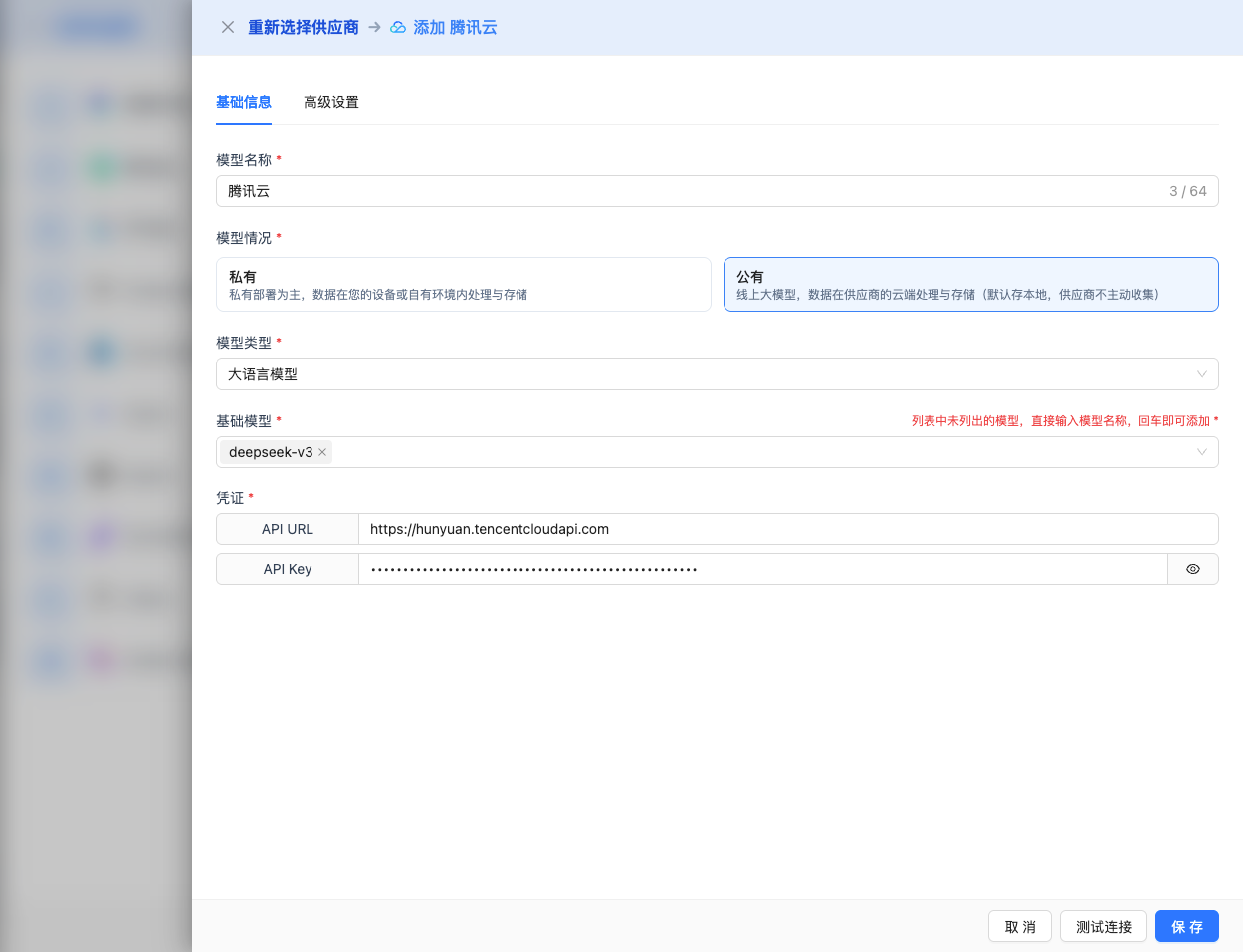
2.4 填写配置信息
在配置页面填写以下信息:
基础配置
- 模型名称:为这个模型配置起个名字(例如:DeepSeek-V3.1)
- API URL:保持默认
https://api.lkeap.cloud.tencent.com/v1(OpenAI 兼容格式) - API Key:粘贴刚才复制的 API Key
- 模型版本:选择要使用的模型ID,常用模型包括:
deepseek-v3.1:685B参数,最大输出32K,混合推理,适合复杂任务deepseek-v3.1-terminus:685B参数,最大输出32K,优化语言一致性deepseek-v3.2-exp:685B参数,最大输出64K推理,稀疏注意力机制deepseek-r1-0528:671B参数,最大输出16K,增强代码生成和长文本处理deepseek-r1:671B参数,最大输出16K,推理模型,适合数学和复杂逻辑deepseek-v3-0324:671B参数,最大输出16K,128K上下文,强编程能力deepseek-v3:671B参数,最大输出16K,64K上下文,通用知识和数学推理
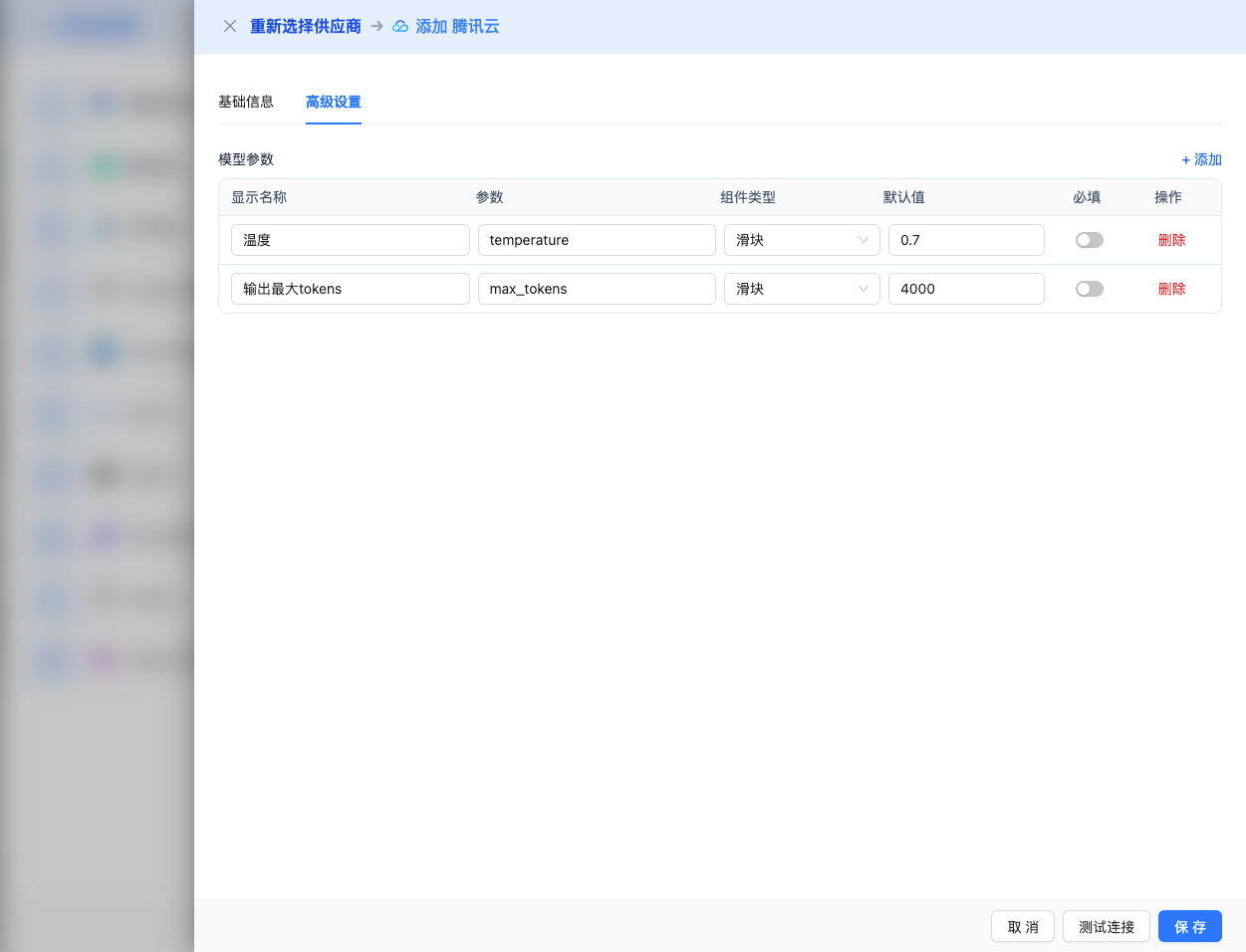
高级配置(可选)
展开 高级配置 面板,可以调整以下参数:
CueMate 界面可调参数:
温度(temperature):控制输出随机性
- 范围:0-2
- 推荐值:0.7
- 作用:值越高输出越随机创新,值越低输出越稳定保守
- 使用建议:
- 创意写作/头脑风暴:1.0-1.5
- 常规对话/问答:0.7-0.9
- 代码生成/精确任务:0.3-0.5
输出最大 tokens(max_tokens):限制单次输出长度
- 范围:256 - 64000(根据模型而定)
- 推荐值:8192
- 作用:控制模型单次响应的最大字数
- 模型限制:
- deepseek-v3.1/v3.1-terminus:最大 32K tokens
- deepseek-v3.2-exp:最大 64K tokens(推理模式)
- deepseek-r1/r1-0528:最大 16K tokens
- deepseek-v3/v3-0324:最大 16K tokens
- 使用建议:
- 简短问答:1024-2048
- 常规对话:4096-8192
- 长文生成:16384-32768
- 超长推理:65536(仅 v3.2-exp)
腾讯云知识引擎 API 支持的其他高级参数:
虽然 CueMate 界面只提供 temperature 和 max_tokens 调整,但如果你通过 API 直接调用腾讯云知识引擎,还可以使用以下高级参数(采用 OpenAI 兼容的 API 格式):
top_p(nucleus sampling)
- 范围:0-1
- 默认值:1
- 作用:从概率累积达到 p 的最小候选集中采样
- 与 temperature 的关系:通常只调整其中一个
- 使用建议:
- 保持多样性但避免离谱:0.9-0.95
- 更保守的输出:0.7-0.8
frequency_penalty(频率惩罚)
- 范围:-2.0 到 2.0
- 默认值:0
- 作用:降低重复相同词汇的概率(基于词频)
- 使用建议:
- 减少重复:0.3-0.8
- 允许重复:0(默认)
presence_penalty(存在惩罚)
- 范围:-2.0 到 2.0
- 默认值:0
- 作用:降低已出现过的词汇再次出现的概率(基于是否出现)
- 使用建议:
- 鼓励新话题:0.3-0.8
- 允许重复话题:0(默认)
stop(停止序列)
- 类型:字符串或数组
- 默认值:null
- 作用:当生成内容包含指定字符串时停止
- 示例:
["###", "用户:", "\n\n"] - 使用场景:
- 结构化输出:使用分隔符控制格式
- 对话系统:防止模型代替用户说话
stream(流式输出)
- 类型:布尔值
- 默认值:false
- 作用:启用 SSE 流式返回,边生成边返回
- CueMate 中:自动处理,无需手动设置
| 序号 | 场景 | temperature | max_tokens | top_p | frequency_penalty | presence_penalty |
|---|---|---|---|---|---|---|
| 1 | 创意写作 | 1.0-1.2 | 4096-8192 | 0.95 | 0.5 | 0.5 |
| 2 | 代码生成 | 0.2-0.5 | 2048-4096 | 0.9 | 0.0 | 0.0 |
| 3 | 问答系统 | 0.7 | 1024-2048 | 0.9 | 0.0 | 0.0 |
| 4 | 摘要总结 | 0.3-0.5 | 512-1024 | 0.9 | 0.0 | 0.0 |
| 5 | 复杂推理 | 0.7 | 32768-65536 | 0.9 | 0.0 | 0.0 |
2.5 测试连接
填写完配置后,点击 测试连接 按钮,验证配置是否正确。
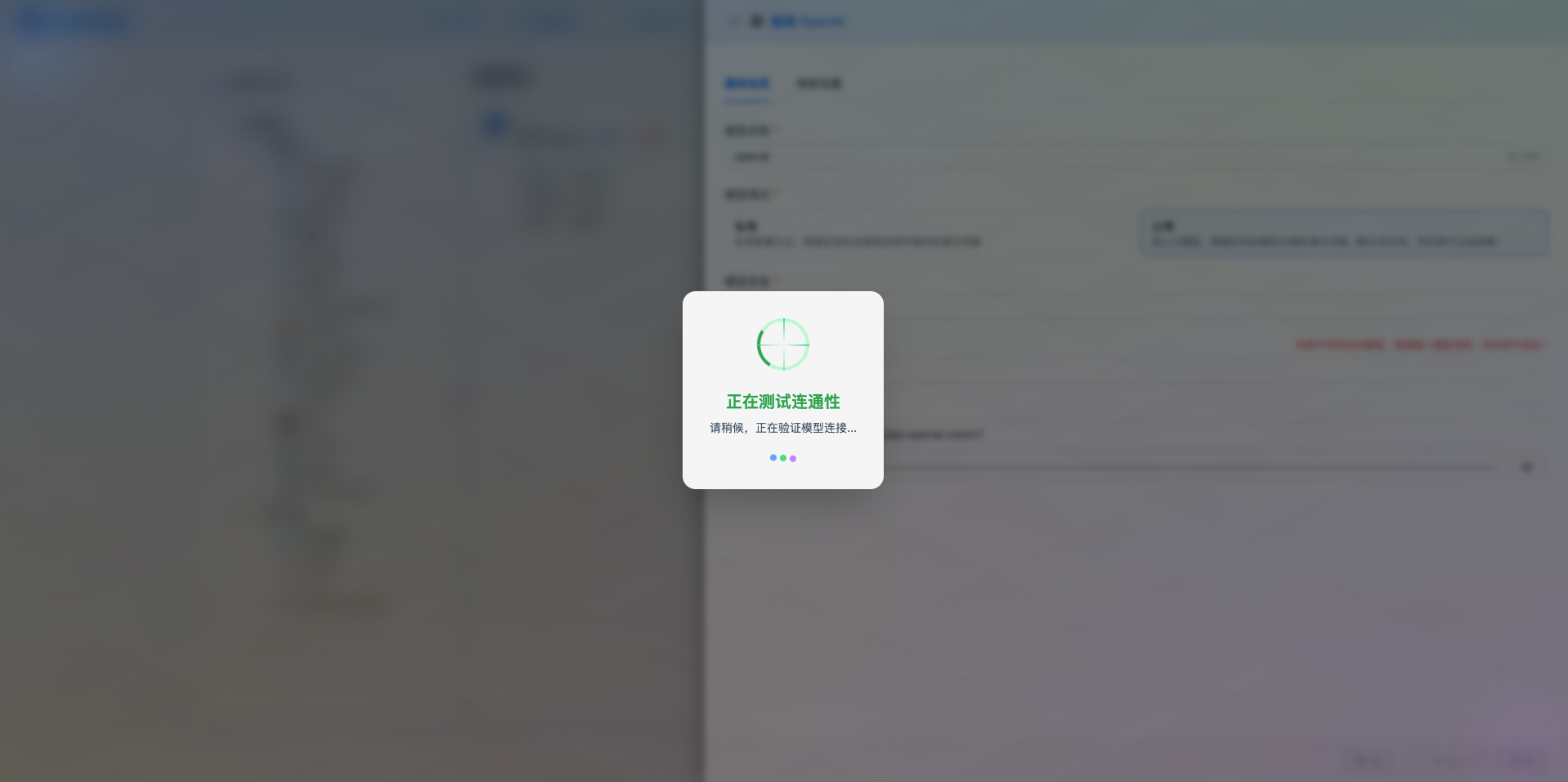
如果配置正确,会显示测试成功的提示,并返回模型的响应示例。
如果配置错误,会显示测试错误的日志,并且可以通过日志管理,查看具体报错信息。
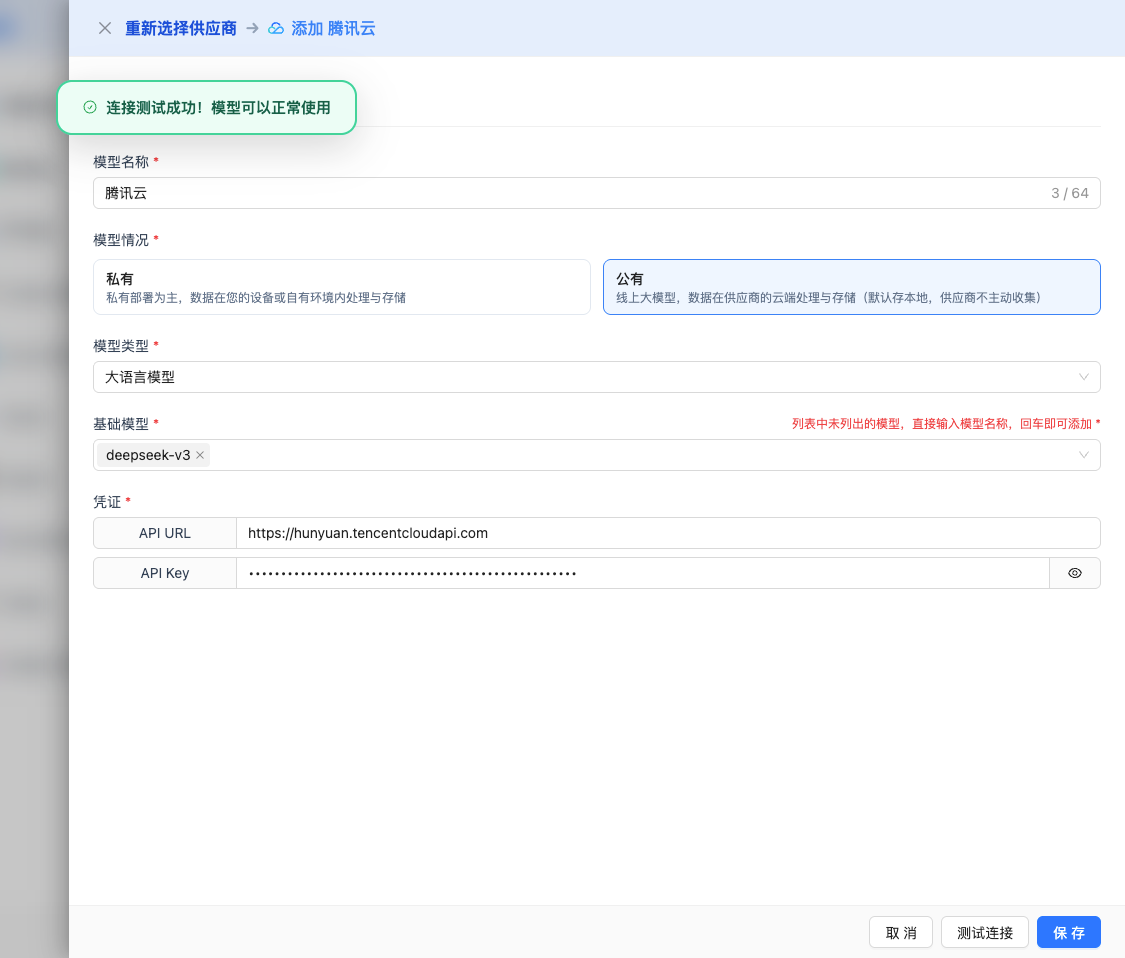
2.6 保存配置
测试成功后,点击 保存 按钮,完成模型配置。
3. 使用模型
通过右上角下拉菜单,进入系统设置界面,在大模型服务商栏目选择想要使用的模型配置。
配置完成后,可以在面试训练、问题生成等功能中选择使用此模型,当然也可以在面试的选项中单独选择此次面试的模型配置。
4. 支持的模型列表
4.1 685B参数模型(最新)
| 序号 | 模型名称 | 模型 ID | 最大输出 | 适用场景 |
|---|---|---|---|---|
| 1 | DeepSeek-V3.1 | deepseek-v3.1 | 32K tokens | 混合推理、Agent能力、复杂任务 |
| 2 | DeepSeek-V3.1-Terminus | deepseek-v3.1-terminus | 32K tokens | 优化语言一致性、Agent稳定性 |
| 3 | DeepSeek-V3.2-Exp | deepseek-v3.2-exp | 64K tokens(推理) | 稀疏注意力、长文本优化 |
4.2 671B参数模型
| 序号 | 模型名称 | 模型 ID | 最大输出 | 适用场景 |
|---|---|---|---|---|
| 1 | DeepSeek-R1-0528 | deepseek-r1-0528 | 16K tokens | 增强代码生成、长文本处理、复杂推理 |
| 2 | DeepSeek-R1 | deepseek-r1 | 16K tokens | 数学、代码、复杂逻辑推理任务 |
| 3 | DeepSeek-V3-0324 | deepseek-v3-0324 | 16K tokens | 编程与技术能力、128K上下文 |
| 4 | DeepSeek-V3 | deepseek-v3 | 16K tokens | 通用知识、数学推理、64K上下文 |
5. 常见问题
5.1 API Key无效
现象:测试连接时提示 API Key 错误
解决方案:
- 检查 API Key 是否以
sk-开头 - 确认 API Key 完整复制
- 检查账户是否有可用额度
- 验证 API Key 未过期或被禁用
5.2 请求超时
现象:测试连接或使用时长时间无响应
解决方案:
- 检查网络连接是否正常
- 确认 API URL 地址正确:
https://api.lkeap.cloud.tencent.com/v1 - 检查防火墙设置
5.3 模型不可用
现象:提示模型服务不可用
解决方案:
- 确认选择的模型ID正确
- 检查账户是否开通了知识引擎原子能力服务
- 联系腾讯云客服确认服务状态
5.4 配额限制
现象:提示超出请求配额
解决方案:
- 登录腾讯云控制台查看配额使用情况
- 申请提高配额限制(API频率限制为20次/秒)
- 优化使用频率